{kind=link}
A. Kishk and M. El-Hadidi, "AmpliconNet: Sequence Based Multi-layer Perceptron for Amplicon Read Classification Using Real-time Data Augmentation," 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 2018, pp. 2413-2418. doi: 10.1109/BIBM.2018.8621287
python src/predict --dir_path test_fastq --database models/V46 --output_dir test_pred --input_type fastq
test_pred directory will contain prediction files for each fastq/ fasta file in the test_fastq directory Reference model have to be changed according the HVR primers of the study
for more parameters
python src/predict --help
python src/Predict_Taxonomy_Table.py --pred_dir ./test_pred/ --o-taxa_table ./test_Biom_taxon.csv --biom_taxon_table True --target_rank allThis taxonomy table can be imported by MEGAN (import> Text (csv) format > Classification >Taxonomy)
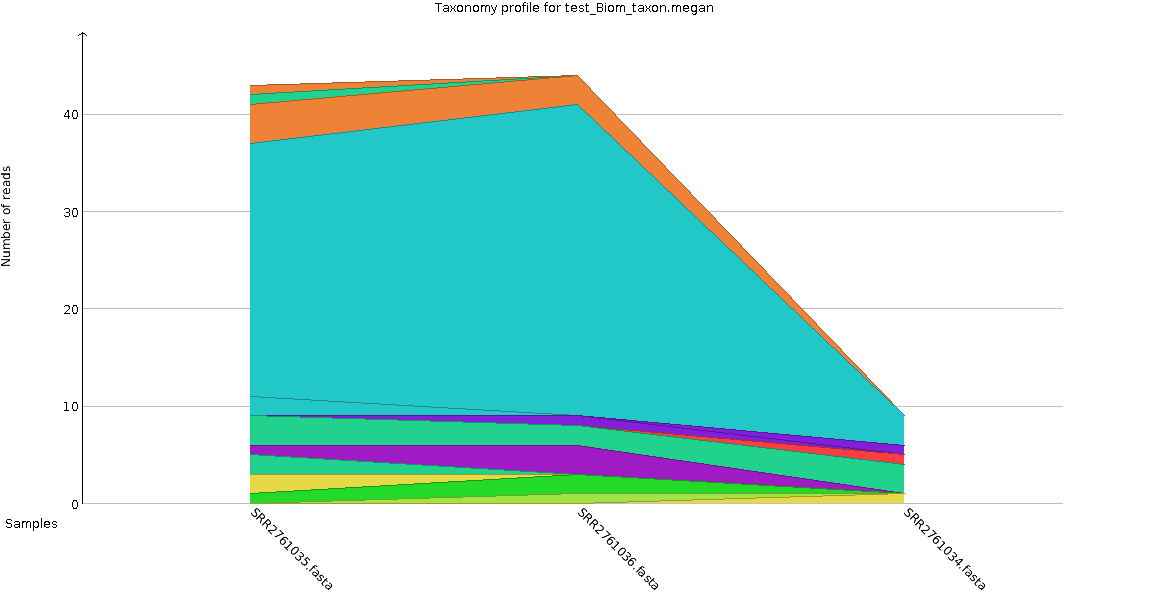
Example stacked bar using MEGAN for the generated taxonomy table 3 files in test_fastq
biom convert -i test_Biom_taxon.csv -o test_Biom_taxon_hdf5.biom --table-type="Taxon table" --to-hdf5python src/SILVA_header_2_csv.py --silva_path SILVA_132_SSURef_tax_silva.fasta --silva_header SILVA_header_All_Taxa.csv
python src/preprocess.py --hvr_database V2_SILVA.fa --silva_header SILVA_header_All_Taxa.csv --output_dir models/V2
python src/train.py --database_dir models/V2 --kmer_size 6 --batch_size 250 --training_mode mlp_sk
python src/evaluate.py --database_dir models/V2 --kmer_size 6 --batch_size 250 --training_mode mlp_skA nice brief to taxonomic classification by Rob Knight: https://www.youtube.com/watch?v=HkwFdzFLZ0I
part1: https://youtu.be/qxK9fxugMf0 part2: https://youtu.be/kNfPmOuA0Nk
Taxonomic assignment is the core of targeted metagenomics approaches that aims to assign sequencing reads to their corresponding taxonomy. Sequence similarity searching and machine learning (ML) are two commonly used approaches for taxonomic assignment based on the 16S rRNA. Similarity based approaches require high computation resources, while ML approaches don’t need these resources in prediction. The majority of these ML approaches depend on k-mer frequency rather than direct sequence, which leads to low accuracy on short reads as k-mer frequency doesn’t consider k-mer position. Moreover training ML taxonomic classifiers depend on a specific read length which may reduce the prediction performance by decreasing read length. In this study, we built a neural network classifier for 16S rRNA reads based on SILVA database (version 132). Modeling was performed on direct sequences using Convolutional neural network (CNN) and other neural network architectures such as Multi-layer Perceptron and Recurrent Neural Network. In order to reduce modeling time of the direct sequences, In-silico PCR was applied on SILVA database. Total number of 14 subset databases were generated by universal primers for each single or paired high variable region (HVR). Moreover, in this study, we illustrate the results for the V2 database model on ~ 1850 classes on the genus level. In order to simulate sequencing fragmentation, we trained variable length subsequences from 50 bases till the full length of the HVR that are randomly changing in each training iteration. Simple MLP model with global max pooling gives 0.93 test accuracy for the genus level (for reads of 100 base sub-sequences) and 0.96 accuracy for the genus level respectively (on the full length V2 HVR). In this study, we present a novel method AmpliconNet to model the direct amplicon sequence using MLP over a sequence of k-mers faster 20 times than CNN in training and 10 times in prediction.