[TOC]
数据集及工具包获取
git clone https://github.com/iseesaw/SMP-MCC2020.git
我们提供部分多方主题闲聊数据供参赛队伍参考,除此以外,参赛队伍可以自行收集或使用开源的对话数据进行模型训练。
数据集原始数据主要从豆瓣小组(主题相关)等网络论坛获取。
我们对原始数据集进行了过滤清洗:
- 初步过滤,进行多人参与、时效性以及回复长度等方面过滤。
- 内容过滤,进行敏感词以及非法字符等方面过滤。
- 主题过滤,进行主题相关性过滤。
-
基本统计
主题 体育 数码产品 电影 美食 音乐 共计 会话数 530 979 1742 2050 1197 6498 -
详细统计
统计项 数量 总会话数(dialogues、sessions) 6498 总对话轮数(utterances) 88619 总说话人数 53581 总字数 1260000 每个会话最少对话轮数 3 每个会话平均对话轮数 13.6 每个会话最少说话人数 2 每个会话平均说话人数 8.2 每轮回复平均字数 14.2
数据集文件夹下包含五个主题文件夹,每个主题文件夹下包含对应主题的所有对话数据,每个文件为一个对话。
每个文件以 json 格式保存每个对话/帖子,具体如下:
{
"title": "", # 帖子标题
"topic": { # 楼主发帖信息
"name": "", # 楼主用户名
"date": "",
"content": "" # 楼主帖子内容
},
"pages": [],
"replys": [
{
"user": "", # 回复用户名
"date": "",
"content": "" # 回复内容
},
{
"user": "",
"date": "",
"content": ""
}
]
}注:
title和topic['content']不一定相同
我们提供工具包供参赛队伍参考,包括检索式和生成式两种系统模型。
对于发布的数据集,我们采用以下两种方式来构建检索式和生成式模型的输入和输出:
-
Sampling for short context(对启动句以及较短间隔的回复)
- 将楼主发帖
content作为context - 前
chunk(default 5)个非楼主回复作为候选回复response(或者楼主首次回复之前的其他人回复) - 构建
(context, response)
- 将楼主发帖
-
Chunking for long context(对正常对话的回复)
-
以楼主某次回复作为分块界限
-
将其之前对话中连续
chunk(default 5)个回复作为context -
将楼主此次回复作为
response -
构建
(context, response)
-
检索式系统使用 whoosh 库检索(其默认使用 bm25 算法)
- 主要步骤说明
-
建立索引
ir_system.pywhoosh中需要使用Schema建立索引,其中-
analyzer使用jieba分词(以及哈工大停用词表) -
pid为(context, response)的唯一ID(表示为{filename}-{method}-{index}) -
topic为对话主题 -
method为对话对构建方法(sampling或者chunking) -
context和response则为数据使用中构造的(context, response)
Schema( pid=ID(stored=True), topic=ID(stored=True), method=ID(stored=True), context=TEXT(stored=True, analyzer=analyzer), response=TEXT(stored=True, analyzer=analyzer))
-
-
进行检索
ir_server.py- 根据群聊对话记录构建
context用于检索 - 根据群聊对话记录长度,确定
method(长度为1则为sampling,否则为chunking) - 检索特定
topic和method的对话对的context字段 - 返回对话对的
response字段作为回复
- 根据群聊对话记录构建
-
环境配置(
python3.6)pip install -r requirements.txt
-
配置文件 (见
config.py)CONFIG = { # 索引文件保存位置 'IR_DIR': 'mcc_ir', # 数据集位置 'DATA_DIR': '../data/dataset', # 停用词保存位置 'STOP_WORDS': '../data/哈工大停用词表.txt', # Flask API 服务设置 'HOST': '0.0.0.0', 'PORT': 10240, # 生成模型API接口 'GEN_API': None }
请先将
dataste.zip解压到dataset,确保dataset下包含各主题文件夹将生成模型 API 接口填入
GEN_API,当whoosh检索没有返回结果时,调用该接口进行回复生成 -
初始化
创建索引文件
python ir_system.py init
-
运行服务
使用 flask 提供 API 接口服务,参考
ir_server.pypython ir_system.py server
或者(
pip install gunicorn,推荐)gunicorn -b 0.0.0.0:10240 -w 4 ir_server:app
-
访问服务
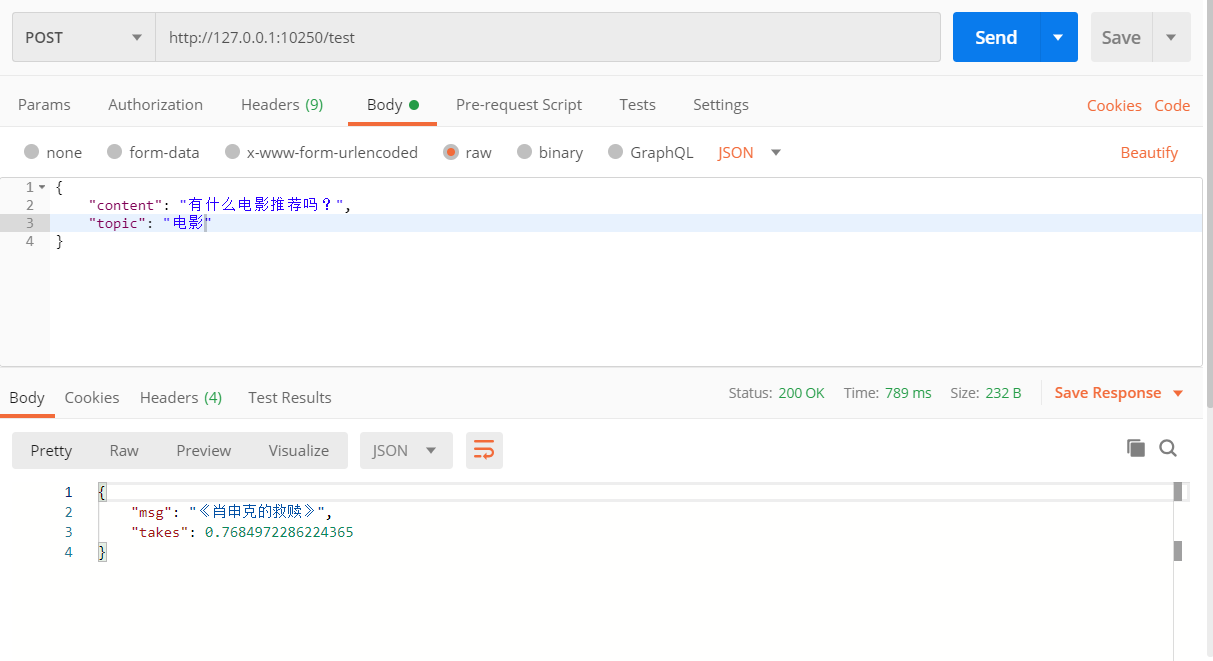
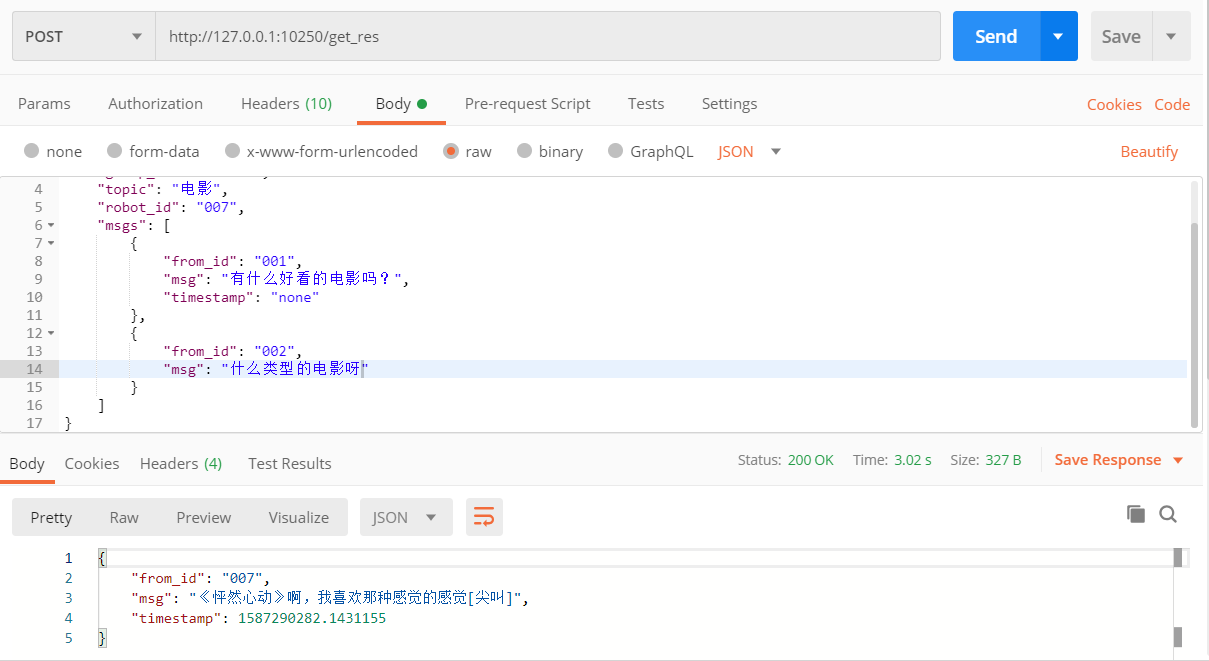
这里使用 postman 进行接口测试
