队伍名:Team Solid
参赛人员:
- 黄斐 2014011382
- 柯沛 kepei1106@outlook.com 非本班同学
任务分工:
- 柯沛 负责API获取、提交,预处理部分
- 黄斐 负责特征提取、筛选、分类算法部分
本次KDDCup的任务要求从历史数据以及实时的API中预测未来48小时空气质量。该任务涉及到实时处理,且数据量较大,偏工程。我们搭建了如下pipeline来解决这个问题。
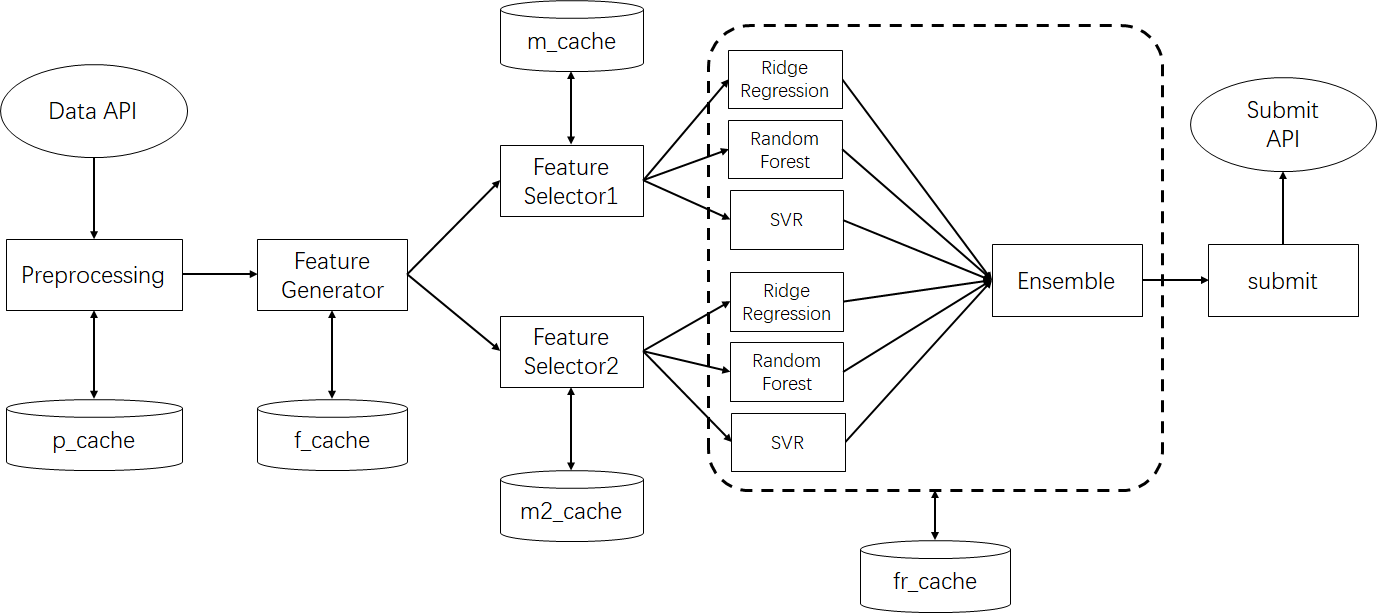
我们首先对整个流水线进行简介,之后对每一个部分进行详细介绍。
- Preprocessing:
load_data.py。从官方提供历史数据表以及实时API中获取数据,对缺失数据进行补全。为后续模块提供获取历史数据的接口。 - Feature Generator:
FeatureGenByHour.py。获取预处理后的数据,划分各个sample,生成各种数据统计量。 - Feature Selector:
LinearRegression.py和LinearRegressionDiff.py。筛选能够较好的预测y和y-y0的特征,做归一化处理并做PCA降维。 - Models && Ensemble:
FirstRegression.py。用多个回归模型对目标进行拟合,最终再用线性加权进行ensemble。 - submit:
submit.py。提交预测的结果。
我们使用了官方提供的部分历史数据:
- beijing地区35个站点,2017年1月1日~2017年3月31日的空气质量数据。包含
PM2.5、PM10、NO2、CO、O3、SO2数据。 - beijing地区网格数据,2017年1月1日~2017年3月31日,以0.1经纬度地点精度的天气数据。包含
temperature、pressure、humidity、wind_direction、wind_speed数据。 - beijing地区35个站点坐标。
- london地区13个站点,2017年1月1日~2017年3月31日的空气质量数据。包含
PM2.5、PM10、NO2数据。 - london地区网格数据,2017年1月1日~2017年3月31日,以0.1经纬度地点精度的天气数据。包含
temperature、pressure、humidity、wind_direction、wind_speed数据。 - london地区13个站点坐标。
- 我们未使用beijing地区的观测气象数据
我们对历史数据中的缺失与非法值做了手动修正。主要修正方法是插值和参考周围站点数据。
我们只使用了官方提供的API获取实时数据:
- beijing地区35个站点的实时空气质量数据。包含
PM2.5、PM10、NO2、CO、O3、SO2数据。 - beijing地区网格实时天气数据。包含
temperature、pressure、humidity、wind_direction、wind_speed数据。 - london地区13个站点的实时空气质量数据。包含
PM2.5、PM10、NO2数据。 - london地区网格实时天气数据。包含
temperature、pressure、humidity、wind_direction、wind_speed数据。 - 我们未使用beijing地区的观测气象实时数据
对于实时获取的数据中的缺失,我们使用了以下方法进行补全:
- 对于AQI数据,若某一时刻只有一个站点数据产生了缺失,则利用周围站点数据,根据距离的倒数
1/d加权进行补全。 - 对于AQI数据,若某一时刻多于一个站点产生了缺失。若该时刻为最后一个时刻,则等待直到下一时刻数据出现;否则使用相近的时刻数据进行插值。
- 对于天气数据,若某一时刻存在缺失数据,我们直接沿用上一时刻数据进行补全。
注意到1、3可能不如插值方法得到的结果好,但对于实时预测来说,数据的实时性是最重要的,所以我们选择了不依赖下一时刻的补全算法。
load_data.py提供了以下接口:
-
有效数据的时间段。该接口将所有有效数据时间段转换为时间戳的区间表示。
time_block = { "query_station_AQI" : [(t1_start, t1_end), (t2_start, t2_end)], "query_station_weather" : [(t3_start, t3_end), (t4_start, t4_end)], }
-
指定站点的AQI数据,返回值为矩阵
size = time_length * AQI_featurequery_station_AQI(station_name, start_time, end_time)
-
指定站点的周边area_len的网格内的天气数据。返回值为矩阵
size = time_length * area_len * area_len * weather_featuredata.query_station_area_weather(station_name, area_len, start_time, end_time)
同时,为了避免反复查询API,我们在本地建立了缓存,储存在./cache/p_cache下。
本问题为时序的回归问题,还涉及到地域关系,数据类型复杂,我们认为特征提取是这个问题中较重要的部分;另一方面,我们提取后的特征数据量大,而且我们的程序需要用于实时预测,故程序性能也是很重要的。我们花了较多的精力在特征提取的实现。
考虑到我们的程序需要从第二天开始的48小时,故我们将目标设定为预测未来72小时的空气质量。同时,我们采用了过去72小时的数据作为输入。即,对于某一站点的时序数据data,
输入为data[x-71:x+1],即x以及之前的72个数据
输出为data[x+1:x+73],即x以及之后的72个数据
对于过去72小时的空气质量序列,我们提取了其统计量特征,该特征由4个成分构成:
- 过去时间段:1、2、4、8、16、24、48、72小时内
- 数据源:原序列、一阶差分、二阶差分
- 统计量:最大值、最小值、平均值、1分位数、中位数、3分位数
- 属性:PM2.5、PM10、NO2、CO、O3、SO2
例如选取16、一阶差分、中位数、CO,即表示选择过去16小时内CO值的一阶差分序列的中位数。
由此提取了836*6 = 864 个特征
由于空气质量有明显的周期趋势,所以我们将过去72小时的空气质量作为了特征。该特征由2个成分构成:
- 时间:1~72小时前
- 属性:PM2.5、PM10、NO2、CO、O3、SO2
例如选取5、PM10,即表示选择过去5小时前,PM10的值
由此提取了72*6 = 432 个特征
同理,由于空气质量有明显的周期趋势,所以我们认为当前是几点和周几对空气质量有一定影响。我们将该标签作为了one-hot特征,分为三种:
- 小时: 当前是第几小时,使用one-hot表示,共24个特征
- 周几: 当前是周几,使用one-hot表示,共7个特征
- 小时x周几: 联合上述两者,使用one-hot表示,共7*24个特征
假如当前是周一1点,则1点、周一、周一的1点三个特征为1,其他都是0。
由此提取了 199 个特征
为了利用空间上的信息,我们对网格信息的统计量进行了提取,该特征由5个部分组成:
- 过去时间段:1、4、8、24、48、72
- 数据源:原序列、一阶差分
- 统计量:最小值、最大值、均值
- 网格范围大小:2、4、8
- 属性:温度、气压、湿度、风速、风速在指定方向上的投影*4
- 分段:5段
注意到给出的特征有风向,但由于风向的特殊性质,我们不能认为他是一个标量,例如359和1实际上只相差2度。于是我们对风向进行了变换,计算了风速在正北方向、东北方向、正东方向、东南方向的投影。(注意如果风速向南,则是正北方向风速为负数)
同时,我们知道这些因素和目标并非线性相关,可能有较为复杂的关系。于是我们将特征进行分段表示,使线性模型有能力拟合复杂的分段函数。
例如,选取4、原序列、均值、2、温度、第1段,则代表过去4小时内,该站点2*2的网格中,温度序列的均值,在第1段区间中的表示(若超过该区间上限,则取上限;低于下限取下限;否则取该值)。
由此提取了 62338*5 = 4320 个特征
由于不同站点有着不一样的特点,所以我们将站点的属性也纳入考虑:
- 站点属性: one-hot表示,分别代表城区环境监测点、郊区环境评价点、对照点、交通污染监控点。
由此提取了4个特征
我们将样本作为行,特征作为列,所有特征数值存成了一个矩阵。
每小时每个站点都会产生一个样本,共有3652435,约30万个样本点(因为实时预测,该数值会不断增加)。每个样本点共有5819维特征。故特征矩阵会占相当大的空间,不能一直储存在内存中。
我们将该矩阵的索引信息常驻在内存中,矩阵数值分块存储在了硬盘上,命名为“./cache/f_cache1b_[X/Y]_%d”。
由于硬盘的反复读写会引入大量的消耗,为了加快硬盘的读取,我们设计了缓存与替换算法,避免了对硬盘的反复读写,加快了程序处理速度。
-
行列索引
- 样本名
sample_name、样本属性sample_attr。由此可以获取指定站点在指定时间点上的编号。 - 特征名
feature_name、特征属性feature_attr。由此可以获取指定特征的编号。 - 预测目标名
output_name、预测目标属性output_attr。由此可以获取样本需要预测的目标编号。
- 样本名
-
数据读取
select(Xindex = None, Findex = None, Oindex = None, checkValid=True) 读取sample索引为Xindex,特征索引为Findex,目标索引为Oindex的矩阵。 若不提供相应参数,则默认是读取全部。 checkValid为True是会检测特征矩阵、输出矩阵是否都为有效数值。
由于特征过多,我们必须通过特征筛选来减少模型的计算量。
我们通过两种回归目标对特征进行了筛选。
第一种是直接预测未来72小时的各项数值。
第二种,对于这种时序问题,我们预测未来72小时的各项数值y与当前时刻的该项数值y'的差y-y'
通过这两个目标,我们分别对特征进行筛选。
注意,我们并不是预测每一时刻与上一时刻的差分,因为这样在计算时会引起累计误差。
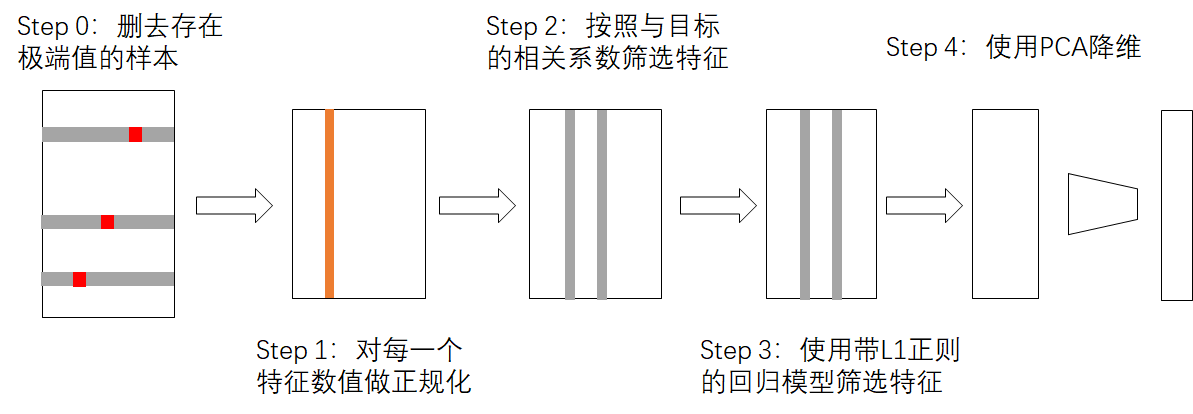
为了保证效率,我们随机选取了10000个样本,找到5%和95%分位数y_low,y_high。当y-y_high>(y_high-y_low)*2.5或者y_low-y>(y_high-y_low)*2.5,我们认为该值为计算值。我们会去除包含该值的样本。
我们首先对超过一定范围的值进行clipping处理。保证值在[y_low-IQR2.5, y_high+IQR2.5]间。对于分段的序列,为5和95分位数;对于one-hot表示,不进行clipping处理;对于其他序列,为25和75分位数。
之后我们对每一维特征线性放缩,使其满足均值为0,方差为1。
我们计算了特征与目标的pearson系数,筛选了超过阈值的特征。
我们使用了sklearn中的Lasso Regression,并使用5折验证方法调整了参数。最终选取了特征系数不为0的部分。
此时特征还是过多,并且以上方法都无法去除特征的共线性。我们使用PCA降维方法将特征降到500维。
以下接口提供了指定样本经过5个步骤后的特征矩阵。
passPCA(Xindex)
Xindex指定样本集合
