Hello, my name is Sophie Wang and I'm receiving a Master's Degree in Data Science at University of San Francisco. This is the individual project I completed for Distributed Computing course.
Activity Recognition using smartphone and smartwatch data in Apache Spark
In this repository, you will find all my python script code as well as corresponding jupyter notebook where you can see all the intermediate results printed.
The dataset used is from 'UCI WISDM Smartphone and Smartwatch Activity and Biometrics' which contains information collected by gyroscopes or accelerometers of smartphone and smartwatch. The goal is to classify and recognize human activity categories by applying machine learning techniques in a distributed computing setting (SparkML and Spark+H2O).
The project consists of six parts (including EDA and machine learning):
- Load all data from subfolders at once as RDDs.
- Remove all the null values
- Convert RDDs to Spark dataframe
- Join the activity code dataframe with sensor info dataframe
- Identify which activity is related to eating
- Check the number of activity types for each device, sensor and user
- Check the min, max, std, percentiles of the readings from gyroscopes or accelerometers
- Encode the categorical column by first applying StringIndexer and then OneHotEncoder
- Combine all the feature columns using Vector Assembler
- Scale the assembled features by StandardScaler
- Divide the dataset into training (80%) and test set(20%)
- Fit a logistic regression model with cross validation
- Check the evaluation metric areaUnderROC on the test set (0.611)
- Fit a random forest classifier model with cross validation
- Check the evaluation metric areaUnderROC on the test set (0.803, much better than the logistic regression)
- Fit a gradient boosted tree classifier model with cross validation
- Check the evaluation metric areaUnderROC on the test set (0.933, better than the random forest classifier)
(note: part 3-4 uses SparkML, part 5-6 uses Sparkling Water--H2O with Spark)
- Fit a H2O gradient boosted tree classifier model with cross validation
- Check the evaluation metric areaUnderROC on the test set (0.866)
- Fit a H2O deep learning model with cross validation
- Check the evaluation metric areaUnderROC on the test set (0.945)
- Apply AutoML on the dataset and return the leaderboard
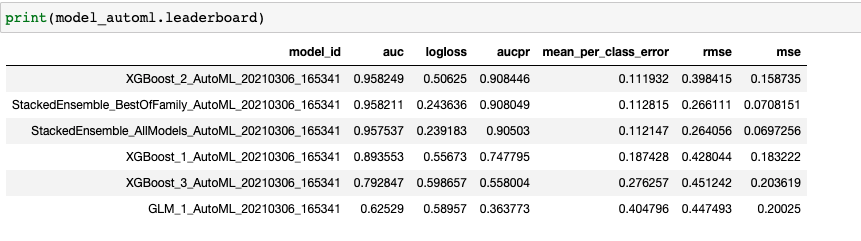
- Fit the leader model from the screenshot above and check the evaluation metric areaUnderROC on the test set (0.9597, highest score so far!)
By comparing Spark ML and H2O, H2O is much easier to use since it takes care of all the data-preprocessing steps automatically (StringIndexer, OneHotEncoder, Vector Assembler, StandardScaler). The AutoML in H2O package is even simplier since it automatically search for the best performing algorithm and provide a lot of model interpretation visualizations (feature importance for example). Note: If you want to use H2O instead of Spark ML, you have to convert Spark dataframe (row-based) to H2O Frame (column-based).