

This repository contains code developed for a Part Of Speech (POS) tagger using the Viberbi algorithm to predict POS tags in sentences in the Brown corpus, which is a common Natural Language Processing (NLP) task. It contains the following features:
- HMM word emission frequency smoothing;
- Unknown word handling;
- Extra unknown words rules based on their morphological idiosyncrasies;
- HMM training data saving for quicker program execution.
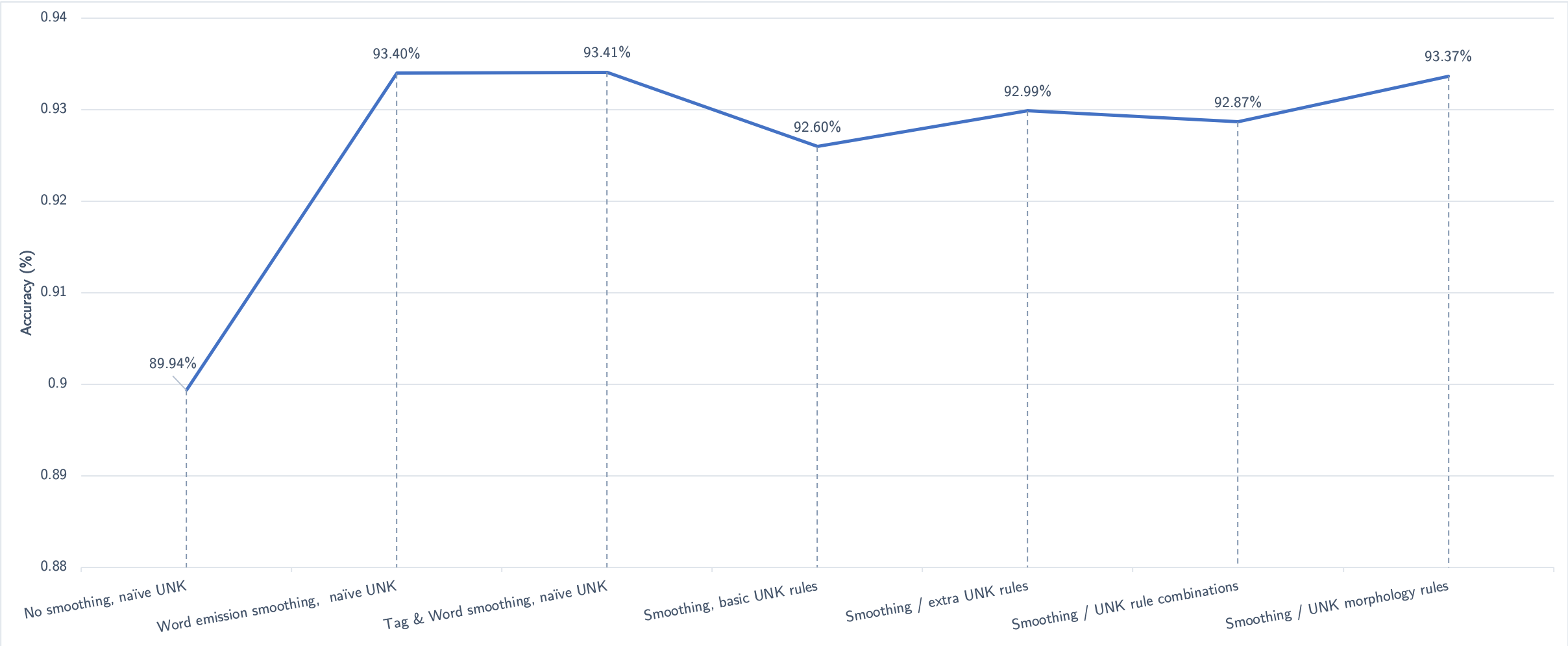
The evolution of the tagger's accuracy using different methods can be seen below. The report can be visited here.
Before running the program, create a new virtual environment to install Python libraries such as NLTK and run the following command:
pip install -r requirements.txt
To run the POS tagger in Python, move to the src directory and run the following command:
python main.py [-corpus <corpus_name>] [-r] [-d]
where:
-
-corpus: is the name of corpus to use, which can be eitherbrownorfloresta. This is an optional argument that defaults tobrownif nothing is specified. -
-r: is a flag that forces the program to recompute the HMM’s tag transition and word emission probabilities rather than loading previously computed versions into memory. -
-dis a flag that enters debugging mode, printing additional statements on the command line.
- see LICENSE file.
- Email: adam@jaamour.com
- Website: www.adam.jaamour.com
- LinkedIn: linkedin.com/in/adamjaamour
- Twitter: @Adamouization