Mentor - Philippe Ombredanne
This project aims to solve and improve the accuracy of following tasks:
- Programming Language Classification
- File Purpose Classification
Various techniques were explored. The method proposed below is lightweight, yet accurate.
Name: Mankaran Singh
Major: Computer Science And Engineering
Institute: Thapar Institute of Engineering and Technology, Patiala.
Github: @MankaranSingh
Email: mankaran32@gmail.com
LinkedIn: https://www.linkedin.com/in/mankaran32/
Phone: (+91) 9872901791
Postal Address: 2206, Krishna Nagar, Civil Lines, Ludhiana, Punjab, India
Timezone: Indian Standard Time (UTC +5:30)
-
The current methods of programming language classification (like linguists, pygments) rely heavily on custom handcrafted rules for many of it's classification tasks. Although handcrafted rules do a good job making file-level language predictions, its performance declines considerably when files use unexpected naming conventions and, crucially, when a file extension is not provided. Handcrafting rules brings along some major problems with it :
- Less accuracy.
- Easily fails on edge cases.
- Requires fair amount of time in manually thinking and implementing rules.
- Adding a new language in database for classification not so easy.
File names and extensions, while providing a good indication of what the coding language is likely to be, do not offer the full picture. Machine learning algorithms are widely used for automating the process of handcrafting rules and may surpass the performance and accuracy for a given task. A machine learning model would rather learn the vocabulary of various languages (like humans do) to classify the programming language. Machine Learning algorithms are widely used in Language Processing tasks and have surpassed the performance of conventional approaches in good amount of cases . This approach can work from file level or snippet level to potentially line-level language detection and classification.
Accurate classification of programming language is an important task as :
- It would be easier to extract information about which other libraries and frameworks are imported, as our search has been narrowed down to a specific programming language.
- Easier security vulnerability alerting
- Accurate picture about the % ages of programming languages used for a project.
- More relevant information extraction from text file in context of programming language.
- More accurately determining the purpose of a file.
- And possibly, many others.
Even GitHub has agreed to the fact that their current solution of programming language detection 'Linguist' isn't that accurate and fails miserably when files use unexpected naming conventions and, crucially, when a file extension is not provided.
-
A certain project consists of many files that can be categorized into following categories:
- Test files
- Documentation files
- Configuration files
- Build scripts
- Example Scripts
- Core Code
- Others (to be discussed)
This is important because, for example, the license of core code may be more important than the license of test code, example code, etc. Classifying the files into these help us to prioritize and emphasize on the licenses of certain categories. This is similar to the concept of "facets" from the Clearly Defined project. Different techniques to accomplish this task (including machine learning) would be discussed below.
Note: All thing things written below have been verified and performed in the following notebook: The Dataset used in the notebook is not the one specified here.
Machine learning is replacing conventional methods of solving a specific problem but one cannot 'just replace' the conventional methods with some fancy machine learning algorithms the reason being:
- Machine learning may be computationally expensive.
- Inference time of machine learning algorithms may be larger than conventional algorithms.
- The size of a machine learning model may be huge, ultimately increasing the size of the project.
Now, using machine learning instead of existing conventional approaches is viable only if:
- There are large gains upon accuracy over conventional approaches.
- The developed machine learning solution is not very computationally expensive and runs fast.
- The solution is easy to integrate into the existing workflow.
- The solution is easy to distribute, maintain and is flexible.
From my research, i have found that using machine learning for this use case is a viable option.
GitHub is moving from it's existing solution 'Linguist' to a machine learning based solution named as 'OctoLingua' - source The following results were obtained using OctoLingua. We can see that OctoLingua maintains a good performance under various conditions, suggesting that the model learns primarily from the vocabulary of the code, rather than from meta information (i.e. file extension), whereas Linguist fails as soon as the information on file extensions is altered.

The above results seem very impressive. But OctoLigua uses tensorflow/keras and these libraries are too heavy, large in size and difficult to install. We need a similar lightweight classifier (Random Forest, SVM, Naive Bayes, etc) that is both accurate and lightweight.
For programming language classification task, the Rosetta Code website is a great place to obtain the data-set. This contains huge amounts of code written in various programming languages (way more than what we need). The quality of data is high. Initially, I wrote a scraping script to scrape all the code snippets from the site, it was an easy task, but a bit time-consuming. So, I talked to the admins of the site and they let me have a full copy of all the code data on their site. The data is well structured. This data should be enough for our task. But still if there is an imbalance in the data for some languages, we can easily fetch more data from GitHub.
First of all, all the text would be chunked into pieces to obtain uniform length code snippets and for the reason that our model would run faster if we train it to make inferences on smaller pieces of text.
snippets = []
content = 'code goes here'
chunk_size = 2048
for chunk in range(0, len(content), chunk_size):
snippet = content[chunk : chunk + chunk_size]
snippets.append(snippet)The next step is to convert the text into lower case and remove all the special characters.
I have experimented with different pre-processing techniques and found that it was better to remove all the special characters because of the following reasons: Examine the following code snippet:
class Example:
def __init__(self, x, y):
self.x = x
self.y = yIf we tokenize them based on white spaces, we will obtain following tokens:
['class', 'Example:', 'def', .... 'self.x', 'self.y', 'self,']
note that 'self.x', 'self.y', 'self,' are treated as different token even though these tokens almost mean the same thing. A conventional ML model (like SVM, Random forest) may get troubled by this. Therefore it is necessary to replace all special characters by white spaces, so we will obtain:
['class', 'Example', 'def', .... 'self'] which makes much more sense.
After that, we count the occurrence of each token and apply the following filters:
min_occurane = 5 # Min number of times a word should be present in the dataset.
tokens = [k for k,c in vocab.items() if c >= min_occurane]
# Remove the tokens which appear less
# than 5 times in the data-set since they are not much informative
forbidden = ['copyright', 'ibm', 'corp', 'licensed', 'you', 'apache',
'license', 'licenses', 'org', 'compliance']
# remove some tokens that are present in the 'licence/copyright text' above the code.
tokens = [word for word in tokens if word not in forbidden]
tokens = [word for word in tokens if len(word) > 1]
# remove single letter words like 'a', 'b', '1', 'e', etc.
tokens = [word for word in tokens if not word.isnumeric()] # remove numbers Now, we need to vectorize the tokens, there are certain techniques like Doc2Vec, Word2Vec, Term Frequency, TF-IDF (Term Frequency–Inverse Document Frequency) .
I chose TF-IDF since it is lightweight and performs well over domain specific tasks. TF-IDF is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
Finally, along with text, the file extension would also be fed into the model for training but with a twist - 50 % of the samples would contain incorrect/random extensions so that the model learns more from the vocabulary rather than meta-data as explained in the OctoLingua blog post. This would make the model very accurate in real life setting ! (The models in notebook were trained without any file extensions)
This concludes the pre-processing steps.
I trained three models in the notebook:
- Deep Convolutional Neural Network
- XGBoost Classifier
- Random Forest Classifier
The following results were obtained:
| Model Type | Accuracy | Inference time (over many files) |
|---|---|---|
| Deep Convolutional Net | 0.9844 | 0.219 s |
| XGBoost | 0.9775 | 0.209 s |
| Random Forest | 0.9863 | 0.193 s |
| Pygments | 0.2666 | 0.297 s |
We can clearly see that machine learning is clearly a better option over pygments.
I think we should avoid using deep learning (OctoLingua, tensorflow based models, etc.) because of the following reason:
Here, the deep learning model, XGboost + TF-IDF and the Random Forest + TF-IDF models perform almost similar. If we use deep learning models, we would have to add tensorflow and keras as a dependency.The Tensorflow package is well over 500 MB and is an overkill for this project as a dependency in my oppinion. On the other hand, the conventional models require only sci-kitlearn and xgboost library which are far more lightweight and easy to install on all operating systems. The deep learning model may outperform other models given huge amount of data. But our tasks of programming anguage classification dosen't seem to be too complex and is fairly modeled by these models.
Therefore, it is necessary to create a classifier that is tailored to the scancode's needs i.e. being lightweight, more precise, etc. Existing projects do not provide any flexibility for this.
The files can be classified into the following categories:
- Test files
- Documentation files
- Configuration files
- Build scripts
- Example Scripts
- Core Code
- Others (to be discussed)
Since many of the project structures are similar, one may think of adding an automatic file classifier.
Each of the files belonging to any of the above category has certain characteristics associated with them, for example:
- Certain keywords in filename
- Certain keywords in file path
- Particular language libraries imported or not
- Ratio of certain keywords in file content vs total number of words for example - a high value of content.count('test')/len(count.split()) may indicate a test file.
- File extensions, etc
These features can be extracted in following ways:
def extract_features_from_files(paths):
filenames = []
test_in_filename = []
test_in_directory_path = []
test_word_count = []
assert_word_count = []
testing_library_imported_or_not = []
test_count_in_neighbouring_filenames = []
for path in paths:
try:
with open(path, encoding="utf8") as file:
content = file.read()
test_word_count.append(content.count('test'))
assert_word_count.append(content.count('assert'))
testing_library_imported_or_not.append('import pytest' in content)
except Exception as e:
print(path, e)
continue
filenames.append(os.path.basename(path))
test_in_filename.append('test' in os.path.basename(path))
test_in_directory_path.append('test' in os.path.dirname(path))
neighbours = os.listdir(os.path.dirname(path))
count = 0
for filename in neighbours:
if 'test' in filename:
count += 1
test_count_in_neighbouring_filenames.append(count)Note: This is only for 'test' file classification, features for other types can be extracted in a similar way.
My solution is to extract these features from each file and run them through a model for classification.
The results can be found in the following Notebook
The following features were extracted extracted from each file and were used to train a simple SVM classifier to perform a binary classification of 'test vs non test' files.
The data-set was fairly easy to make and could be found in the repository .
Results - The model was very easily able to classify the given files. In-fact, the accuracy was almost 100 % indicating that this was an easy classification problem and may be solved via heuristic approach (writing handcrafted rules).
The choice is ours. The advantage of Machine learning is:
- No need of thinking and handcrafting rules, just provide some training examples.
The advantage of Handcrafting rules is:
- Greater flexibility as we can add our own rules without retraining anything.
Both approaches work, but the final conclusion can only be made after feedback from end-user and discussion with mentors. But nonetheless, both approaches would do the job.
We may also use a combination of both approaches like:
- Train a random forest model
- Extract the feature importances and the if-else decisions
- Use them to handcraft rules
For example, see the below image, it represents how important a particular feature is:
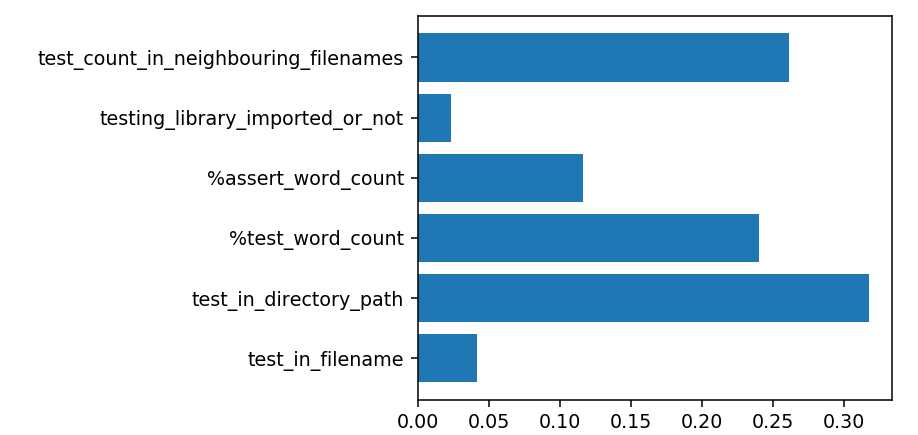
We can see, how important a particular feature is from modelling the current dummy data-set. Great insights, we can definitely keep these in mind while handcrafting rules.
False positives means that the model reports a specific file as something which it isn't, for example:
- Predicting a non test file as a test file
- Predicting a Matlab file as a JS/Python file
- And other similar cases
It would be a better thing if the model reports 'Can't Identify' rather than something wrong. Currently, methods like pygments do not provide us with any functionality like this.
This can be achieved by increasing the sensitivity of our model and making it more 'precise'. When a model is used to predict something, sci-kit learn provides us with predict_proba and decison_scores methods which returns the probability of the given sample for all classes it belongs to. The class with highest probability is selected.
What we can do is to set a thresh-hold value. So, a prediction would only be considered if the model returns a probability that is at-least greater than the thresh-hold value.
Therefore, we would only consider a prediction if the model is fairly confident about it, thus avoiding false positives.
- Scikit-learn (4.5 MB)
- SciPy (27 MB)
- NumPy (10 MB) (optional)
All these packages are very actively maintained and all of them are easily and commonly installed via a single-shot command 'pip install sklearn'. Python 3.x and 2.x are fully supported.
Avoiding tensorflow/keras since they are huge in size and not very easy to install. This will definitely not fit well for the scancode package.
If we still don't want to use any of the above mentioned dependencies, I can (and have) implement the above mentioned algorithms in pure python. See this and this, although, this may take some additional time for me to study and to use the best practices
- Python
- Machine Learning Libraries: XGBoost, Scikit-Learn (Final library would be selected based upon the best performing model)
- Beautiful Soup: For scraping data from web
- Fully clean and ready to use dataset for both the tasks.
- Well documented performance of various machine learning models for future reference.
- Best classifiers models for both the tasks.
- Integration of the classifiers into the codebase as plugins.
- Test cases covering each of the implemented feature
- Documentation
-
Pre GSoC : I'd focus on collecting the dataset required for training the model by scraping data from the internet. I'd also have make sure that the collected data is well balanced by analysing it though various data analytic techniques and would have to clean the dataset as required. This also makes my task easier in those 12 weeks and helps me concentrate on shipping professional code.
