Enunciado:
La solución de problemas complejos (y muchas veces no tan complejos) en obras civiles requiere del uso de computadores personales o dedicados para la ejecución de programas que ayudan a buscar e implementar soluciones. Estos programas resuelven sub-problemas que se modelan utilizando herramientas matemáticas como las que se han aprendido hasta ahora (álgebra lineal, ecuaciones diferenciales, probabilidades, estadística, etc. ) y cuyo rendimiento es clave para la solución rápida y eficiente de los problemas de ingeniería.
En este proyecto inicial haremos "benchmarking" de nuestros computadores de trabajo en distintos indicadores de desempeño frente a distintas cargas. Aprenderemos a medir el desempeño de nuestro sistema frente a distintas tareas y como cambia el mismo frente a distintos "tamaños" de estas tareas. Con esto aprenderemos acerca de distintos factores que contribuyen o afectan el desempeño de nuestros programas y podremos tomar decisiones realistas a la hora de implementar una solución computacional a un problema en la vida real.
Objetivos:
Medir el tiempo que toma (y uso de memoria) al resolver los siguientes problemas:
-Multiplicación de matrices (matmul)
-Solución de sistemas de ecuaciones (solve)
-Inversión de matrices (inv)
-Problemas de valores y vectores propios para matrices hermitianas de valores reales (eigh)
-En función de distintos tamaños de las matrices involucradas. Explorar distinta estrategias (implementación manual, uso de librerías, explotación de simetría, paralelismo, matrices dispersas) para entender como estas afectan el desempeño de sus programas.
Especificaciones del computador:
-
Marca/modelo: DELL PRECISION M2800
-
Tipo: Notebook
-
Año adquisición: 2017
-
Procesador:
- Marca/Modelo: Intel® Core™ i7-4810MQ
- Velocidad Base: 2.80 GHz
- Velocidad Máxima: 3.80 GHz
- Numero de núcleos: 4
- Numero de hilos: 8
- Arquitectura: x86_64
- Set de instrucciones: Intel® SSE4.1, Intel® SSE4.2, Intel® AVX2
-
Tamaño de las cachés del procesador
- L1: 256 KB
- L2: 1.0 MB
- L3: 6.9 MB
-
Memoria
- Total: 12B
- Tipo memoria: DDR3
- Velocidad: 1600 MHz
- Numero de (SO)DIMM: 2
-
Tarjeta Gráfica
- Marca / Modelo: AMD FirePro W4170M (FireGL V)
- Memoria dedicada: 2000 MB
- Resolución: 1920 x 1080
-
Disco 1:
- Marca: Samsung
- Tipo: SSD
- Tamaño: 239GB
- Particiones: 1
-
Sistema de archivos: NTFS
-
Dirección IP (Interna, del router): 192.168.0.1
-
Dirección IP (Externa, del ISP): 201.214.100.251
-
Proveedor internet: VTR Banda Ancha S.A.
- Desempeño en la multiplicación de matrices
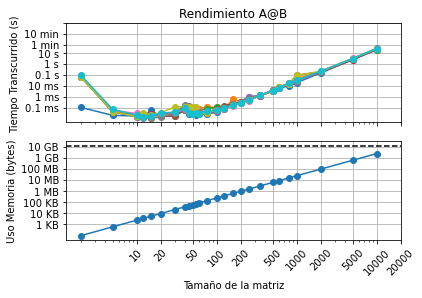
-
¿Como difiere del gráfico del profesor/ayudante?
- La diferencia entre ambos gráficos está en que la curva de mi gráfica presenta variaciones mucho menos pronunciadas en relación a la del profesor. La mayoria de los valores iniciales (0-50) en mi caso hay un tiempo de demora mayor al del profesor. Por otro lado, entre los valores 50 y 2000 mi computador presenta tiempos de ejecución menores a los del profesor. Finalmente entre los 2000 y 10000 valores los resultados son idénticos.
-
¿A qué se pueden deber las diferencias?
- Las diferencias se deben a los diferentes procesadores que hay entre ambos computadores, por ende los tiempos de ejecución varían levemente.
-
El gráfico de uso de memoria es lineal con el tamaño de matriz, pero el de tiempo transcurrido no lo es ¿porqué puede ser?
- Porque la cantidad de memoria usada es una función lineal "y = 2*(N*N)*8 con N fijo", mientras que la función del tiempo toma en cuento el proceso de multiplicar matrices. Por otro lado, son muchos los factores que inlfuyen en cuánto se demora el procesar una operación matemática, como los programas que están abiertos entre otros.
-
¿Qué versión de python está usando?
- Estoy usando la versión 3.8
-
¿Qué versión de numpy está usando?
- Estoy usando la versión 1.18.5
-
Durante la ejecución de su código ¿se utiliza más de un procesador? Muestre una imagen de su uso de procesador durante alguna corrida para confirmar.
- Se utilizan los 4 núcleos y en total son 8 los hilos usado.

