cabbage是一个分布式的任务调度框架,现在以实现动态添加机器,动态扩容队列,动态实现任务的布置与删除
启动,下载源码zip包,解压缩,进入目录编辑 cabbage.cfg 配置文件,如下:
[base]
#zookeeper服务,多个地址以,号分割,如:10.0.137.24:2181,10.0.137.25:2181,10.0.137.28 2181,zookeeper任务协调,数据保存,新节点发现等
zookeeper=172.16.4.134:2181
#rabbitmq 配置信息,如果没有vhost,使用cabbage/bin/clean_queue.sh创建即可
connectUri=amqp://cabbage_celery:cabbage_celery@172.16.4.134:5672/cabbage_vhost
#选用hdfs为存储时的存储目录如:/user/cabbage/jobId
hdfsRootPath=/user/cabbage
#hdfs 上传路径
hdfsUrl = http://10.0.137.24:50070
#NFS 文件共享系统路径
nfsDirectory=/Users/hua/workspace/python/cabbage/data
#文件多久上传一次,默认每小时传一次,最好每小时传一次,因为一个小时只会产生一个文件
resultUploadScheduler=10 * * * *
#每个节点多少给子进程来跑任务,有些节点机器配置比较好,可以多点进程
celerydConcurrency=1
#web端地址,文件服务器地址
serverIp=172.16.4.1
#节点之间通讯的短裤
serverPort=1024
#管理的端口
serverWebPort=2048
#好像没有用
uploadHdfsFileProcessCount=10
#好像没用用
jobExecutorCount=2000
#用户上传的任务在服务器端的存放地址
serverFileDirectory=/Users/hua/workspace/python/cabbage/server_file_path
#节点在服务器上将任务同步回来存放的路径
clientFileDirectory=/Users/hua/workspace/python/cabbage/client_file_path
# 日志配置文件路径
logConifgPath=/Users/hua/workspace/python/cabbage/logging.cfg
# 错误任务文件存放路径
taskFailLogPath=/Users/hua/workspace/python/cabbage
# web管理员名称
adminName=admin
# web管理员密码
adminPwd=123456
设置好配置文件,进入bin目录,执行:cabbageServer.sh,待控制台打印 系统初始化完成!,打开浏览器,访问**http://127.0.0.1:2048/**,输入用户名和密码,即可登录WEB管理系统。
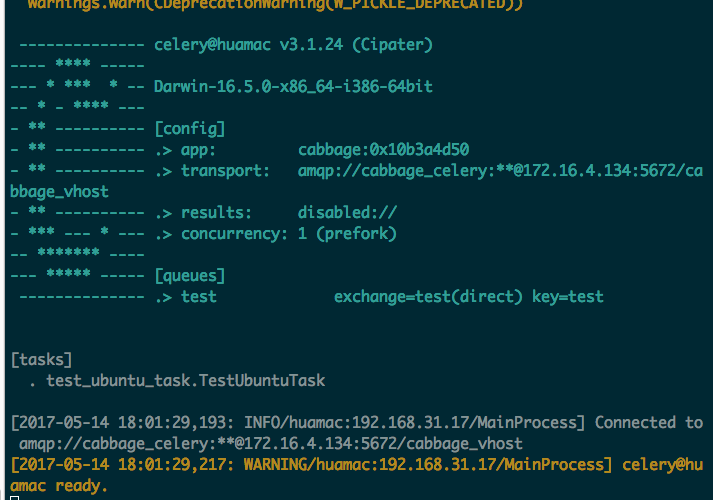
设置好配置文件,进入bin目录,执行:cabbageClient.sh,待控制台打印 ready.!,即代表客户端已经启动。
创建 test_ubuntu_main.py 文件,拷贝下面的代码:
# -*- encoding: utf-8 -*-
'''
Created on 2016年7月4日
@author: hua
'''
from __future__ import absolute_import
from cabbage.cabbage_celery.main import CabbageMain
from zope.interface.declarations import implementer
from test_ubuntu_task import TestUbuntuTask
import time
class TestUbuntuMain(CabbageMain):
def run(self,*args,**kwargs):
# print args
# print kwargs
print self.getApp()
print self.job
print self.job.brokerServer
print self.getApp().tasks
print "CELERY_ROUTES:[%s]" % self.getApp().conf["CELERY_ROUTES"]
self.apply_async(TestUbuntuTask,(1,2,args[0]),expires=5)
创建 test_ubuntu_task.py 文件,拷贝下面的代码:
# -*- encoding: utf-8 -*-
'''
Created on 2016年7月4日
@author: hua
'''
from cabbage.cabbage_celery.main import CabbageMain
from cabbage.cabbage_celery.task import CabbageTask
from zope.interface.declarations import implementer
def sayHello():
print "hello world!"
