A task-Based multithread crawler framework for simple-minds.
=====
Version 1.0 beta.
#Features of version 1.0
- freaking task-based, 基于任务
- less network-panic 不需要拘泥于网络的细节,包括错误处理和重试
- more handlers 需要关心handlers,也就是你处理爬到的内容的逻辑实现
- simple http-controling(not implemented yet)-monitoring 基于http的监控和(控制)接口
- mess logs 不止一坨日志
- abysmal bugs maybe 可能潜在的一堆bugs
#Installation
- python 2.7
- And,
while running not OK:
check what you are lacking of
add them..- Copy the dir to the place you want.
- Done.
#Try Demo
demo是挖voa的内容,但是voa的内容是被GFW认证的,所以你假如要试用的话,请先确认你的服务器能够连接到 http://learningenglish.voanews.com/
[cheungzee@pn-206-246 iPapa_voa]$cd bin
[cheungzee@pn-206-246 bin]$ls
AudioHandler.py ClassPageHandler.pyc ContentPageHandler.pyc PicHandler.py setup.py
AudioHandler.pyc ContentMp3PageHandler.py MainPageHandler.py PicHandler.pyc setup.pyc
ClassPageHandler.py ContentPageHandler.py MainPageHandler.pyc run.py
[cheungzee@pn-206-246 bin]$python run.py
wget localhost:28282
or type in localhost:28282 in your favourite broswer.
#Play it to the beat(not finished yet)
There are status of the task noted by task.status,
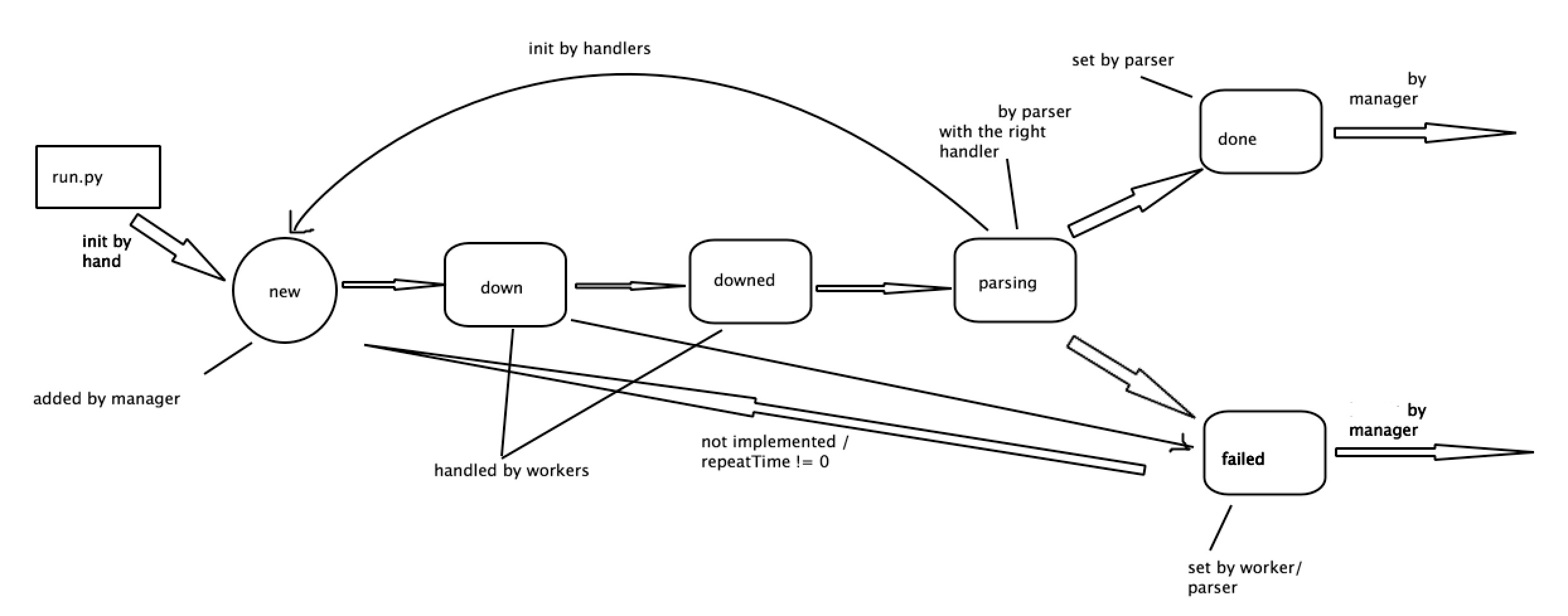
- new
- down
- downed
- parsing
- done
- failed
- "page", we will get it once in worker, and put it in task['__data']. 对于page类型的task,worker实例会调用Fetcher 实例来一次性下载task.url指向的内容,并将内容保存到task['__data']中
- "media", we may download it to the task.dest palce with serveral times, 5MB a chunk for each time. 对于media类型的task我们会进行分块下载,每次5MB,下载到task.dest指定的路径中
- only task['_data'] is used by the framework. 我们仅仅使用_data 作为task的保留关键字。
- Check our demo run.py
- Read the code
def __init__(self, taskId, #taskId
status='new', #status
url='', #url
handler='common', #call which handler to handle it in parsing stage
handleBy='', #like a stamp saying, I am handling by which one...
repeatTime=0, #not implemented yet, when this task failed, shall we put it into the WorkManager.inQueue for a new birth.
tryTimes=3, # retry times if got erroes in fetching the url
waitTime=30, # set timeout as waitTime in fetching the url
taskType='page', # page or media?
msg='new', #sth. like testament of the task...
postdata={}, #if the request is a post request.
data={}, #data in 'data' will be in task like values in a dict
ref='', #ref url
dest='') #put file in the dest, if the taskType is mediatake cares of the threads, counters, queues, and blablabla, plz see the code and demo for details.
- WorkManager.inQueue type: Queue.Queue(), we put new tasks in it.
- WorkManager.outPQueue type: Queue.Queue(), Parser put the processed tasks in it.
- WorkManager.wThreads type: list, list of worker threads.
- WorkManager.pThreads type: list, list of parser threads.
- WorkManager.cThread controller thread, providing http interface for monitoring.
- WorkManager.activeTasks type list, storing the active tasks for referencing.
- WorkManager.start(self) start the crawler frame
- WorkManager.packTask(self, task) pack a task by setting the task.id
- WorkManager.addTask(self, task) add a task in self.inQueue and self.activeTasks
- WorkManager.rmTask(self, task) rm a task from self.activeTasks.
- Get a new task from the inQueue of WorkManager.
- Set the task.status as "down".
- Begin to fetch/download the data pointed by task.url into task.dest or task['__data'].
- Set the task.status to be "downed" or "failed".
- Put the task into WorkManager.outQueue, i.e., WorkManager.inPQueue.
- Get a new task from the WorkManager.inPQueue.
- Parse it from task['__data'] for "page" task / do checking moving jobs for the "media" type task.
- Set the task.status into "done" or "failed".
- Put it into the WorkManager.outPQueue.