- Se utilizan los 4 núcleos y en total son 8 los hilos usado.

- Desempeño MIMATMUL
-
¿Como difiere del gráfico del profesor/ayudante?
- La diferencia entre ambos gráficos está en que el gráfico del profesor presenta una gran disperción en los valores para diferentes tamaños de N mientras que mi gráfico es mucho más "lineal", hay una variación mucho menor, particularmente en el principio
-
¿A qué se pueden deber las diferencias?
- Las diferencias se deben a los diferentes algoritmos de resolución de operaciones matriciales. Mi código no está optimizado por lo que no hay forma en que el código que escribí tenga tiempos de resolución más óptimos que otros, hablando en grandes magnitudes. Por otro lado, mi computador no fue capaz de superar las 1000 iteraciones debido a que tomaría horas o días en terminarlo.
-
El gráfico de uso de memoria es lineal con el tamaño de matriz, pero el de tiempo transcurrido no lo es ¿porqué puede ser?
- Porque la cantidad de memoria usada es una función lineal "y = 2*(N*N)*8 con N fijo", mientras que la función del tiempo toma en cuento el proceso de multiplicar matrices. Por otro lado, son muchos los factores que inlfuyen en cuánto se demora el procesar una operación matemática, como los programas que están abiertos entre otros.
-
¿Qué versión de python está usando?
- Estoy usando la versión 3.8
-
¿Qué versión de numpy está usando?
- Estoy usando la versión 1.18.5
-
Durante la ejecución de su código ¿se utiliza más de un procesador? Muestre una imagen de su uso de procesador durante alguna corrida para confirmar.
- Se utilizan los 4 núcleos y en total son 8 los hilos usado.

- Se utilizan los 4 núcleos y en total son 8 los hilos usado.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Algoritmo de inversión cree que utiliza cada método: Las funciones de álgebra lineal de NumPy se basan en BLAS y LAPACK para proporcionar implementaciones eficientes de bajo nivel de algoritmos de álgebra lineal estándar. Esas bibliotecas pueden ser proporcionadas por el propio NumPy utilizando versiones C de un subconjunto de sus implementaciones de referencia pero, cuando es posible, se prefieren las bibliotecas altamente optimizadas que aprovechan la funcionalidad del procesador especializado. Ejemplos de tales bibliotecas son OpenBLAS, MKL (TM) y ATLAS. Debido a que esas bibliotecas son multiproceso y dependen del procesador, es posible que se necesiten variables ambientales y paquetes externos como threadpoolctl para controlar el número de subprocesos o especificar la arquitectura del procesador. Varias de las rutinas de álgebra lineal enumeradas anteriormente pueden calcular resultados para varias matrices a la vez, si se apilan en la misma matriz.
Esto se indica en la documentación a través de especificaciones de parámetros de entrada como: (..., M, M) array_like. Esto significa que si, por ejemplo, se le da una matriz de entrada a.shape == (N, M, M), se interpreta como una "pila" de N matrices, cada una de tamaño M-por-M. Se aplica una especificación similar a los valores de retorno, por ejemplo, el determinante tiene det: (...) y en este caso devolverá una matriz de forma det (a) .shape == (N,). Esto se generaliza a las operaciones de álgebra lineal en matrices de dimensiones superiores: las últimas 1 o 2 dimensiones de una matriz multidimensional se interpretan como vectores o matrices, según corresponda para cada operación.
Cuando SciPy se crea utilizando las bibliotecas optimizadas ATLAS LAPACK y BLAS, tiene capacidades de álgebra lineal muy rápidas. Si profundiza lo suficiente, todas las bibliotecas LAPACK y BLAS sin procesar están disponibles para su uso para una velocidad aún mayor. En esta sección, se describen algunas interfaces más fáciles de usar para estas rutinas.
Todas estas rutinas de álgebra lineal esperan un objeto que se pueda convertir en una matriz 2-D. La salida de estas rutinas también es una matriz 2-D. Si leemos la documentación de BLAS Y ATLAS puedo notar que sus algoritmos se basan en el método de la Descompósición de Cholesky.
Rendimiento en base a la inversión de matrices

La perfomance para las matrices menores e igual a 20x20, tienen un desempeño que es casi a lo esperado; el método más eficiente lo posee numpy y el menos eficiente es el de la scipy pos overwrite, extrañamente, mi algoritmo es el segundo más rapido. Pero me llama la atención que los módulo "Scipy pos" y "Scipy pos overwrite" sean casi igual de lentos que "Scipy solve, pero analizando la situación se puede deber a que ambos "scipy pos" invierten tiempo en hacer análisis para matrices muy pequeñas y eso los retrasa (analizan la positividad y la simetría), pero a tamaños grandes el tiempo debería ser más optimizado. Otro detalle interesante, son los tiempos obtenidos para matrices de 10x10, extrañamente, el método menos eficiente es el scipy pos, que arroja resultados notablemente mayores a los demás métodos, tal cual como dije antes, debe ser por los procesos de analisis que hace, pero, como no tiene el overwrite, el proceso tampoco está optimizado, entonces, en ello se explica su alta "lentitud". Por otro lado, para los rangos de matrices mayores a 20x20 y menores e igual a 10milx10mil, los rendimientos pasan a ser consecuentes con lo esperado, el más lento es el algoritmo escrito por mí y los más rápidos son numpy con scipy pos overwrite. Del módulo scipy, el método menos eficiente es el de scipy simetric, mientras que los scipy con scipy pos y scipy overwrite tienen rendimientos con una diferencia muy pequeña.
Matrices dispersas y complejidad computacional Complejidad algoritmica de multiplicación de matrices Se presentan gráficos de rendimiento de operaciones lineales de matrices en base a distintos tamaños y algoritmos de matrices Matrices Llenas

Matrices Dispersas
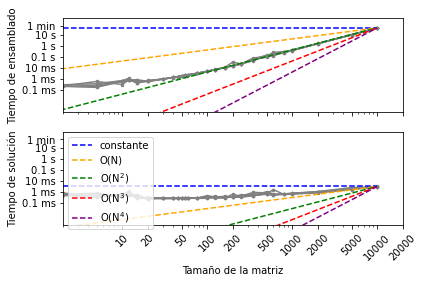
SOLVE LLENA

SOLVE DISPERSA

INV LLENA

INV DISPERSA

-
Comente las diferencias que ve en el comportamiento de los algoritmos en el caso de matrices llenas y dispersas. Para los casos de matmul y solve, el algoritmo de la matrices dispersas es mucho más eficiente. Como se puede apreciar en los gráficos, los tiempos de resolución utilizando dispersa son muchos más bajos en que los tiempos usando llena. Por otro lado, para el caso de la inversa, ocurre algo diferente, el tiempo de resolución de la matriz llena es idéntico al tiempo utilizado con matriz dispersa. En conclusión, podemos decir que utilizando la matriz dispersa se ahorra notablemente el tiempo de ejecucción para los algoritmos utilizados por python, numpy y scipy.
-
¿Cual parece la complejidad asintótica (para LaTeX: N → ∞) para el ensamblado y solución en ambos casos y porqué? Podemos notar que para el caso de MATMUL y SOLVE, la matriz llena con la dispersa tienen un tiempo de ensamblado que tiende a N^2. Por otro lado, la solución para la matriz llena tiende a N^3 mientras que la matriz dispersa tienda a N, demostrando que la dispersa es más eficiente para resolver dichos algoritmos. Respeceto a INV, las matrices llena y dispersa tienen un tiempo de ensamblado que tiende a N^2 pero para el tiempo de solución, la matriz dispersa sigue siendo más eficiente puesto que tiende a N, mientras que la matriz llena tiende a N2.
-
¿Como afecta el tamaño de las matrices al comportamiento aparente? Para el caso de las matrices laplacianas llenas, mientras más grande es el tamaño de las matrices, más lento se pone el proceso, tanto en solución como en ensamblado, es decir, aumentar el tamaño de la matriz enlentece el ensamblado en N^2 y la solución en N^3. Por otro lado, para la matriz dispersa, el tiemnpo de solución no se ve tan afectado, puesto que aumentar el tamaño de la matriz, se enlentece la solución en N. Respecto al ensamblado de la matriz dispersa, aumentar el tamaño de las matrices, enlentece el tiempo en N^2.
-
¿Qué tan estables son las corridas (se parecen todas entre si siempre, nunca, en un rango)? Como lo muestran los graficos, las matrices dispersas son mucho más estables que las llenas. Para los casos MATMUL y SOLVE, el comportamiento de la matriz dispersa es practicamente igual en todo >=10. Por otro lado, el comportamiento de la matriz llena en todos los casos es bastante inestable, sobretodo en el rango perteneciente a [10,100]. Las graficas de las operaciones con matrices llena no se parecen en nada a las gráficas de las matrices dispersas.
from numpy import zeros,double
import numpy as np
from scipy.sparse import lil_matrix,eye
def matriz_laplaciana_llena(N, t = np.float32):
e = np.eye(N)-np.eye(N,N,1)
return t(e+e.T)
def matriz_laplaciana_dispersa(N,t=np.float32):
A = lil_matrix((N,N))
for i in range(N):
for j in range(N):
if i == j:
A[i,j] = 2
if i+1 == j:
A[i,j] = -1
if i-1 == j:
A[i,j] = -1
return A