检索测试 POST http://127.0.0.1:10240/test群聊测试 POST http://127.0.0.1:10240/get_res注:将检索服务部署服务器,开启对应端口后,将
http://ip:10240/get_res填入评测网站API提交处进行测试即可

生成式模型主要使用 GPT,代码参考 yangjianxin1/GPT2-chitchat
-
数据构造
将对话历史
context用[SEP]作为分隔符进行拼接,同时在最开始拼接对话topic,在最后面拼接response,即[CLS]topic[SEP]utter1[SEP]utter2[SEP]utter3...[SEP]response
-
依赖安装
pip install -r requirements.txt
-
数据预处理
python preprocess.py
注:请在
config.py中配置数据集位置DATA_DIR -
模型训练
python train.py --epochs 10 --batch_size 8 --device 0,1 --raw --pretrained_model dialogue_model/model_epoch10
注:可以使用 yangjianxin1/GPT2-chitchat 中提供的模型进行初始化(
--pretrained_model dialogue_model/model_epoch10) -
运行服务
-
配置文件说明(见
config.py)CONFIG = { # 数据集位置 'DATA_DIR': '../data/dataset/', # 词表 'voca_path': 'vocabulary/vocab_small.txt', # 训练得到的对话模型路径 'dialogue_model_path': 'dialogue_model/model_epoch10', # dialogue history 的最大长度 'max_history_len': 10, # 每个utterance的最大长度,超过指定长度则进行截断 'max_len': 25, # 重复惩罚参数,若生成的对话重复性较高,可适当提高该参数 'repetition_penalty': 1.0, # 生成的temperature 'temperature': 1, # 最高k选1 'topk': 8, # 最高积累概率 'topp': 0, # API 服务设置 'HOST': '0.0.0.0', 'PORT': 10250, }
-
运行命令(见
server.py)python server.py
-
-
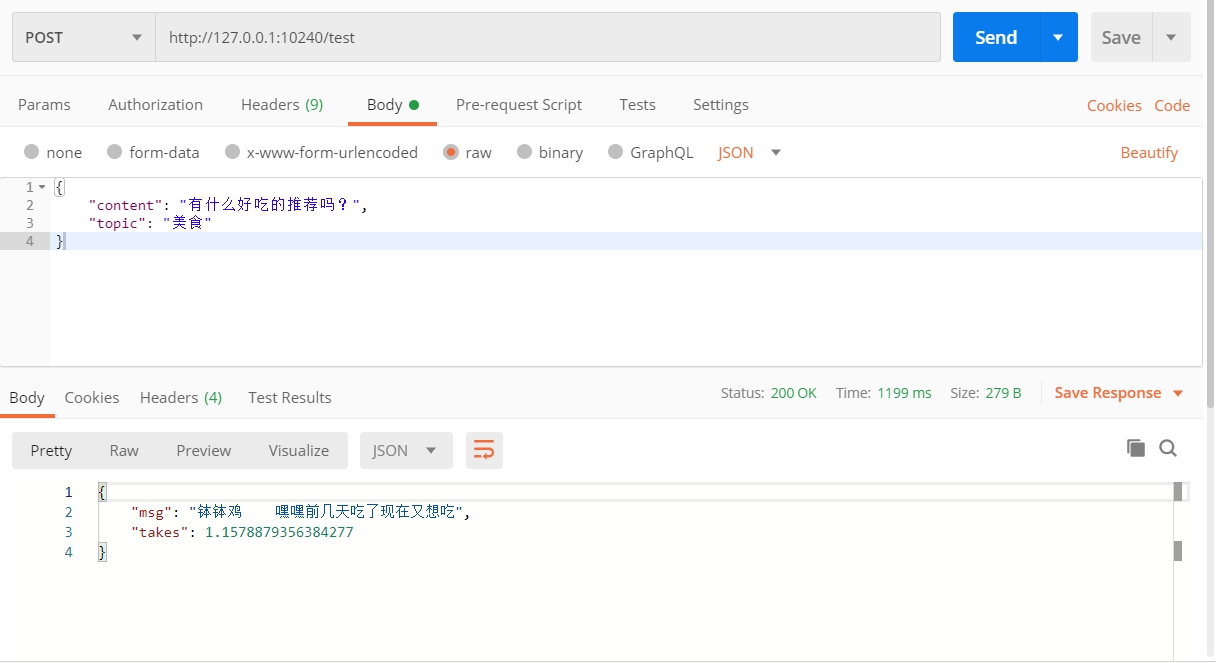
访问服务
检索测试 POST http://127.0.0.1:10250/test群聊测试 POST http://127.0.0.1:10250/get_res