-
Community Bonding : Getting acquainted with the code base and the procedure that needs to be followed to submit code and get it reviewed. Discussing with the team on what exactly needs to be the problem statement (minute details, like kind of dataset we want to use, what parameters should be user choices, like parameters such as for training a newer model, adding a new programming language to the model, specifying a custom model prior to the scan, etc). Other than this, I have my final 2nd year University Exams from May 11 - May 23. But II'l try my best to give as much attention as possible to the community bonding period.
-
Week 1: Understand the relevant parts of the code base and try to figure out how the final product should look like, how these classifiers would be integrated into the existing workflow and what standards we need to follow,
-
Week 2: This week would be spent upon analyzing and collection of data from the internet. Data cleaning would also be done. Finally, a fully cleaned and structured data-set, for both programming language as well as file classification task that is ready to be fed to machine learning algorithms would be prepared by the end of this week.
-
Week 3 - 4: This week would be spent on training various types of models. A full report upon the performance of all the models (like inference times, model size, accuracy, ease of integration, etc) would be documented for future reference.
-
Week 5 - 6: Once the final models are selected, this week would be spent upon integration of these classifiers into the existing workflow.
-
Week 7: After the model integration, this week would be spent on writing various test cases based upon all the features that were integrated into the codebase in previous weeks.
-
Week 8 - 10: Take feedback from the community and iterate on the designs and improvise on use cases. Ensure code quality by adding more test cases
-
Week 10 - 11: Streamlining and standardizing the ways of training our own custom model if needed
-
Week 12: Documentation
-
Week 13 Spare week in case of some work getting delayed, in case of any emergency or otherwise.
-
Post GSoC: In my opinion, there are two types of statements:
- The logical statement “if A, then B” can be coded easily in any programming language
- The probabilistic statement “if A, then probably B” isn’t nearly as straightforward.
The AboutCode organisation has to deal with a large number of Type II statements, which is a difficult thing and I respect that. This project also belongs to Type II and some iterations may be required to get things right. I will keep on working upon improving the contributions that I will make throughout the project and will stay as an active member of the community.
-
I am a sophomore pursuing Computer Engineering at Thapar Institute, Patiala. My specialization is in the field of Machine Learning and Back-end Web/API Development. I have done an internship in a company named Hustlerpad Tech for developing production ready back-end API (Certificate on my LinkedIn). Most of the knowledge I have gained through is by reading quality books. I have been doing machine learning since past 2 years and am able to solve real-life problems using machine learning using the experience gained over time.
Some of my Machine Learning Projects are:
- Gesture replicating Robotic Arm using Deep Learning Approach.
- Worked with machine learning based text-to-speech and speech-to-text systems.
- Worked on building machine learning based chat-bots.
- Secured good rank in some machine learning competitions.
- Image compression using Deep Learning Techniques
- Generative Deep Learning
- Currently leading my University Self Driving Car project started by Developer Student Club, Patiala.
In all these years, the most valuable skill i have gained is to develop solutions and solve problems of machine learning on my own even if very less resources are available on the internet using the experience gained over the time.
I am skilled at following languages/frameworks: Python, C++/C, Tensorflow, Keras, Flask, Pandas, Numpy.
-
Below are the links to the issues/pull requests that I have worked upon:
- nexB/scancode-toolkit#1942
- nexB/scancode-toolkit#1985
- nexB/scancode-toolkit#1937
- nexB/scancode-toolkit#1979
- nexB/scancode-toolkit#1947
Other than that, I have been an active member in the discussions taking place on Gitter chat room.
-
This is my first time in GSoC. I have already learned a-lot about the open source culture and how they work in a professional way. I would be very excited to learn more. It would be one of the greatest opportunity to expand my skills while still contributing to open-source if I get to work on the project mentioned in this application :D I haven't contributed a-lot to opensource and i think this can be the starting point for seriously getting into and truly appreciating the concept of Open-Source. Most of my projects are on my Git-Hub profile. Other than that, here is a small contribution to the Mozilla DeepSpeech Project
-
I do not have any commitments that would affect my work in any way. I have not applied for any other internships/ part-time / full-time jobs. I have 24x7 internet connectivity, as well as access to personal computer and would be staying at home. I have no trips/vacations planned irrespective of GSoC or not.
-
I am confident that this project would definitely be a success since i have done the validation of my ideas in the given notebooks - Programming Language Classification, File Purpose Classification. Other than that, Mr. @romanofoti generously offered to guide me during the project. I would be taking guidance and insights from him throughout the project so that no stone gets left unturned.