(TensorBoard 
A Tensorboard plugin to explore reinforcement learning models at the timestep level. A project by Andrew Schreiber and Fabian Steuer.
The goal of the Atari game Enduro is to pass other cars without colliding. We've trained two models, one trained on 3000 episodes and the other trained on 10 episodes, which will be visualized using Agent.
The perturbation saliency heatmap below is generated by a process of measuring where blurs of the Atari frame produces a large change in what the model estimates the expected reward of the frame to be. Where you see blue overlay is where the model is 'paying attention'. See this paper for more details.
What do you notice from these 20 frames? (Advanced tip: download the gifs and step through each frame)
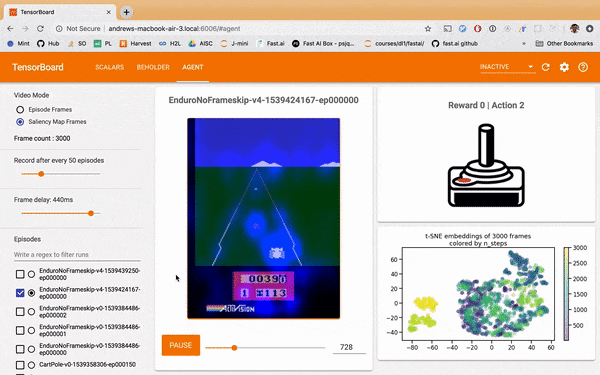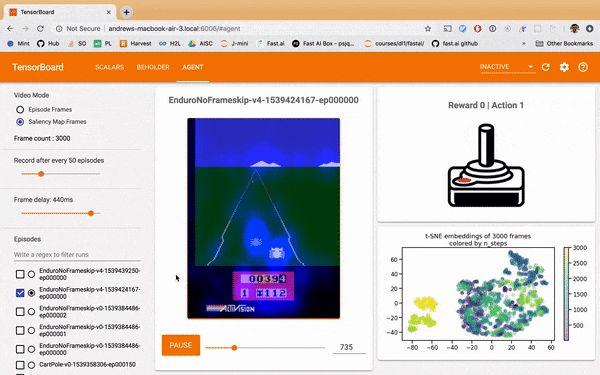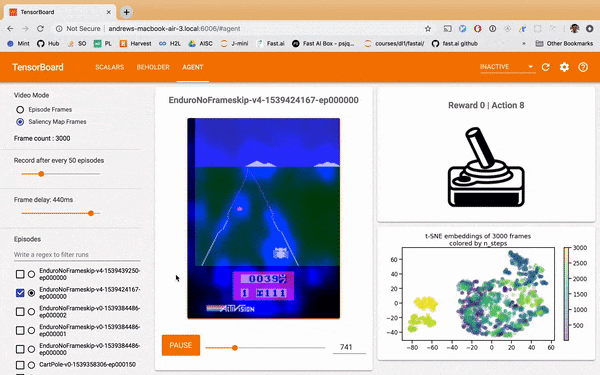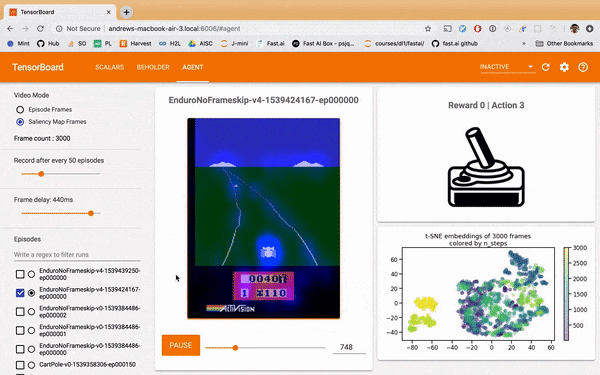

One observation is that that the well-trained model adjusts itself substantially on the cars, especially when the agent's car coming close to passing another car. Meanwhile the untrainted model doesn't place much attention on the cars specifically, rather it's attention meanders randomly across the screen.
Why is this interesting? Perhaps it had turned out the well-trained model was barely paying attention to the cars at all. That would mean the 'expert' had learned some trick undiscernable to humans in it's environment, which may not generalize or be otherwise problematic from a safety perspective. A loss or averaged rewards graph would not permit you this insight; your metrics would simply tell you the model had learned well.
http://li592-70.members.linode.com:6006/#agent
It's surprisingly difficult to understand why a reinforcement or inverse reinforcement learning agent makes a decision today.
At distill.pub we have seen impressive techniques and tooling emerge for interpreting supervised learning beyond summary statistics. Why do we find a void of usable, open-source interpretability techniques for reinforcement learning? Victoria Kraknova made a well-reasoned call for more research in deep RL interpretability for AI Safety at a NIPS workshop a year ago. It seems there is much to be explored about why a RL agent choses actions moment-by-moment and that such work would be valuable for debugging and understanding, yet the subfield has published little since 2017. What is causing the paralysis?
We observe a primary bottleneck is misfitted tooling. From experience, the current process to extract and save the relevant network activations and episode frames is laborious and complex. Even if you succeed, the technique(s) you build tend to be tightly-coupled to your project (see this group who made a compelling deep RL intepretability tool, but to use it you have to be running their version of Lua and Windows 10).
We find the above state of affairs frustrating for a subfield of technical AI Safety potentially ripe with low-hanging fruit. We believe RL and IRL research would be safer if the field had a well-documented platform for intepreting agents using standard, popular tools (Unix, Python, Tensorflow, Tensorboard).
The purpose of Agent is to accelerate progress in deep RL/IRL intepretability. We are very interested in perspectives from people in the intepretability, deep RL/IRL, and AI Safety communities. Please share your feedback through GitHub issues.
Agent v0 targets Dec 1st with two deep learning interpretability techniques, t-SNE and saliency heatmaps, which we hope will prove immediately useful. v0 will include an API you can integrate into your new or existing RL model training code.
Agent v1 scope is still under development. For researchers with fresh insight into RL intepretability, Agent v1 aims to support custom visualizations with the aim to reduce the overhead in developing new techniques by an order of magnitude. Furthermore we aim for documentation and examples to make it straightforward to get started. Test coverage and a basic style guide for maintainability.
Agent was built in Python within Tensorboard due to the visualization suite's robustness and popularity among researchers. We hope someday Agent could be merged into Tensorboard itself like the Beholder plugin.
Packages required (recommended version):
Python virtual environment (v3.6)
Bazel build tool from Google. Install guide in link. (v0.21.0)
Tensorflow (v1.13.1)
Then:
git clone https://github.com/andrewschreiber/agent.git
cd agent
# Install API layer in your Python virtual environment
pip install .
#Build takes ~7m on a 2015 Macbook
bazel build tensorboard:tensorboard
#Use the custom tensorboard build by running
./bazel-bin/tensorboard/tensorboard --logdir tb/logdirectory/logs
To visualize training, use the following command to setup Baselines to send tensorboard log files.
export OPENAI_LOG_FORMAT='stdout,log,csv,tensorboard' OPENAI_LOGDIR=logs
Return to the original terminal tab, at the root of rlmonitor, and run your training:
python -m baselines.run --alg=deepq --env=CartPole-v0 --save_path=./cartpole_model.pkl --num_timesteps=1e5
Go to the linked URL in the tensorboard tab to see your model train.
cd examples/baselines
Follow instuctions from https://github.com/andrewschreiber/baselines to install Gym. Then:
Train a model:
python -m baselines.run --alg=deepq --env=CartPole-v0 --save_path=./cartpole_model.pkl --num_timesteps=1e5