class TestUbuntuTask(CabbageTask):
def doRun(self,aaa=1,bbb=2,no=None):
print "NO:%s"%no
# print "加料"
print aaa,bbb
print sayHello()
return aaa * bbb
登录系统**http://127.0.0.1:2048/**,进入**队列服务器管理>队列服务器(集群)管理,点击添加队列服务器**,如下图:
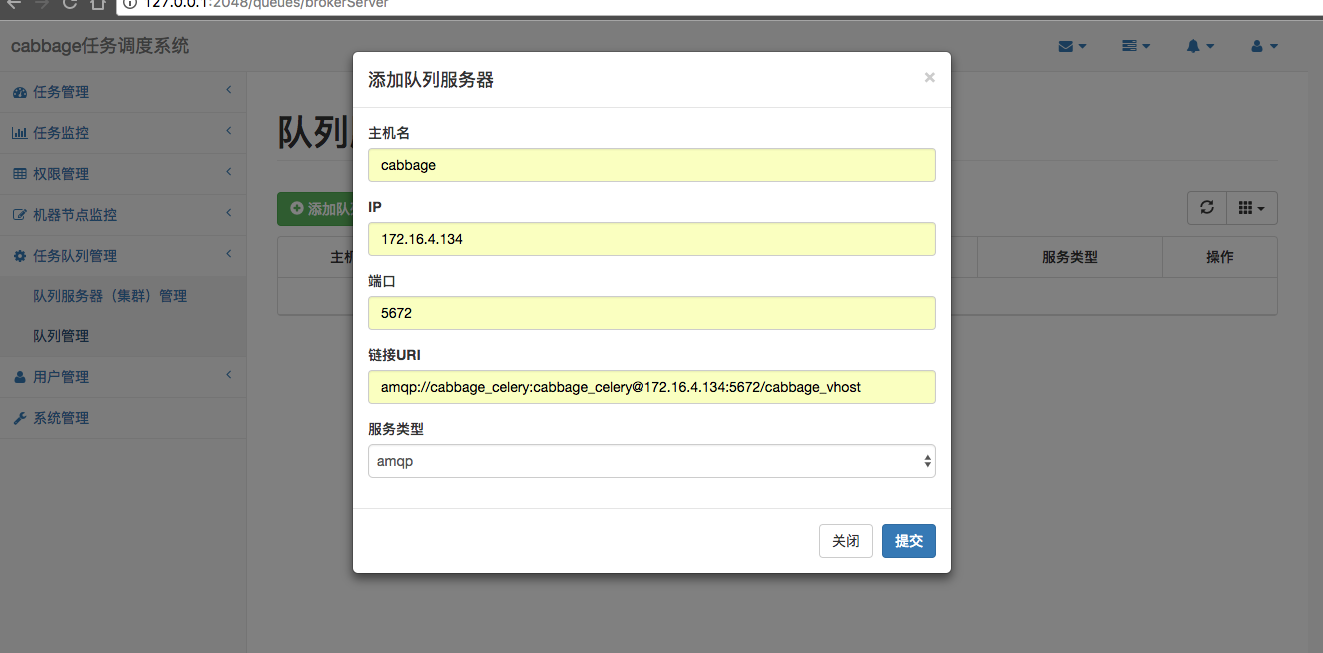 点击提交后:
点击提交后:

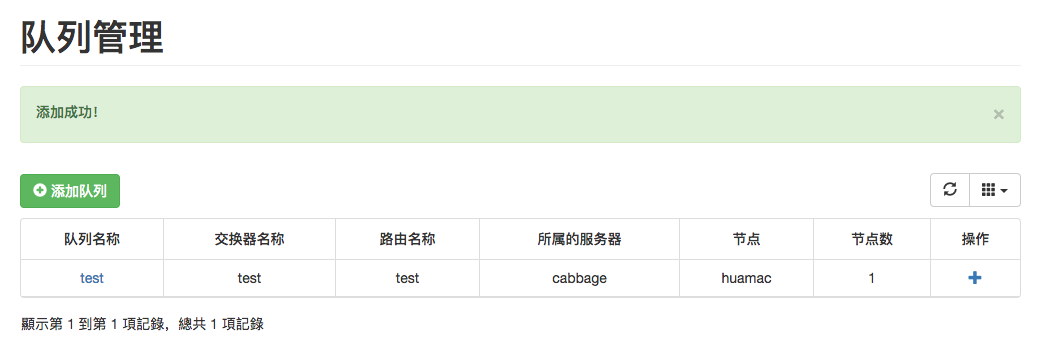
