
- 任务,给定10万张的query set,从包含10万个类70万张的index set中查找同一地标类型的图像;
- 数据,对包含1.5万个类120万张图像的Google Landmarks dataset v1(GLDv1)进行qurey和positive匹配对提取,最后包含31万个匹配对,119万张图;
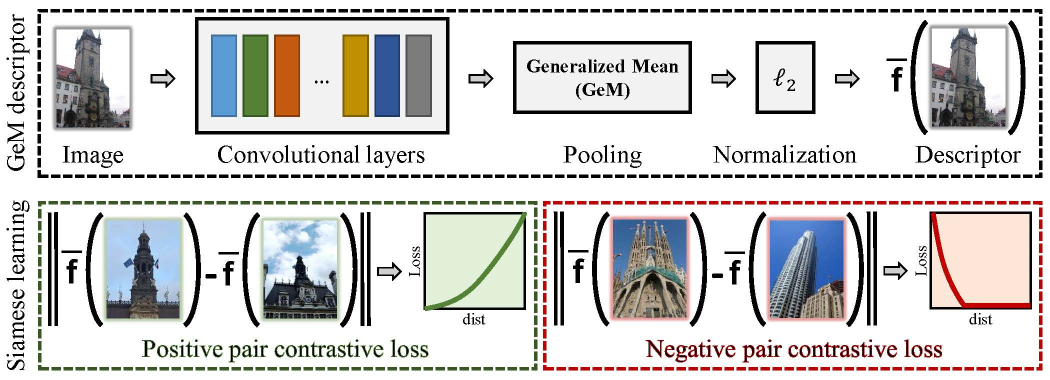
- 模型,以ResNet101为backbone,GeM通用平均池化做全局聚合,接FC进行PAC学习,最后以Siamese架构结合contrastive loss进行微调训练;
- 提升,对提取的特征再进行PCA whitening,带权重的query expansion,预计算PCA作为FC参数初始化,多层特征图池化串联;
- 成果,在地标检索及地标识别比赛中各获得银牌,地标检索排名19/144,Top14%,地标识别排名47/281,Top17%。
使用的框架如下:
- Python3 (tested with Python 3.7.0 on Ubuntu 18.04)
- PyTorch deep learning framework (tested with version 1.0.0)
Note: 项目中涉及的数据集路径需要修改为本地的路径!
Note: 同时也要修改 general.py 中 get_data_root() 的路径;
- 使用 landmarks_downloader.py 下载 GLDv1;
- 使用 generate_train_val_test_set.py 进行数据集切分,并将切分的数据信息存为pickle文件;
- 下载 Google Landmarks dataset v2(GLDv2);
- 使用 GL2_test_pkl.py 抽取 GLDv2 约490个类,1万多张图像做为 val-test set,为模型训练提供target,实验结果显示评估的结果和提交Kaggle评估的提升趋势相同, 这样省去每次都进行10万张test(query)和100万张index的特征提取及评估和提交Kaggle(Kaggle每天有提交次数上限);
Example training script is located in YOUR_CIRTORCH_ROOT/cirtorch/examples/train.py
python3 -m cirtorch.examples.train [-h] [--training-dataset DATASET] [--no-val]
[--test-datasets DATASETS] [--test-whiten DATASET]
[--test-freq N] [--arch ARCH] [--pool POOL]
[--local-whitening] [--regional] [--whitening]
[--not-pretrained] [--loss LOSS] [--loss-margin LM]
[--image-size N] [--neg-num N] [--query-size N]
[--pool-size N] [--gpu-id N] [--workers N] [--epochs N]
[--batch-size N] [--optimizer OPTIMIZER] [--lr LR]
[--momentum M] [--weight-decay W] [--print-freq N]
[--resume FILENAME]
EXPORT_DIR
For detailed explanation of the options run:
python3 -m cirtorch.examples.train -h
For example, to train the network
python3 -m cirtorch.examples.train YOUR_EXPORT_DIR --gpu-id 0 --training-dataset google-landmarks-dataset-resize --test-datasets google-landmarks-dataset-v2-test,roxford5k,rparis6k
--arch resnet101 --pool gem --loss contrastive --loss-margin 0.85 --optimizer adam --lr 5e-7 --weight-decay 0 --neg-num 5
--query-size=2000 --pool-size=22000 --batch-size 5 --epochs 200 --image-size 362
--multi-layer-cat 1
使用 predict.py 中的代码块及说明进行预测,并生成最终的submission.csv表格。 下表为训练过程中提升关键的阶段精度记录(mAP@100),
| Model | GLDv2-val-test | Public LB(stage1) | Public LB(stage2) | Private LB(stage2) |
|---|---|---|---|---|
| ResNet101-SfM120k (benchmark) | 0.25180 | 0.23368 | - | - |
| ResNet101-GLDv1-FC | 0.30954 | 0.33508 | - | - |
| ResNet101-GLDv1-FC-QE | - | 0.50667 | - | - |
| ResNet101-GLDv1-FC(prePCA)-QE | 0.32563 | - | 0.17507 | 0.20332 |
| ResNet101-GLDv1-ML2-FC(prePCA)-QE | 0.32991 | - | 0.18182 | 0.21052 |
- 使用 delf_extract_features.py 对 GLDv2 进行深度局部特征的提取;
- 使用 trainset_clear.py 对 GLDv2 训练集进行 RANSAC 及仿射变换计算内点数,并设定阈值筛选出 query 和 positive 匹配对, 最终清理结果对比如下(其中 GLD-v2-cleaned-m2 使用 train_m2_pkl.py 生成 pickle 文件):
| Dataset | Num | Landmarks | qp_pairs |
|---|---|---|---|
| GLD-v2 | 1599949/4132914 | 183308/203093 | 1416641 |
| GLD-v2-cleaned | 1769770 | 151535 | 5148819 |
| GLD-v2-cleaned-2 | 1031077 | 89356 | 3969519 |
| GLD-v1-resize | 328601/1225029 | 14655/14950 | 313946 |
| SfM-120k | 91642 | 551 | 181697 |
- 使用 train_cleaned.py 进行不同数据集的训练,并记录各 epochs 评估信息;
- 使用 train_cleaned_plot.py 对log信息进行绘图查看:

