Predicting music tastes from unrelated interests. A data science project.
Aim:
- Use machine learning to classify music fans on Reddit by their preferred music genre, based on which subreddits (Reddit subforums) unrelated to music the user contributed to.
- A fan is defined as a user who posted in subreddits related to one genre and not in subreddits of other genres.
- The problem is restricted to binary classification. Fans labelled Hiphop and RockMetal are classified, though Classical and Electronic were also tracked.
- Select two models to compare performance between. One should be simple, and easily interpreted, while the other can test whether gains in classification accuracy can be made by a relatively complex or uninterpretable model.
Data source: Reddit user Stuck_In_the_Matrix made available a database of every public Reddit comment. Kaggle picked up on this and are hosting the comments from May 2015, which was used here.
Coding tools: Python 2 with modules numpy, scipy, scikit-learn, sqlite3, matplotlib, seaborn, graph-tool. Vim with tmux. IPython.
The SQL source has 54,504,410 rows, and each is a unique comment. The columns are comment attributes, including user name and subreddit. After significant data processing, an array of features X was produced. Its rows are music fans, and its columns are subreddits unrelated to music. Each cell takes a boolean value; True if the fan posts in the subreddit. The top 2000 subreddits were tracked as features. An array Y records the outcomes; each fans preferred genre. The data was balanced on outcome in order to tackle the interesting case of maximum information entropy.
Below, the data is shown projected onto a single linear component, the direction of maximum class separation, found by Linear Discriminant Analysis (LDA).

Two datasets are shown, each with their own linear discriminant: one is the full set, with all fans who posted in any of the top 2000 non-music subreddits, and the other only shows fans who posted in at least 20 non-music subreddits. The full set has 17,878 fans per class, but the ≥20 set has just 1,795.
Key insights:
- The class distributions have a single mode and are approximately Gaussian along this linear component, with differing means. This difference between classes highlights that there is information about music taste encoded in fans' unrelated interests.
- Classification in the ≥20 set is about 90% accurate by eye, which supports the applicability of linear modelling to this problem. This places an extremely optimistic upper limit of 90% on LDA classification accuracy for the ≥20 set, since the test data was also the training data.
- The lack of distinction between the classes on the full dataset hints that the best algorithm may only be a humble improvement from the 50% coin-flipping approach, for the less prolific Reddit posters.
The features are:
-
Highly correlated and anticorrelated (because features are proxies for users' interests)
This hurts model interpretability. Solutions will not be unique and interactions between predictors can produce unintuitive results.
-
Sparse
The most popular subreddit was posted in by 42.18% of fans, but the mean and median by just 0.42% and 0.14%, respectively. The lack of training examples may cause difficulty extracting useful information from these less popular subreddits.
-
Numerous (high-dimensional problem)
The configuration space of 2000 binary variables accepts
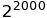 unique states. Depending on the relative weights of these states, we should expect each unseen sample to be novel. A non-parametric algorithm may struggle with this. Linear models may be able to fit an approximate solution, if linearity can approximate the target function.
unique states. Depending on the relative weights of these states, we should expect each unseen sample to be novel. A non-parametric algorithm may struggle with this. Linear models may be able to fit an approximate solution, if linearity can approximate the target function.
The graph below shows how classification success with the standard logistic regression algorithm varies as increasingly sparse predictors are introduced. Note that the secondary Y-axis is truncated. The algorithm makes no accuracy gains past the first 40% most popular subreddits, despite the fact that about 5% of fans don't post in these. It is unlikely that the latter 60% of subreddits provide no information. Instead, model bias is likely being traded off for variance, as the less important features increase the model complexity.