进入队列服务器管理>队列管理,点击添加队列,如下图:
 点击提交后:
点击提交后:
 客户端控制台输出添加队列后的记录:
客户端控制台输出添加队列后的记录:
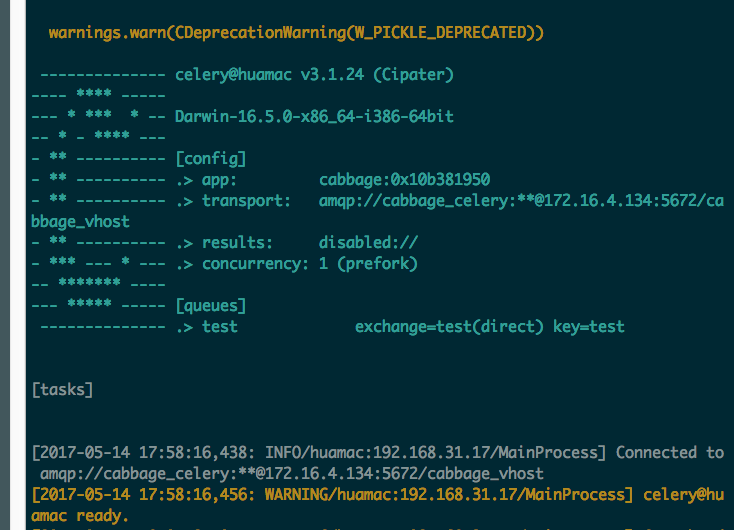
即可看到新添加的队列已经成功,但是还没有任务提交在系统中,下面我们将添加我们的第一个任务,并执行该任务。
登录系统**http://127.0.0.1:2048/**,进入**任务管理>新建任务,输入参数,提交任务,如下图:
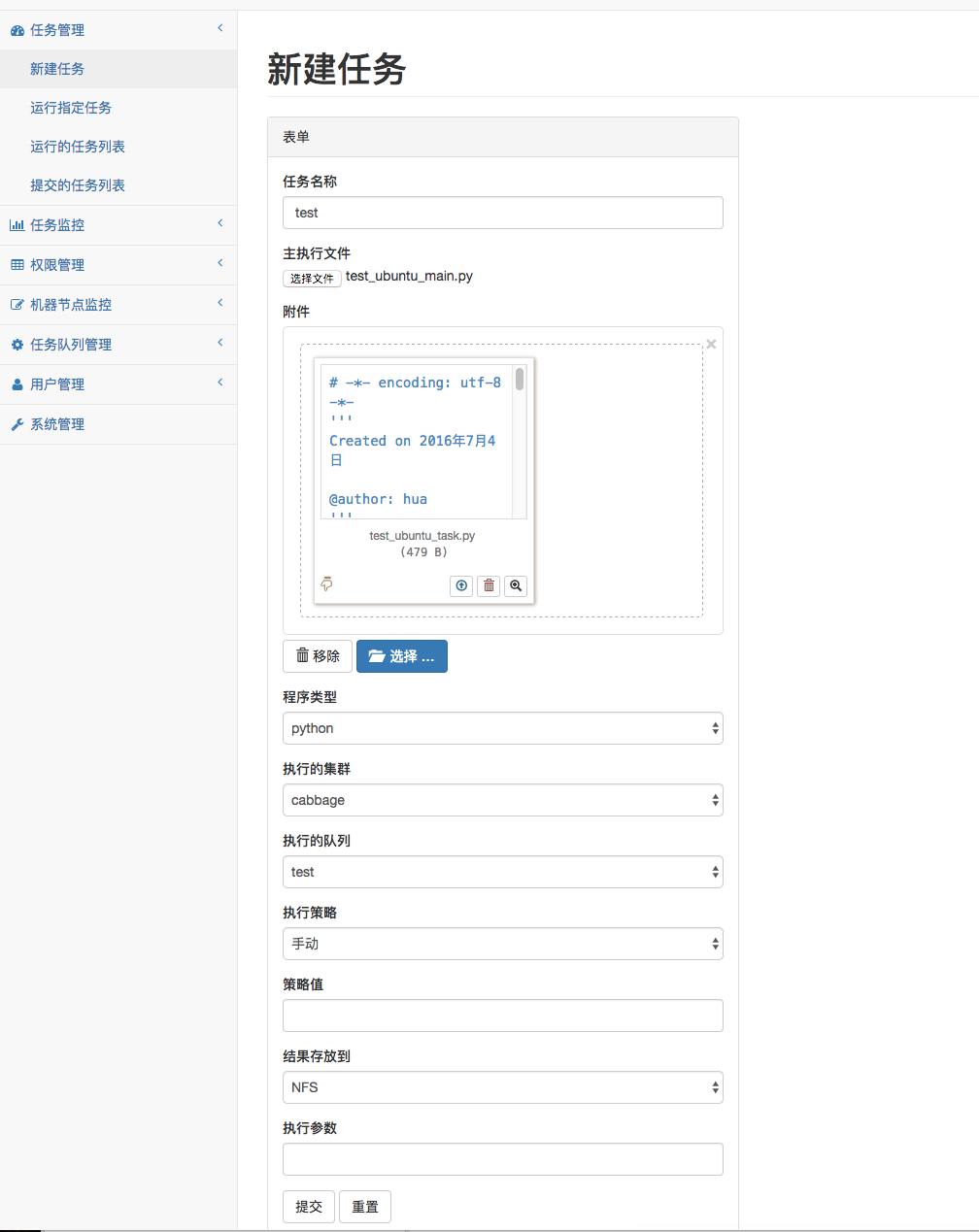 客户端控制台输出添加任务后的记录:
客户端控制台输出添加任务后的记录:
 即可看到新添加的任务已经成功的提交到系统中,添加任务成功后,界面将输出该任务的JOBID。
即可看到新添加的任务已经成功的提交到系统中,添加任务成功后,界面将输出该任务的JOBID。
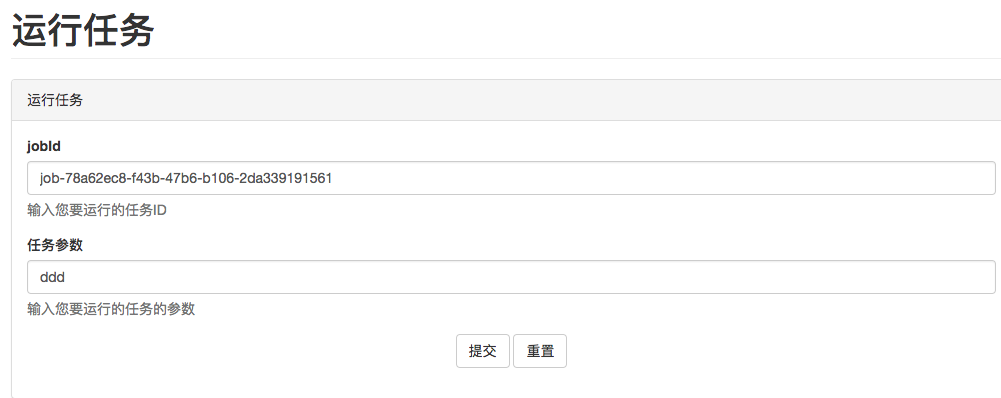
登录系统**http://127.0.0.1:2048/**,进入**任务管理>运行指定任务,输入JOBID和参数,如下图:
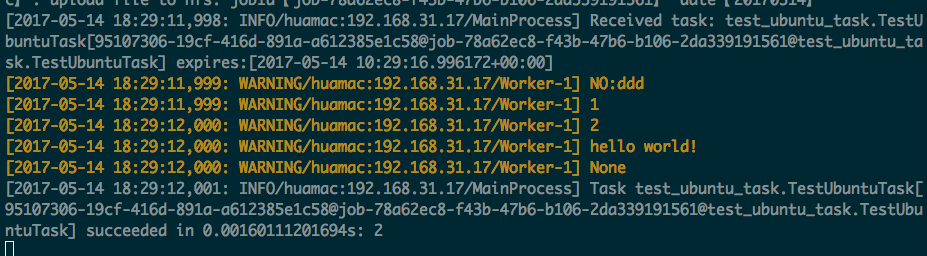
 客户端控制台输出任务执行后的记录:
客户端控制台输出任务执行后的记录:
公司应用的最大的一个集群,其余几个也有4,5十台机器,专门用来采集网络上的数据:
