{kind=link}
A real-time graph construction from retweets of a tweet
#Introduction The idea is to graph re-tweets of a tweet for the purpose of visualizing how that tweets has spread out across followers and followers-of-followers.
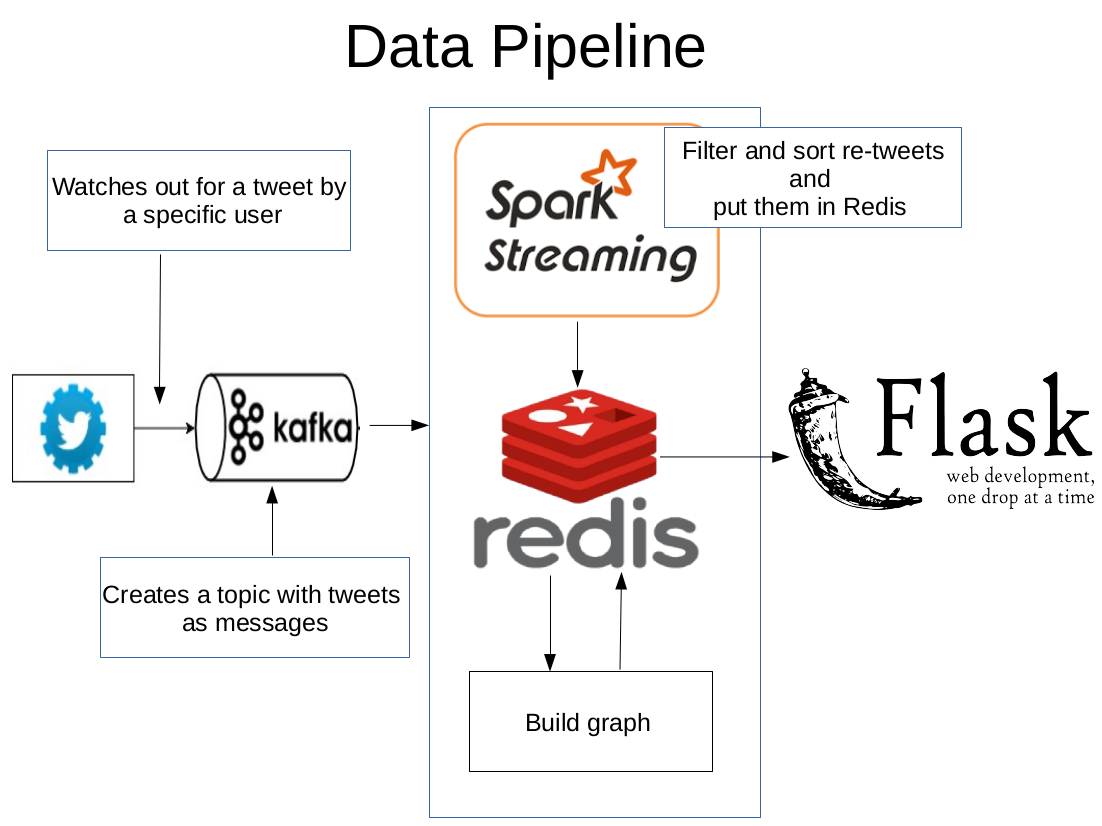
#Data Pipeline The process starts by listening for a tweet by a specific user. After one is found, the upcoming tweets are ingested in to the pipelien through kafka. The tweets are streamed from Twitter through a twitter public streaming API. Spark streaming is also employed to filter and sort these incoming tweets.Even if sorting incurs a lot of shuffling across spark streaming nodes, it is still important because re-tweets can arrive out of order, therefore they need to be sorted.
The Re-tweet graph is made out of the sorted re-tweets by connecting users (who have retweeted a specific tweet) with another user who has retweeted the tweet at earlier time. That means nodes in the Re-tweet graph represent users who retweeted the same tweet, and the edges between them represent who retweet from whom. Finally, a Redis data store is used to cache this graph for later retrieval. The web development framework, Flask is used to accept users input, grab the Re-tweet graph from Redis, and display it to users.