Final Project for CSCI 6509: Natural Language Processing
Dalhousie University, Winter 2020
In this project, we aim to improve off-the-shelf products for text summarization and keyword extraction. These products use statistical techniques such as Bag-of-Words, which fail when it comes to semantical relationships between words. We tried to see if we can address this problem with word vectors.
The experimental results show that there is a trade-off between the performance improvement of state-of-the-art methods and the efficiency of the baselines.
👉 The following files originally belong to Gensim. For the proposed methods (both generic and query-based summarization), I modified the original source codes to change the weighing method of the edges, add sentence-query semantic comparison, and redundancy removal.
- improved_keywords.py
- improved_summarizer.py
- preprocessing_without_stemming.py
- textcleaner_without_stemming.py
👉 Gensim has a list of default preprocessing steps including stop word and punctuation removal embedded in the algorithm for summarization, therefore there is not much need for an external preprocessing before using the algorithm.
👉 I used GloVe pre-trained word vectors trained on Wikipedia 2014 and GigaWord to get the vector representation of each token.
Problem definition: Given an article w, we want to find a concise representation, called s, conveying the main idea of the article while having a user-defined number of sentences. The user-defined length of the summary is strictly lower than the original text, that is, length(w) > length(s).
Benchmark: Gensim's Summarizer based on TextRank
Proposed improvement: Using word embeddings with TextRank based on paper "Al-Sabahi, K., & Zuping, Z. (2019). Document Summarization Using Sentence-Level Semantic Based on Word Embeddings. International Journal of Software Engineering and Knowledge Engineering, 29(02), 177-196. doi:10.1142/s0218194019500086"
Evaluation:
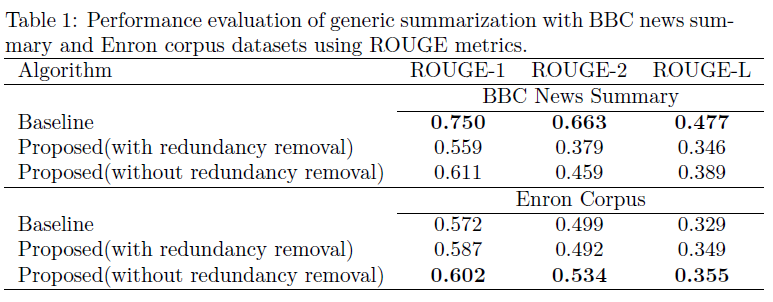
- Data: BBC news summary dataset and Enron corpus (Bryan Klimt and Yiming Yang. The enron corpus: A new dataset for email classiffcation research. In European Conference on Machine Learning, pages 217{226. Springer, 2004.)
- Metric: ROUGE (Recall-Oriented Understudy for Gisting Evaluation). I used the ROUGE scorer implemented by Google Research for Python
- Results:
- For the Enron dataset, which has shorted text content on average, com- pared to BBC news summary, the proposed method have marginally out-performed the baseline generic summarization.
- Simple TextRank performs much better than semantically-modified TextRank for BBC news summaries. This result is in contrast to the consensus that word vectors and semantic analysis of text are superior to traditional statistical methods. This finding is not surprising, for example, a research experimented word similarity and analogy detection tasks with different algorithms to see if word embeddings always outperform the traditional methods; which was not the case.
- Redundancy removal has mostly declined the performance. Perhaps the
human annotators didn't emphasize having very diverse sentences in the
summary, but in case of automatic redundancy removal, the goal is to
have as many diverse sentences as possible. Therefore, the fnal summary
doesn't overlap much with the human-generated one.
Problem definition: Given an article w and a query q, we want to find a concise representation, called sq, summarizing the sections of the article related to query q.The length of the summary is strictly lower than the original text, that is, length(w) > length(sq).
Benchmark: By the time of doing this project (winter 2020), there is no off-the-shelf software that does query-based summarization for a single document; a handful of software only perform multiple-document summarization. Therefore, I made a simple query-based summarizer (with Gensim) as the baseline, that takes the generic summary and only keeps the sentences with at least one term from the query.
Proposed improvement: Using word embeddings with TextRank. The algorithm is almost the same as the generic summarization. After TextRank generates the summary, we only keep the sentences that their cosine similarity with the query's word vector is over a predefined threshold. The query-sentence comparison in this methodology is inspired by "Yousefi-Azar, M., Sirts, K., Hamey, L. & Aliod, D. M. (2015). Query-Based Single Document Summarization Using an Ensemble Noisy Auto-Encoder.. In B. Hachey & K. Webster (eds.), ALTA (p./pp. 2-10), : ACL."
Evaluation:
- Data: Enron corpus (the annotated keywords were used as query)
- Metric: ROUGE
- Result: Semantic query-based summarization slightly performs better than the
baseline method.

Problem definition: Given an article w, we want to find a set of keywords {k1, k2, .., kn} that best represents the theme of the article.
Benchmark: Gensim's Keywords based on TextRank
Proposed improvement: Using word embeddings with TextRank based on paper "Zuo, X., Zhang, S., & Xia, J. (2017). The enhancement of TextRank algorithm by using word2vec and its application on topic extraction. Journal of Physics: Conference Series, 887, 012028. doi:10.1088/1742-6596/887/1/012028"
Evaluation:
- Data: Enron corpus
- Metric: ROUGE
- Result: The out-performance is negligible and using semantic weights from
a pre-trained model does not give any advantages over using a less complex
traditional method.

The improvements of incorporating word embeddings into TextRank were marginal and slow to execute. Considering the timeliness-performance trade-off, the off-the-shelf product wins as it is fast with an acceptable performance.