This repository is an evaluation of Kingma's "ADAM: A Method for Stochastic Optimization" adam optimizer and others.

- tensorflow 1.13.1
- pickleshare 0.7.4
- numpy 1.15.2
- unicodecsv 0.14.1
- matplotlib 2.2.2
- seaborn 0.9.0
- Models: logistic regression, neural network (3 FC layers), and convolutional neural network (3 Conv layers + 2 FC layers)
- Optimizers: SGDNestrov, AdaGrad, RMSProp, AdaDelta, and Adam
- Dataset: MNIST and CIFAR10
- With/without dropout
- Same weight initialization for all models and optimizers
- Nonlinear decreasing learning rate control
- Objective functions: L2 norm for logistic regression, and softmax-cross entropy with regularization term for neural network and convolutional neural network
- Whitening: option only for Cifar10


This implementation uses MNIST and CIFAR10 dataset. Both datasets can be downloaded automatically.
.
│ Adam-TensorFlow
│ ├── src
│ │ ├── cache.py
│ │ ├── cifar10.py
│ │ ├── dataset.py
│ │ ├── download.py
│ │ ├── main.py
│ │ ├── mnist.py
│ │ ├── models.py
│ │ ├── solver.py
│ │ ├── tensorflow_utils.py
│ │ └── utils.py
│ Data
│ ├── mnist
│ └── cifar10
Use main.py to train the models. Example usage:
python main.py
gpu_index: gpu index if you have multiple gpus, default:0model: network model in [logistic|neural_network|cnn], default:cnnis_train: training or test mode, default:False (test mode)batch_size: batch size for one iteration, default:128is_train: training or inference mode, default:Trueis_whiten: whitening for CIFAR10 dataset, default:Falselearning_rate: initial learning rate for optimizer, default:1e-3weight_decay: weight decay for model to handle overfitting, default:1e-4epoch: number of epochs, default:200print_freq: print frequency for loss information, default:50load_model: folder of saved model that you wish to continue training, (e.g. 20190427-1109), default:None
Use main.py to test the models. Example usage:
python main.py --is_train=False --load_model=folder/you/wish/to/test/e.g./20190427-1109
Please refer to the above arguments.
The visualizaiton includes training (batch) and validation accuracy for each epoch and loss information during training processs.

The visualizaiton includes training (batch) and validation accuracy for each epoch, and total loss, data loss, and regularization term during training are also included.
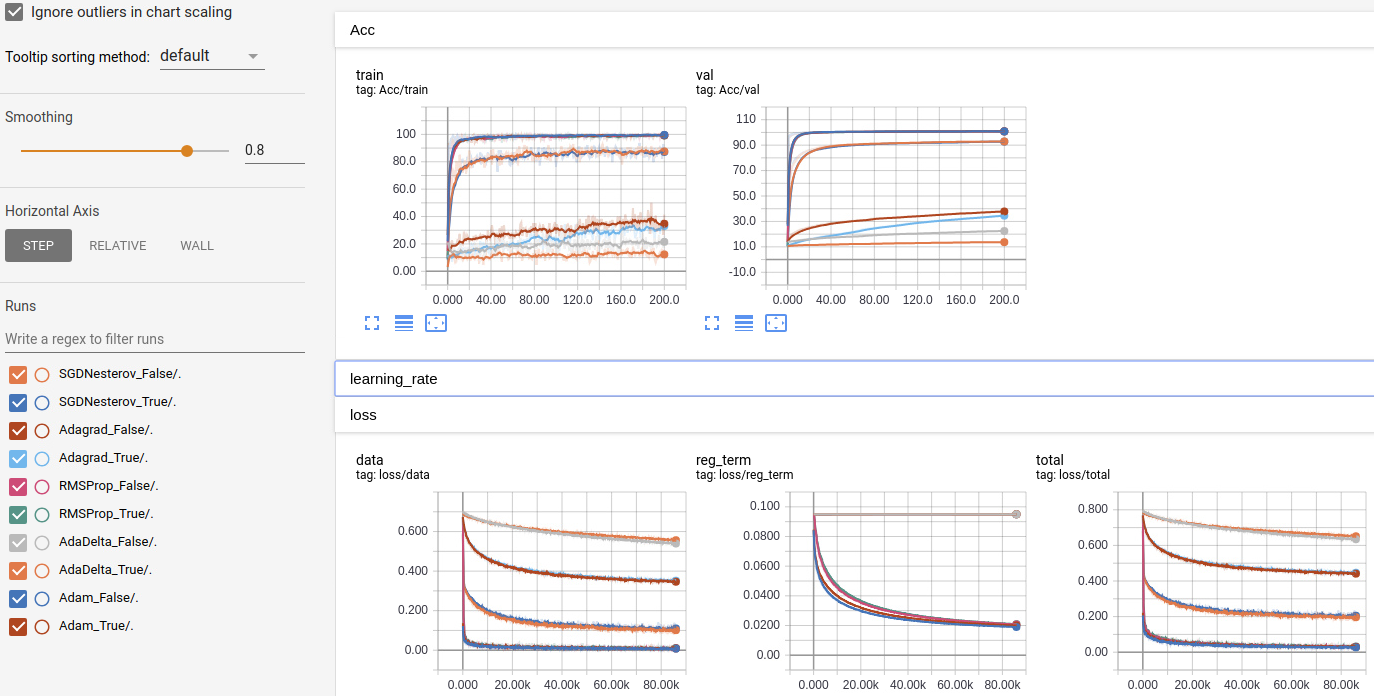
The visualizaiton includes training (batch) and validation accuracy for each epoch, and total loss, data loss, and regularization term during training are also included.

- Adam is the most stable optimizer for all models
- RMSProp is comparable with the Adam, RMSProp maybe better for some models and datasets
- Dropout gives the instability for the training process, but it is helpful to handle overfitting
- The performance of the whitening (data preprocessing) for Cifar10 is worse than subtracting mean data-preprocessing
- Whitening for training data and subtracting mean for test data improves performance at least 10%, but the reason is not thoroughly analyzed (I will further figure out what is the reason)
@misc{chengbinjin2019Adam,
author = {Cheng-Bin Jin},
title = {Adam-Analysis-TensorFlow},
year = {2019},
howpublished = {\url{https://github.com/ChengBinJin/Adam-Analysis-TensorFlow},
note = {commit xxxxxxx}
}