陆续使用Scrapy已经快两年了, 感觉非常方便, 业务上已经没有什么难度了, 准备开始看源代码, 了解他的实现, 以达到从底层进行优化。
读后感: 已经基本看完, 没有特别深入, 只详细看了核心相关的代码。 感觉scrapy真心不错, 可以快速架构抓取, 已经完全满足我的工作需要。
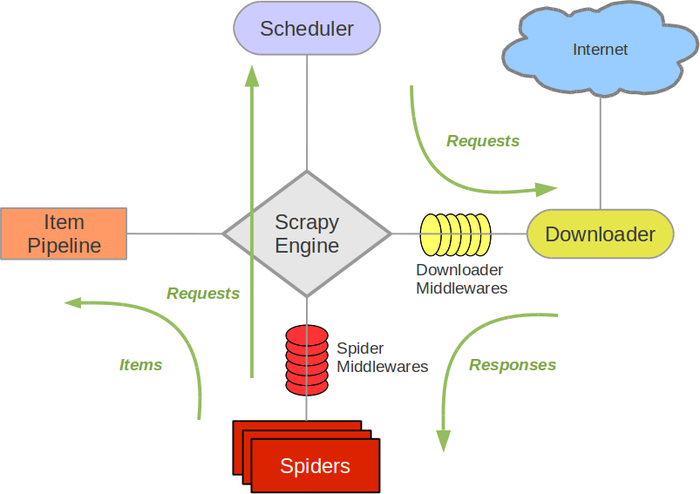
- CrawlerRunner 在一个进程内运行一个爬虫
- CrawlerProcess 在一个进程内同时运行多个爬虫,继承CrawlerRunner
- Crawler 爬虫 运行爬虫方法如下:
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
self.spider = self._create_spider(*args, **kwargs)
self.engine = self._create_engine()
start_requests = iter(self.spider.start_requests())
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
raisescrapy.spider.Spider
- Crawl scrapy.contrib.spiders.crawl.CrawlSpider
- Feed scrapy.contrib.spiders.feed.XMLFeedSpider、 CSVFeedSpider
- SiteMap scrapy.contrib.spiders.sitempa.SitemapSpider
scrapy.http.request.Request
scrapy.core.engine.ExecutionEngine
优先使用DISK QUEUE, 如果JOBDIR未设置, 则使用MEMORY QUEUE
如果需要实现分布式抓取可以自定义一个任务调度器, 使用数据库或消息队列(zmq、rabbitmq、redis等)来做Request去重和任务调度。
- scrapy.dupefilter.RFPDupeFilter
Request去重算法request_fingerprint, URL的GET参数会做重新排序(如:b=1&a=2会转成a=2&b=1), 并使用sha1生成唯一URL 如果有配置JOBDIR, 则会将URL数据保存至requests.seen文件中, 下次打开时会加载至内存 RFPDupeFilter一般使用没问题, 但是URL多了, 如上百万时, 将会很占内存, 可以使用Bloom Filter算法
- BaseDupeFilter
scrapy.squeue.PickleLifoDiskQueue
scrapy.squeue.LifoMemoryQueue
scrapy.signalmanager.SignalManager
scrapy.spidermanager.SpiderManager
自定义配置SPIDER_MODULES,所有自定义的蜘蛛模块
scrapy.spider.Spider
执行所有中间件的open_spider和close_spider方法
scrapy.middleware.MiddlewareManager
中间件管理器初始化方法from_crawler、from_settings,代码里middleware简写成mv 中间件初始化方法from_crawler、from_settings、init, 代码如下:
mwcls = load_object(clspath)
if crawler and hasattr(mwcls, 'from_crawler'):
mw = mwcls.from_crawler(crawler)
elif hasattr(mwcls, 'from_settings'):
mw = mwcls.from_settings(settings)
else:
mw = mwcls()
middlewares.append(mw)scrapy.extension.ExtensionManager
基本扩展在配置EXTENSIONS_BASE, 自定义配置为EXTENSIONS
scrapy.core.spidermw.SpiderMiddlewareManager 执行所有蜘蛛的process_spider_input、process_spider_output、process_spider_exception和process_start_requests
SPIDER_MIDDLEWARES = {}
SPIDER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.contrib.spidermiddleware.httperror.HttpErrorMiddleware': 50,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': 500,
'scrapy.contrib.spidermiddleware.referer.RefererMiddleware': 700,
'scrapy.contrib.spidermiddleware.urllength.UrlLengthMiddleware': 800,
'scrapy.contrib.spidermiddleware.depth.DepthMiddleware': 900,
# Spider side
}scrapy.contrib.pipeline.ItemPipelineManager 执行所有Item通道的process_item方法