该部分的缓存储存在./cache/m_cache和./cache/m2_cache中
同上节,我们同样对原目标y和y-y'进行预测
我们使用了sklearn的Ridge Regression算法,并在10、50、100中交叉验证取得了最好的参数。
我们使用了sklearn的RandomForest算法。
值得注意的是,因为性能原因,我们随机选取了5000个样本和50个特征进行训练
我们使用了sklearn的SVR算法。
我们对epsilon = [0, 0.1, 10, 100]; C = [0.1, 10, 100]中,选择了在验证集上性能最好的参数。
值得注意的是,因为性能原因,我们随机选取了30000个样本
对于以上的三个模型,分别预测原目标y和y-y’。我们能计算出6种y的回归结果。
我们使用了线性加权模型,如下式
最小化目标SMAPE。我们将alpha初始化为1/6,再使用梯度下降进行学习。
值得注意的是,我们没有要求所有alpha的和为1。这是因为我们模型训练目标和SMAPE并不是相同的,可以认为两者之间有bias,这一点可以通过系数的调整来优化结果。
我们使用以下接口可以预测目标序列
predict(Xindex, checkValid=True)
Xindex指定预测样本集合,checkValid检测样本的所有特征是否有效
该部分的缓存储存在./cache/fr_cache中
由于这次比赛是一个实时预测任务,有最新的数据则会更加有利。比赛每天允许提交3次。
考虑到模型的运行时间,为了保证提交成功,我们手动的在每天16点交一次。我们让模型自动在22点、23点再次提交。
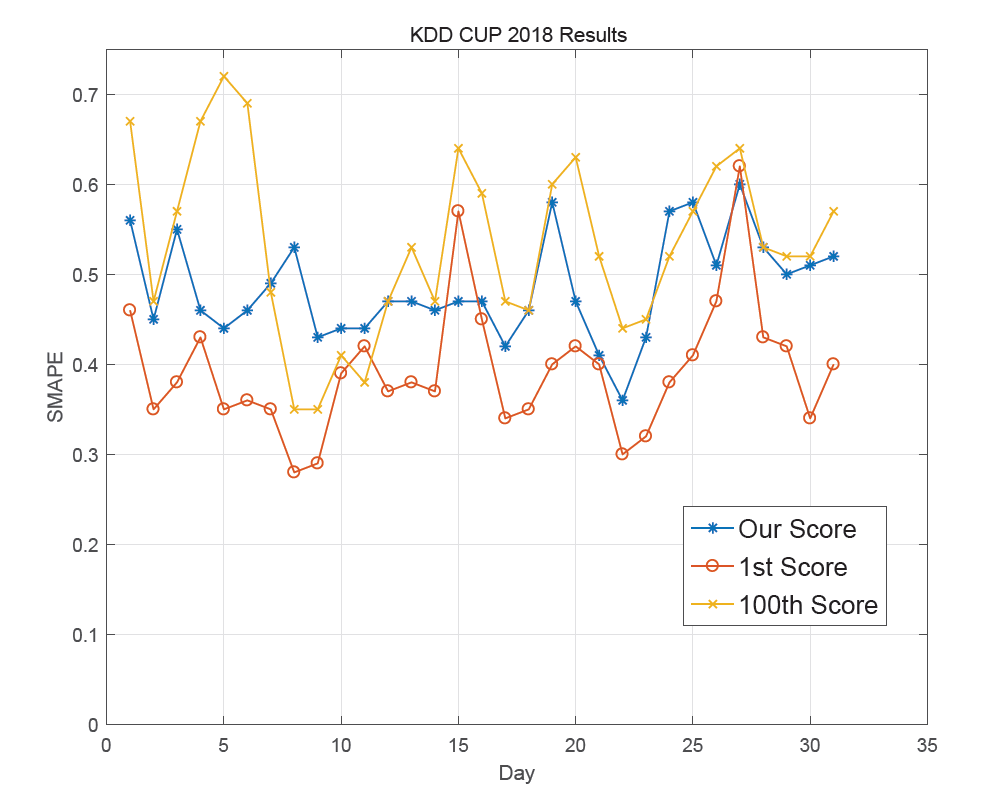
我们的模型在参赛的662个队伍中排名第65,SMAPE均值为0.4644.
我们的结果与第1名、第100名的变化曲线如下。
本次KDDCup在很多方面是一个较工程的一次比赛。
第一,工程性表现在实时的API读取和提交。这使得我们必须完成一个全自动的预测模型。
第二,官方提供的数据存在较多缺失。考虑到这是一个实时预测,所以必须有不依赖未来数据的数据补全方法。
第三,该问题使用的数据较多,这使得对数据的储存需要一定的技巧。
我们队伍没有选择比较复杂的模型,而主要在特征生成和特征筛选上花费了较多时间。同时,在模型的内存占用、运行速度上也进行了优化。
分析这次比赛,我们还有一些没有尝试的部分:
- 对站点的建模。我们在本次比赛中对所有站点一同处理,没有考虑到站点特征。如何对站点建模可能是可以探究的部分。
- 更多的数据。本次比赛可以使用额外的数据源。天气预测可能对空气质量的预测有着较大的帮助,如何引入是一个重要的问题。
- 特征选取中,应该使用有监督的降维LDA算法,而不应该使用PCA降维方法。
- 我们的模型较为简单,如果再加入XGBoost或者其他模型,说不定会有更好的效果。