Though Python has many advantages such as its flexibility and simple expressive syntax, it is considered as poor performance in terms of massive data processes and computation. To accelarate the computation speed of Python, we came up with the idea of using CUDA-capable GPUs. In our final project, we focused on NumbaPro and tried several ways to improve performance like using 'vectorize', CUDA Host API and writing CUDA directly in Python. Up to 700 times of speedup is achieved in the final tests.
Numba is a Numpy-aware optimizing compiler for Python. Numba supports the just-in-time compilation from original Python code to machine code wih the LLVM compiler infrastructure, leading to improved performance.

NumbaPro is the enhanced version of Numba. NumbaPro compiler targets multi-core CPU and GPUs directly from simple Python syntax, which enables easily move vectorized NumPy functions to the GPU and has multiple CUDA device support.
Except this, NumbaPro provides a Python interface to CUDA cuBLAS (dense linear algebra), cuFFT (Fast Fourier Transform), and cuRAND (random number generation)libraries. And its CUDA Python API provides explicit control over data transfer and CUDA streams.
With NumbaPro, we tried THREE ways to improve the python computing ability. They are using 'vectorize' to automatically accelerate, binding to cuRAND, cuFFT host API for operation on Numpy arrays and writing CUDA directly in Python. We found samples to test how much 'vectorize' and host API could help and then implemented two examples (bubble sort and blowfish encrption) by writing CUDA in Python.
Testing GPU: GeForce GTX 870M
The following is a general Numpy example to implement Monte Carlo Option Pricer and its performance, here is part of the code:
import numpy as np # numpy namespace
from timeit import default_timer as timer # for timing
from matplotlib import pyplot # for plotting
import math
def step_numpy(dt, prices, c0, c1, noises):
return prices * np.exp(c0 * dt + c1 * noises)
def mc_numpy(paths, dt, interest, volatility):
c0 = interest - 0.5 * volatility ** 2
c1 = volatility * np.sqrt(dt)
for j in xrange(1, paths.shape[1]): # for each time step
prices = paths[:, j - 1] # last prices
# gaussian noises for simulation
noises = np.random.normal(0., 1., prices.size)
# simulate
paths[:, j] = step_numpy(dt, prices, c0, c1, noises)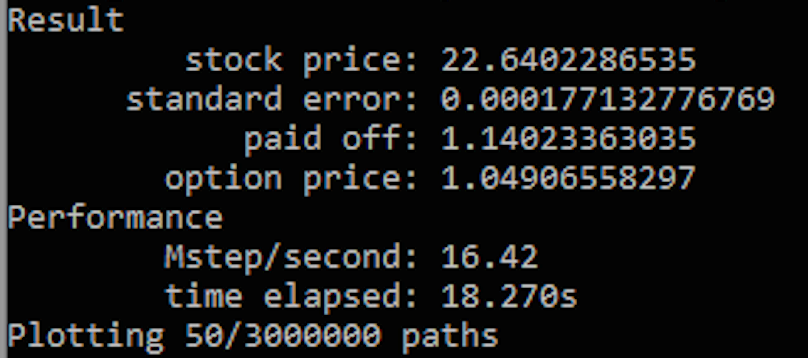
CUDA vectorize produce a universal-function-like object, which is close analog but not fully compatible with a regular Numpy u-func. The CUDA vectorized u-func adds support for passing intra-device arrays (already on the GPU device) to reduce traffic over the PCI-express bus.
To use it just simply change target to 'gpu', here is code snippet:
import numpy as np # numpy namespace
from timeit import default_timer as timer # for timing
from matplotlib import pyplot # for plotting
import math
from numbapro import vectorize
@vectorize(['f8(f8, f8, f8, f8, f8)'], target='gpu')
def step_gpuvec(last, dt, c0, c1, noise):
return last * math.exp(c0 * dt + c1 * noise)
def mc_gpuvec(paths, dt, interest, volatility):
c0 = interest - 0.5 * volatility ** 2
c1 = volatility * np.sqrt(dt)
for j in xrange(1, paths.shape[1]):
prices = paths[:, j - 1]
noises = np.random.normal(0., 1., prices.size)
paths[:, j] = step_gpuvec(prices, dt, c0, c1, noises)
As can be seen from the result, there is a 25% speed up without changing large part of original code.
While due to the memory transfer overheads(from CPU memory to GPU global memory), the performance here is still not excellent.
To deal with the problem mentioned above, a cuRAND random number generator with CUDA JIT feature compile is used to reduce memory transfer overheads.
NumbaPro’s CUDA JIT is able to compile CUDA Python functions at run time and realize explicit control over data transfers and CUDA streams. The sample code goes like this:
import numpy as np # numpy namespace
from timeit import default_timer as timer # for timing
from matplotlib import pyplot # for plotting
import math
from numbapro import cuda, jit
from numbapro.cudalib import curand
@jit('void(double[:], double[:], double, double, double, double[:])', target='gpu')
def step_cuda(last, paths, dt, c0, c1, normdist):
i = cuda.grid(1)
if i >= paths.shape[0]:
return
noise = normdist[i]
paths[i] = last[i] * math.exp(c0 * dt + c1 * noise)
def mc_cuda(paths, dt, interest, volatility):
n = paths.shape[0]
blksz = cuda.get_current_device().MAX_THREADS_PER_BLOCK
gridsz = int(math.ceil(float(n) / blksz))
# instantiate a CUDA stream for queueing async CUDA cmds
stream = cuda.stream()
# instantiate a cuRAND PRNG
prng = curand.PRNG(curand.PRNG.MRG32K3A)
# Allocate device side array
d_normdist = cuda.device_array(n, dtype=np.double, stream=stream)
c0 = interest - 0.5 * volatility ** 2
c1 = volatility * math.sqrt(dt)
# configure the kernel
# similar to CUDA-C: step_cuda<<<gridsz, blksz, 0, stream>>>
step_cfg = step_cuda[gridsz, blksz, stream]
# transfer the initial prices
d_last = cuda.to_device(paths[:, 0], stream=stream)
for j in range(1, paths.shape[1]):
# call cuRAND to populate d_normdist with gaussian noises
prng.normal(d_normdist, mean=0, sigma=1)
# setup memory for new prices
# device_array_like is like empty_like for GPU
d_paths = cuda.device_array_like(paths[:, j], stream=stream)
# invoke step kernel asynchronously
step_cfg(d_last, d_paths, dt, c0, c1, d_normdist)
# transfer memory back to the host
d_paths.copy_to_host(paths[:, j], stream=stream)
d_last = d_paths
# wait for all GPU work to complete
stream.synchronize()
With the help of JIT compile and cuRAND library, we finally get a 18x speedup.
