{kind=link}
Welcome to a reviewr nuance parser in Spark!
In this project, we try to see whether any emotional response in a product review text is correlated with the actual review rating given by a user.
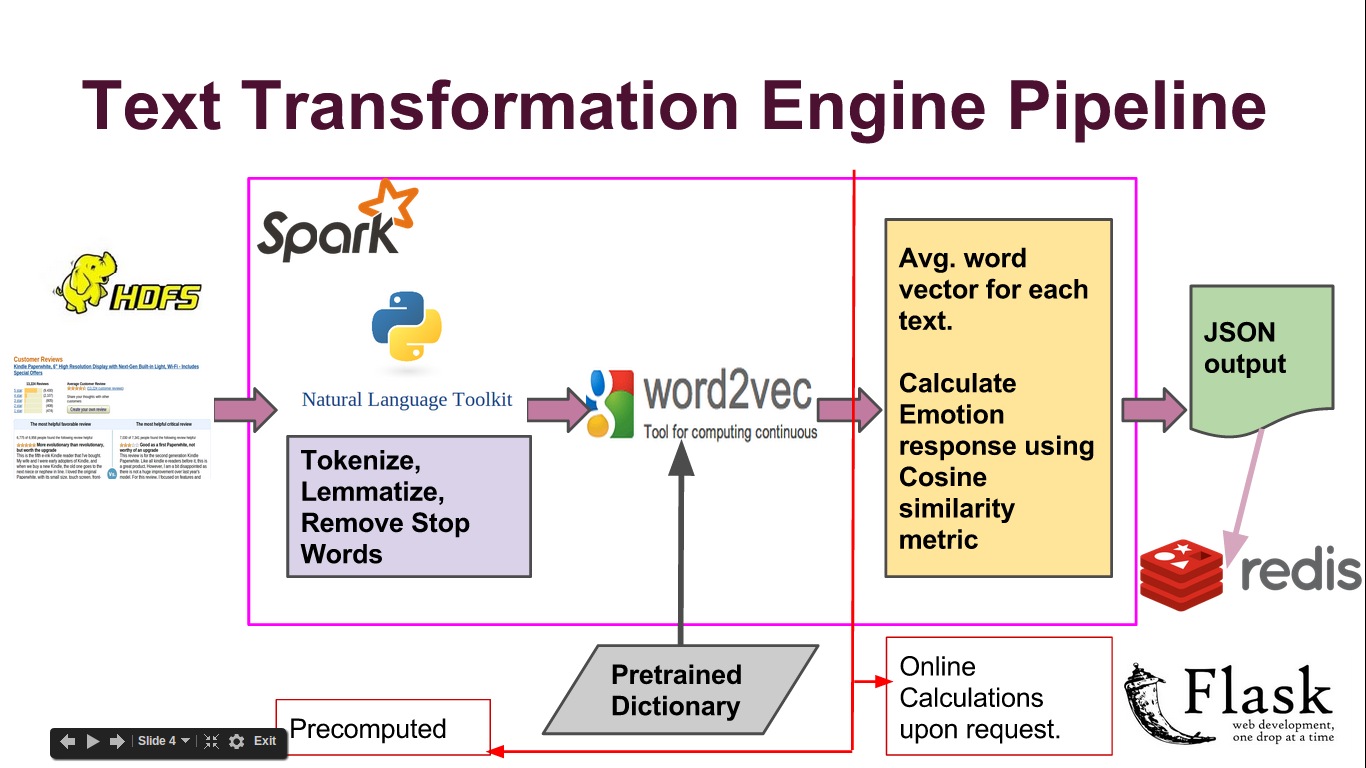
Here's step by step guide to run the parser on EC2 cluster.
- Download Spark and launch the clusters. 1.1 Download Spark 1.0.0 or the latest one from http://spark.apache.org/downloads.html. to your local machine. 1.2 In the main Spark folder, run the Spark launch script. See details at http://spark.apache.org/docs/latest/ec2-scripts.html ex. ./spark-ec2 -k -i <mykeyfile.pem> -s 5 -t r3.xlarge -r us-west-2 launch mysparkclustername
Once cluster is launched, log in to the cluster and complete the following steps.
-
Install addional Python packages 1.1 pip install flask, gensim, json, redis, numpy
-
Git clone this repository. All the files should be in the same folder unless you are providing your own review.
-
Download these data and model files and place them in the same folder you created in #2.
https://dl.dropboxusercontent.com/u/3421484/text8.model
https://dl.dropboxusercontent.com/u/3421484/text8.model.syn0.npy
https://dl.dropboxusercontent.com/u/3421484/text8.model.syn1.npy
https://dl.dropboxusercontent.com/u/3421484/Watches.json
- Run 'SPARK_MAIN_PATH/bin/spark-submit transform_word2vec_amazon.py file://YOUR_CURRENT_PATH/Watches.json' in the main parser folder. 'Whatches.json' is a sample data file. If you want to try out different reviews, createa a review file which has a line by lnie json review entries, where each json contains all the amazon review fields as described in http://snap.stanford.edu/data/web-Amazon.html.