#Deep Learning for Visual Question Answering
Click here to go to the accompanying blog post.
This project uses Keras to train a variety of Feedforward and Recurrent Neural Networks for the task of Visual Question Answering. It is designed to work with the VQA dataset.
Models Implemented:
-
A Feedforward Model
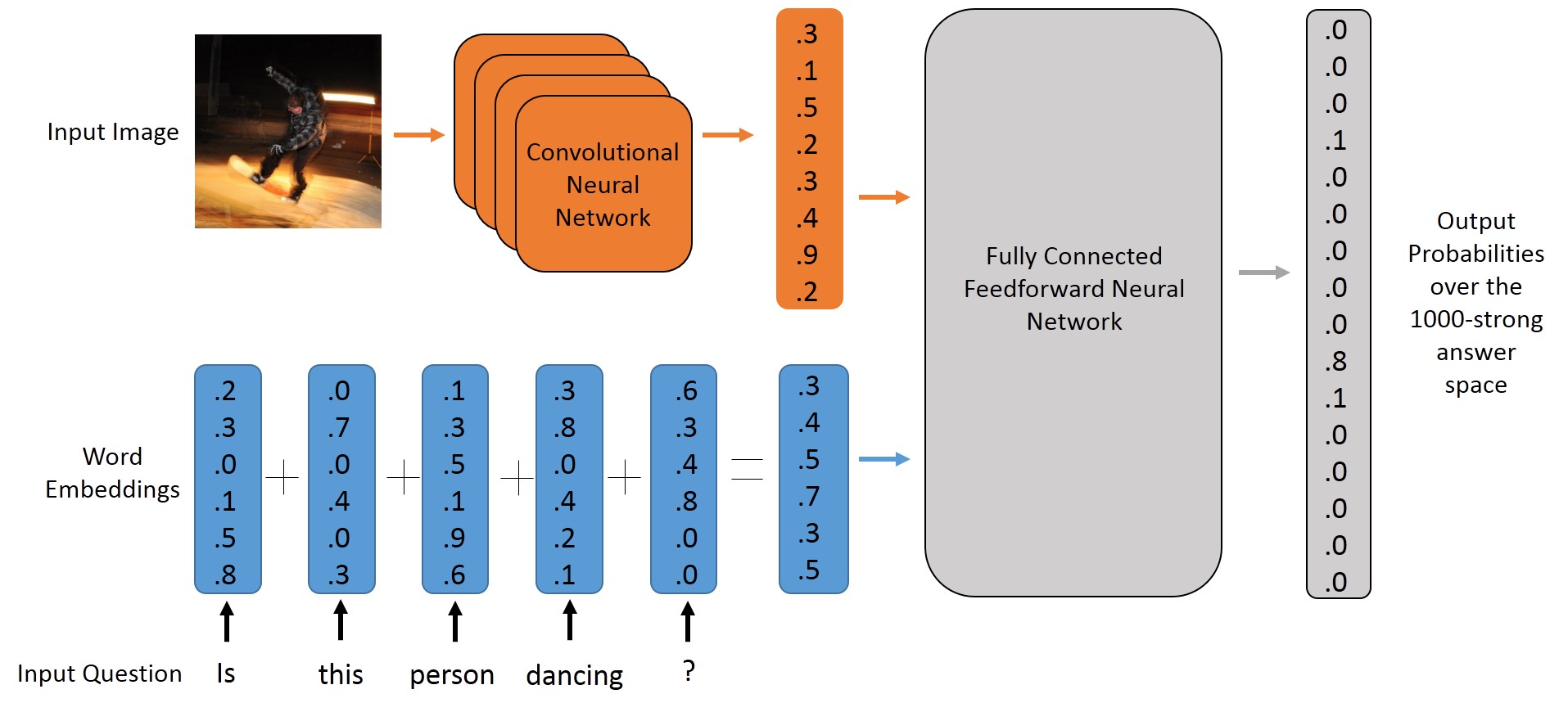
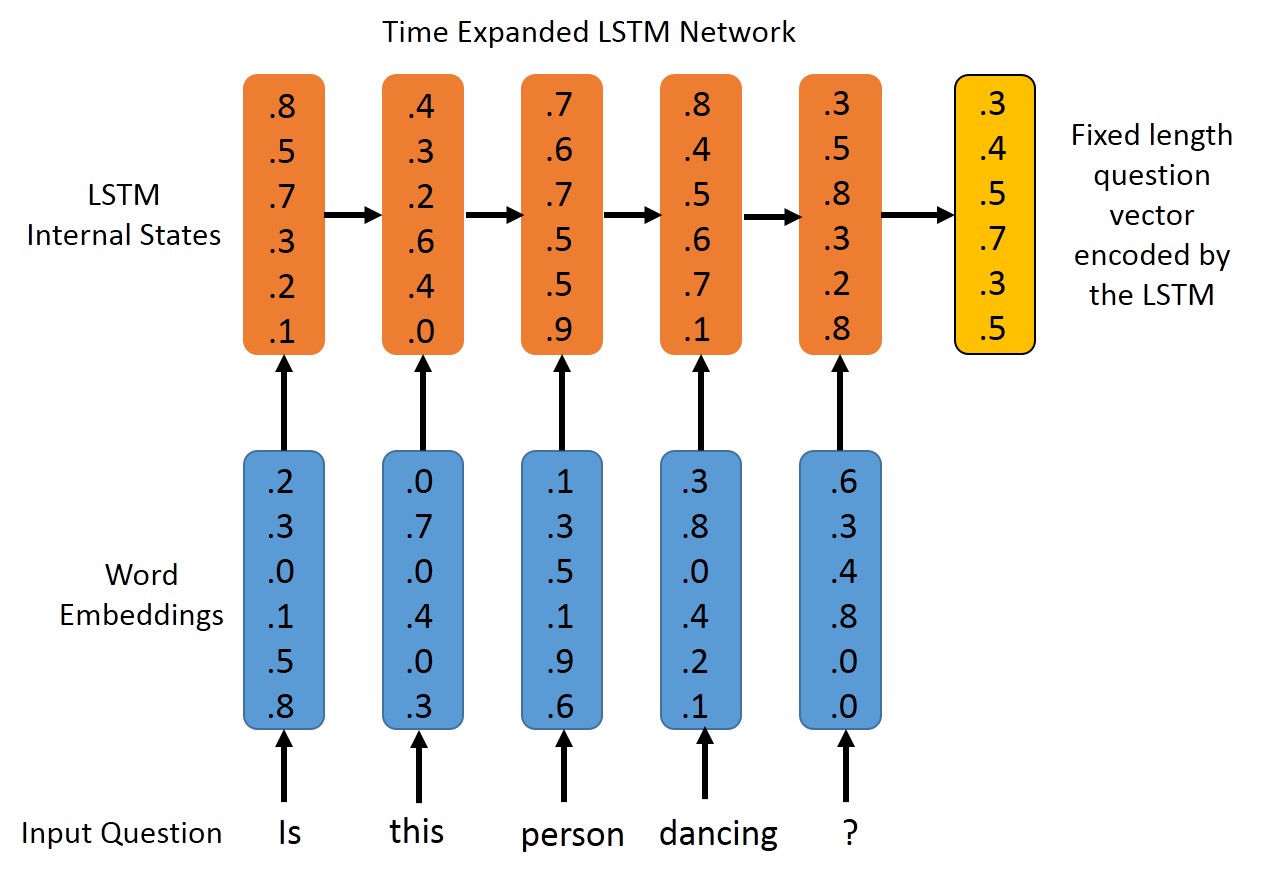
-
An LSTM-based model
##Requirements
- Keras 0.20
- spaCy 0.94
- scikit-learn 0.16
- progressbar
- Nvidia CUDA 7.5 (optional, for GPU acceleration)
Tested with Python 2.7 on Ubuntu 14.04 and Centos 7.1.
###Notes:
- Keras needs the latest Theano, which in turn needs Numpy/Scipy.
- spaCy is currently used only for converting questions to a vector (or a sequence of vectors), this dependency can be easily be removed if you want to.
- spaCy uses Goldberg and Levy's word vectors by default, but I found the performance to be much superior with Stanford's [Glove word vectors].
##The numbers Performance on the validation set of the VQA Challenge:
| Model | Accuracy |
|---|---|
| BOW+CNN | 44.30% |
| LSTM-Language only | 42.51% |
| LSTM+CNN | 47.80% |
There is a lot of scope for hyperparameter tuning here. Experiments were done for 100 epochs.
| Model | Training Time on GTX 760 |
|---|---|
| BOW+CNN | 160 seconds/epoch |
| LSTM+CNN | 200 seconds/epoch |
##Get Started
Have a look at the get_started.sh script in the scripts folder. Also, have a look at the readme present in each of the folders.
##Feedback All kind of feedback (code style, bugs, comments etc.) is welcome. Please open an issue on this repo instead of mailing me, since it helps me keep track of things better.
##License MIT