This repository is an experiment I made during Lyft's Motion Prediction Kaggle Competition.
Notes
- The script is not optimized, and it is not complete (no history, no traffic lights)
- It could be improve training time if you have 1-2 CPU cores
- Multithreading (
num_worker > 0) is partial. See the details below
- Download the train data from Kaggle or Lyft
- Decompress and save to the
./inputfolder
LyftOpenGL/
|- cache/
|- input/
| | - aerial_map/
| | - scenes/
| | | - train.zarr
| | - semantic_map/
|- opengl/
|- baseline.py
|- opengl_rasterizer.py
|- README.md
- Execute test scripts
~$ python opengl_rasterizer.py
~$ python baseline.py
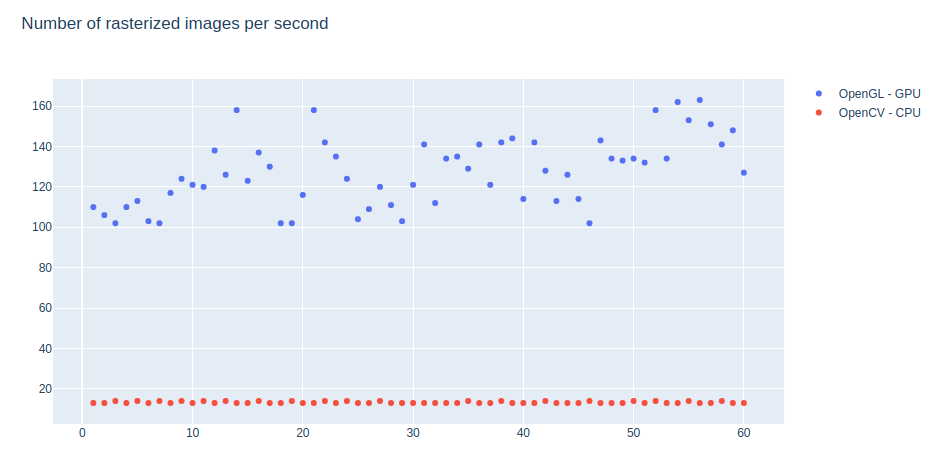
| Method | # CPU | Size | History | # of samples | Running time | it/sec |
|---|---|---|---|---|---|---|
| CPU rasterizer | 1 | 650px | 0 | 1,000 | 1:14 | 13.41 |
| OpenGL GPU | 1 | 650px | 0 | 10,000 | 1:16 | 130.49 |
The main issue is that the data generation (loading and rasterizing) is blocked in the main thread until the training process (forward-backward) finishes.
-
Get next batch of data (multithreaded by PyTorch's
Dataloader) -
Rasterize all of the samples in the batch (on one thread; one-by-one):
- Send data to the OpenGL,
- Rasterize to a custom frame buffer object
- Read the result pixels from fbo
- Convert to torch tensor
-
Move the batch to cuda
-
Train (forward, backward, etc)
These just ideas, I haven't tried them.
- Create a producer-consumer queue. One thread for training, one for image rasterizing
- With C++ we can share memory between the FBO and the CUDA/PyTorch Tensor. I am not sure whether it can be done in Pytorch or not.
Multithreading is partial. You can use num_workers > 0 for data loading, but the image rasterization is still executed on one thread (OpenGL limitation).
If you'd like to try the multithreaded version, you will have to change the l5kit a bit.
Add these to the returned dictionary
return {
...
"history_frames": history_frames,
"history_agents": history_agents,
"history_tl_faces": history_tl_faces,
"selected_agent": selected_agent,
...
}
Small bug fix
+++ l5kit/l5kit/dataset/ego.py (revision 7b9a3c55c97371076a2b5cc4d91a6c77d499a180)
@@ -80,8 +80,12 @@
"""
frames = self.dataset.frames[get_frames_slice_from_scenes(self.dataset.scenes[scene_index])]
data = self.sample_function(state_index, frames, self.dataset.agents, self.dataset.tl_faces, track_id)
+
# 0,1,C -> C,0,1
- image = data["image"].transpose(2, 0, 1)
+ image = None
+
+ if data["image"] is not None:
+ image = data["image"].transpose(2, 0, 1)
Add these lines to the returned dictionary:
return {
...
"history_frames": data["history_frames"],
"history_agents": data["history_agents"],
"history_tl_faces": data["history_tl_faces"],
"selected_agent": data["selected_agent"],
...
}
You can find the necessary changes in this code in the multithread branch.