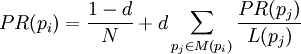Implementation of different techniques used in Web Search Engine.
Classification techiniques:
1. Naive Bayes
The key is how to compute the posterior probability that document dj belongs to category ci. According to Bayes formula, the posterior probability
is translated to compute the prior probability
. Then, the categories that have the most prior probability are judged into the final categories of document dj.
Here P(ci) denotes the probability of category csub>i in the training set and P(dsub>j) denotes document dsub>j in the training set. Because P(dsub>j) is invariant for a given document dsub>j in all categories. The final category is decided by following formula :
We have used Multinomial Naive Bayes, in which we take into account the term frequency in the class, the term count of the class and vocabulary of the dataset. If , then the probability of a token wsub>j given class ci is calculated by
Using this, the probability of a document given the class is given by
2. K-means Clustering
Algorithm Pseudocode:
- Pick K mean vectors using labeled data
- Calculate initial mean and allow documents to assign to different cluster contradicting the label tags. We do this step to not over fit the data
- Iterate until
- Assign each document xi to its closest mean vector μj.
- Update each mean vector μj to be the mean of the xi’s assigned to it.
Distance between documents and mean are calculated using Cosine Similarity (since the documents are normalized according to their length). An error function is used as Gradient descent and the objective is to minimize this error function. It is the sum of the distance between the documents to their assigned clusters.
Error Function:
3. K-Nearest Neighbor:
The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances. The prediction attribute of the most similar instances is summarized and returned as the prediction for the unseen instance. The decision rule in kNN can be written as:
These methods are used to find relevance of a given document to a query or retrieving a set a pages.
We also implement PageRank to rank pages according to their popularity once we find a set of pages relevant to the user.
We use Google's page rank method to rank pages which deals with spider traps and deadends.
Equation: