{kind=link}
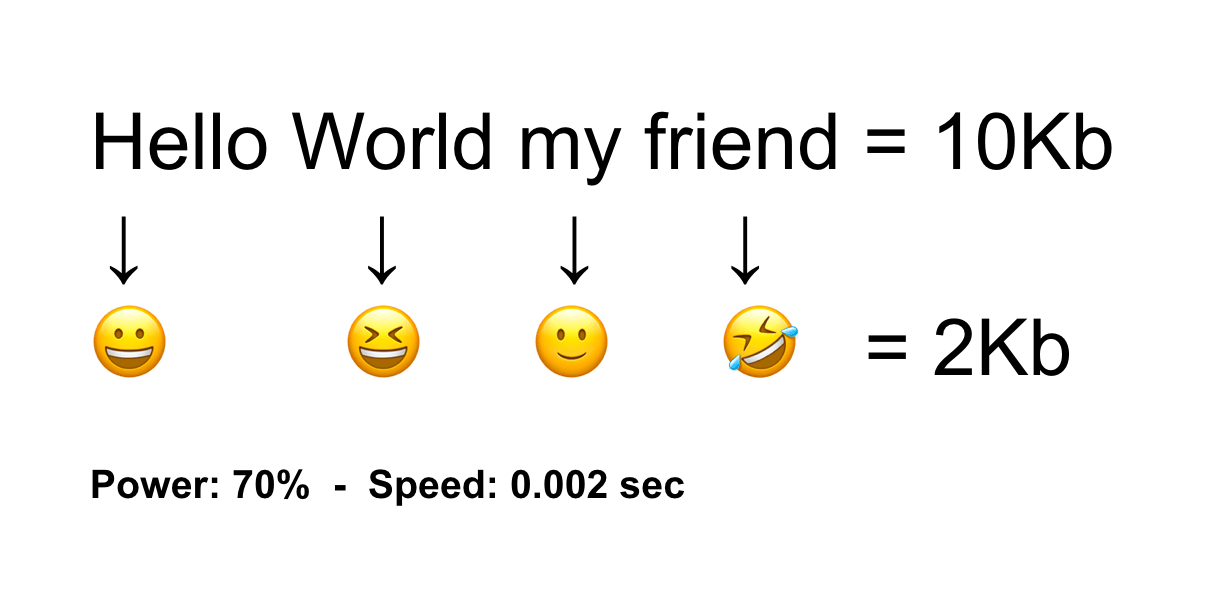
Lets create a compression algorithm 🤯 It sounds hard but it's something achievable for almost anyone.
Create an algorithm that given a string, replaces its words matching the symbols dictionary keys and replaces them with their respective values on the same dictionary.
symbols = {
"implementation": "🤯",
"practicality": '🤩',
"better": '😅',
"Although": "🥺"
}For example:
Although, this is a great implementation of time |
→ should become → | 🥺, this is a great 🤯 of time |
|---|
The current project has 3 main files:
| Name | Description |
|---|---|
| compress.py | Contains the algorithm to compress the content, it has a function "compress" that receives the raw text and returns the compressed version of it |
| decompress.py | It's very similar to compress.py but it contains the algorithm to convert back the content from its compressed version to the original content |
| app.py | This is entry file, and there is no need to update it, it imports and uses the other two files |
- Take time to understand the code, start by opening and reading the
app.pyand follow the algorithm with your brain, review the compress.py and decompress.py files to understand where your solution must be implemented. - Run the app.py by typing
python3 app.pyand undestand what is the output and why. - Edit the compress.py to create the compression algorithm.
- Test your compression algorithm by running the app.py again.
- Edit the decompress.py to create the decompression algorithm.
- Test your decompression algorithm by running the app.py again.
Download/clone the project and type the folloding in the command line:
python3 app.pyYou should get a response similar to this:
✅No data lost.
document.txt has 824 size, compressed.txt has 768 size, compression of 7% in 0.0003972053527832031 seconds - Compression power: Ratio is defined as the ratio between the uncompressed size and compressed size.
- No Data lost: If we compress and decompress document.txt the result should be the original string of content.
By adding more words to the symbols dict you can achieve more compression power.
Try to re-do the algorithm to achieve a compression power above 15% with no data lost without just adding more words.