However, the 18x speedup is not perfect. Then we put the emphasis on writing CUDA in Python to arrange part of work to each thread.
We implemented two examples: bubble sort and blowfish encrption.
The reason why we choose bubble sort is because that it can take very large array for calculation and the sort part can be easily paralleled.
The cpu serial version is straightforward and time-consuming: divide input array into chunks and after sorting, merge them again. And the gpu part devides the large array into small chunks and each thread is responsible of one chunk and thus realizes the cuda parallelization:
dA = cuda.to_device(disorder)
bbSort[bpg, tpb](dA)
dA.to_host()
...
@cuda.jit(argtypes=[float32[:]], target='gpu')
def bbSort(A):
threadID = cuda.grid(1)
si = chunkSize * threadID
ei = chunkSize * (threadID + 1)
for i in range(ei, si, -1):
for j in range(si, i - 1, 1):
if A[j] > A[j+1] :
temp = A[j]
A[j] = A[j+1]
A[j+1] = tempOnce the array is transferred from cpu to gpu, the kernel part is able to be launched with specification of number of blocks per grid and number of threads per block. After the calculation, the sorted array will be transferred back to cpu then merged.
One remarkable feature of CUDA code is to use shared memory for acceleration. Here is the kernel with shared memory:
@cuda.jit(argtypes=[float32[:]], target='gpu')
def bbSort(A):
blockID = cuda.blockIdx.y * cuda.gridDim.x + cuda.blockIdx.x
totalID = blockID * cuda.blockDim.x + cuda.threadIdx.x
threadID = cuda.threadIdx.x
sA = cuda.shared.array(shape=(256), dtype=float32)
swapped = cuda.shared.array(shape=(1), dtype=int32)
swapped[0] = 1
sA[threadID] = A[totalID]
cuda.syncthreads()
while swapped[0]:
cuda.syncthreads()
swapped[0] = 0
if((threadID%2==0) and (sA[threadID] > sA[threadID+1])):
swapped[0] = 1
temp = sA[threadID]
sA[threadID] = sA[threadID+1]
sA[threadID+1] = temp
cuda.syncthreads()
if((threadID%2==1) and (sA[threadID] > sA[threadID+1]) and (threadID != cuda.blockDim.x - 1)):
swapped[0] = 1
temp = sA[threadID]
sA[threadID] = sA[threadID+1]
sA[threadID+1] = temp
cuda.syncthreads()
cuda.syncthreads()
A[totalID] = sA[threadID]
cuda.syncthreads()As can be seen from the example, numbapro enables python codes with most of its original functionality while keeps the simplicity as the same time.
###Blowfish encryption
Blowfish enciphers a picture read in bytes with multiple calculation, and the decipher part can be used to verify the correctness of encryption. Since the all parts of the array are independent, this process can be conducted with parallelism.
The gpu parallel version:
Text = cuda.to_device(fileI)
dS = cuda.to_device(S1)
dP = cuda.to_device(P)
Blowfish_encipherG[bpg, tpb](Text, dS, dP)
Text.to_host()
...
@cuda.jit('void(uint32[:], uint32[:], uint32[:])', target='gpu')
def Blowfish_encipherG(Text, s, p):
sS = cuda.shared.array(shape=(1024), dtype=uint32)
sP = cuda.shared.array(shape=(18), dtype=uint32)
tid = cuda.threadIdx.x
gid = cuda.grid(1)
interval = 1024/tpb
for i in range (tid*interval, (tid+1)*interval, 1):
sS[i] = s[i]
cuda.syncthreads()
if tid<N+2:
sP[tid] = p[tid]
cuda.syncthreads()
if gid*2+1 < len(Text)/4 and tid < cuda.blockDim.x:
xl = Text[gid*2]
xr = Text[gid*2+1]
for j in range (0, N, 1):
xl = xl ^ sP[j]
x = xl
d = x & 0x00FF
x >>= 8
c = x & 0x00FF
x >>= 8
b = x & 0x00FF
x >>= 8
a = x & 0x00FF
y = sS[a] + sS[256+b]
y = y ^ sS[512+c]
y = y + sS[768+d]
xr = y ^ xr
temp = xl
xl = xr
xr = temp
temp = xl
xl = xr
xr = temp
xr = xr ^ sP[N]
xl = xl ^ sP[N + 1]
cuda.syncthreads()
Text[gid*2] = xl
Text[gid*2+1] = xr
cuda.syncthreads()###Performance report

As can be seen from the picture, gpu parallel with shared memory speed up for almost 700 times at most.Dramatical speedup for calculation-intensive python code is realized.
The improvemnt of performance of Python code on GPUs still leaves much to be desired. For example, the problem of band conflicts still exists and has bad effect on progrem speedup. Also, we used CUDA JIT decorator in the project several time. In the future, we are interested in developing our own decorator to improve the performance further.