These observations, and the intuition that many of these features should have extremely similar behaviour in the limit of a very large number of samples, suggest that grouping features through a latent variable model should be possible with minimal loss of information.
Both approaches assumed a smaller set of latent variables underpin the distinction between classes. After transformation of the input X, both models relied on logistic regression for classification. The two approaches to dimensionality-reduction were:
-
Feature agglomeration: A very simple, custom feature agglomeration scheme was used. The list of features was sorted by phi coefficient with the outcome. The list was sliced into N equal groups. Within groups, features were summed to produce a single integer value. Logistic regression was then used to fit this lower-dimensional dataset.
The scheme is rather coarse, and one can easily conceive refinements. However, it will be interesting to see whether this simple approach can produce a stable model of similar accuracy to logistic regression on the raw dataset.
-
Bernoulli restricted Boltzmann machine (BRBM): The BRBM expects binary inputs ("visible units") and, after training, transforms these to N latent factors ("hidden units"). Learning is unsupervised; the RBM is trained to reconstruct the visible units from a set of on/off states of its hidden units. This makes the tool more analagous to principal component analysis than linear discriminant analysis: There is no guarentee that the hidden variables learned are a good choice for discriminating the outcomes.
Models were measured using K-folds testing with K = 4.
Below, prediction accuracy and model stability are shown as a function of N, the number of predictors in the transformed scheme. These are contrasted to the benchmark performance of logistic regression. Performace accuracy is also shown for the ≥20 data subset, in which the ~90% of fans who posted in under 20 unique subreddits were excluded. These data were tested on the same model as the full dataset; no new training occurred.

Here, the benchmark performance is identically equal to agglomeration with N = 2000. The scheme reaches parity with standard logistic regression at just N = 15, and overtakes at larger N. Agglomeration incurs information loss, but protects the model from over-training on the outliers in the training set. The best balance between these two effects is either the peak at N = 100, or in the range 140 < N < 2000.
The accuracy here lags behind the standard logistic model, but makes gains as N increases. This may signify that these data were already protected from the effect of over-training, and merely suffer increased misclassification when information is masked by predictor agglomeration. The performance on this subset may be enhanced via smarter predictor grouping, such as including predictor covariance or using an intuition unavailable to the algorithm about which subreddits ought to have the same behaviour (e.g. subreddits like 'hockey' and 'hockeyplayers').

Models were trained at 10-unit intervals. The RBM models fail to reach accuracy parity with logistic regression on the original dataset, in the range studied. This shows that the hidden units, trained to minimally represent the 2000-predictor input data, do not effectively capture properties which discriminate the two classes. In other words, there are stronger patterns in the data than those which separate the classes. In such a case, unlabelled dimensionality-reduction preprocessing is not useful.
Unlike the feature agglomeration model, the model is least stable at low N, and becomes increasingly stable as N grows. This may be because the RBM models' hidden units can receive input with the same sign (positive or negative) from predictors with opposing correlations with the outcome, leading to a great deal of noise in training on sparse data. If this is correct, the fall in fluctuations could come from this scenario becoming less likely as N rises.
Each model transformed the features and then used logistic regression. This graph summarises the prediction accuracy achieved through each approach to feature transformation.
| Model | Peak accuracy | Parameters at peak |
|---|---|---|
| Exclusion of the sparsest predictors | 66.9% | 55% of features excluded |
| Feature agglomeration | 67.4% | 105 agglomerated features |
| Restricted Boltzmann Machines | 66.1% | 130 hidden units |
The output of the selected models is compatible with the expectation of a low ceiling on prediction accuracy; no model reached 68% accuracy on the full dataset.
The peak accuracy of the feature agglomeration method was greater than for the simple linear regression approach. This demonstrates that, rather than disregarding the most sparse predictors due to the variance they introduce, predictors can be simply grouped to create a lower-complexity model which retains some of the predictive power of the most sparse features.
The RBM model approach was not competitive with the other approaches in the range tested, and it was suggested that this is because the learned features were far from optimally discriminative on the classification problem. This motivates the need for Discriminative RBMs, which ensure that the learned features are discriminative.
A graph featuring a small number of the top subreddits among fans is shown. Click it for a larger version.

- Vertex diameter is proportional to the log of the number of fans who post.
- Red subreddits predict hiphop according to the agglomeration model, and blue predict rockmetal.
- Edge thickness is proportional to the absolute number of fans posting in both subreddits.
All code is in the top-level directory.
- main.py - Driver. In its current state, will produce the graphical output in this README.
- get_dataset_SQL.py - Functions to create the X, Y database from SQL source.
- manipulate_data.py - Post-processing tools for the X, Y arrays.
- subreddits.py - Music subreddits by genre and exclusion list of all music subreddits.
- pickles - Time-saving variable serialisations for producing the main dataset and graphs.
- README_figs - Figures in this readme, in SVG format.