Asynchronous deep reinforcement learning + Pseudo-count based reward + On-highscore-learning
This code is fork from miyosuda's code. I added many functions for my Deep Learning experiments. Of which, pseudo-count based reward based on following DeepMind's paper and on-highscore-learning (my original) enable over 1500 point average score in Montezuma's Revenge, which is higher than the paper as for A3C.
"on-highscore-learning" is my original idea, which learn from state-action-rewards-history when getting highscore. But in evaluation of Montezuma's Revenge, I set option to reset highscore in every episode, so learning occured in every score. (I'm changing this now. In new version, only highscore episode will be selected automatically based on history of scores)
See following slide (in English) for explanation of this project.
http://www.slideshare.net/ItsukaraIitsuka/drl-challenge-on-montezumas-revenge
See following slide (in Japanese) for Japanese explanation.
The following graph is the average score of Montezuma's Revenge.
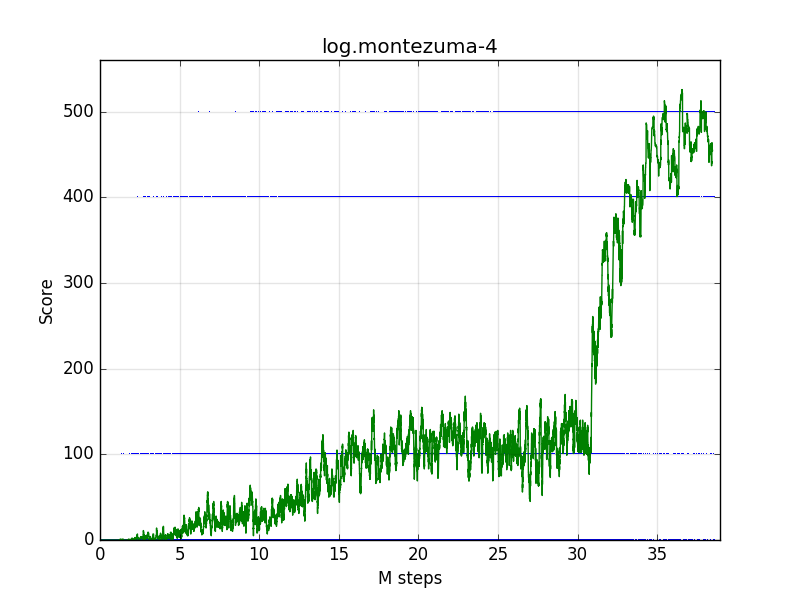
0 - 30M steps: Pseudo-count based reward is ON.
30 - 40M steps: Above + on-highscore-learning is ON.
The following graph is the best Learning Curve of Montezuma's Revenge (2016/10/7). Best score is 2500 and peak average score is more than 1500 point.

- My result The following picture indicates the rooms explored in my all trainings.
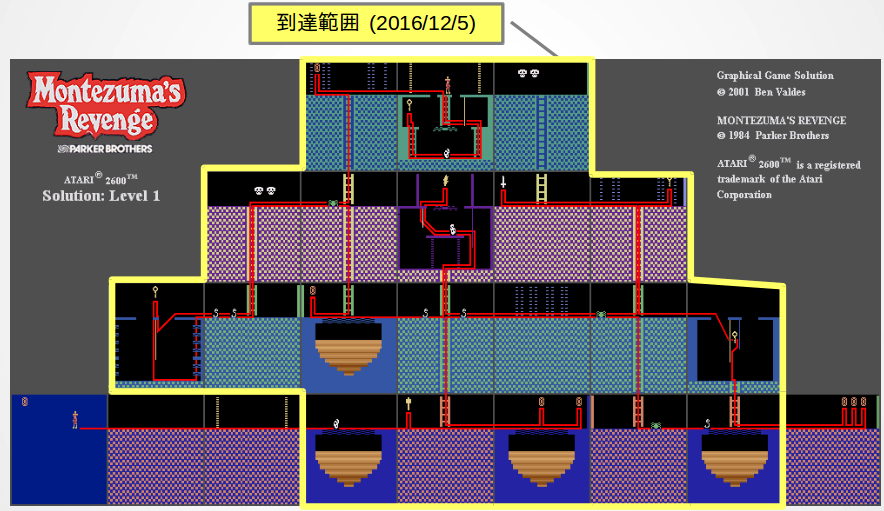
This is better than DeepMind result (see next picture). This was achieved in OpenAI Gym environment only. In ALE environment, although the average score is higher than OpenAI Gym, the number of explored rooms is less than that of OpenAI Gym.
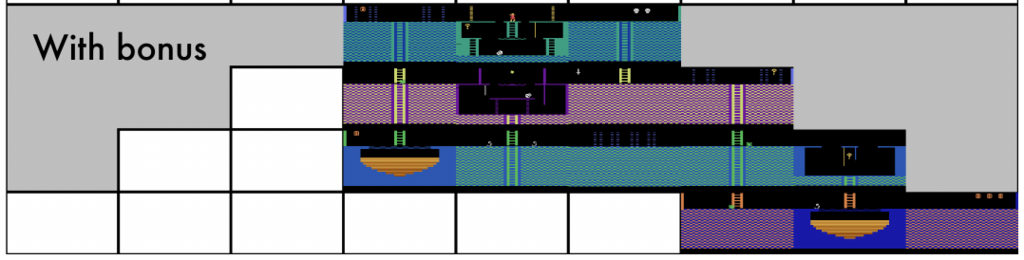
- DeepMind's result The rooms expolred in DeepMind paper (all in all).
The following is a play movie of Montezuma's Revenge after training 50M steps. Its score is 2600.

This code needs Anaconda, tensorflow, opencv3 and Arcade Learning Environment (ALE). After download of gcp-install-a3c-env.tgz, you can use scrips in "gcp-install" directory. Run following.
$ sudo apt-get install git
$ git clone https://github.com/Itsukara/async_deep_reinforce.git
$ mkdir Download
$ cp async_deep_reinforce/gcp-install/gcp-install-a3c-env.tgz Download/
$ cd Download/
$ tar zxvf gcp-install-a3c-env.tgz
$ bash -x install-Anaconda.sh
$ . ~/.bashrc
$ bash -x install-tensorflow.sh
$ bash -x install-opencv3.sh
$ bash -x install-ALE.sh
$ bash -x install-additionals.sh
$ cd ../async_deep_reinforce
$ ./run-option montezuma-c-avg-greedy-rar025
When program requests input, just hit Enter or input "y" or "yes" and hit Enter. But as for Anaconda, you have to input "q" when License and "--More--" is displayed.
I built the environment using my scripts on Ubuntu 14.04LTS 64bit in Google Cloud Platform, Amazon EC2 and Microsoft Azure.
To train,
$ ./run-option montezuma-c-max-greedy-rar025
To display game screen played by the program,
$ python a3c_display.py --rom=montezuma_revenge.bin --display=True
To create play movie without displaying the game screen,
$ python a3c_display.py --rom=montezuma_revenge.bin --record-screen-dir=screen
$ run-avconv-all screen # you need avconv
As for options, see options.py.
I uploaded evaluation result in OpenAI Gym. See "OpenAI Gym evaluation page". I'd appreciate if you cloud review my evaluation.
To repuroduce OpenAP Gym result,
$ ./run-option-gym montezuma-j-tes30-b0020-ff-fs2
Play screens are recorded in following directory,
- screen.new-room : screens when entered new room are recored
- screen.new-record : screens when achieved new score are recorded
The source code is still under development and may chage frequently. Currently, I'm searching best parameters to speed-up learning and get higher score. In this search, I'm adding new functions to change behavior of the program. So, it might be degraded sometimes. Sorry for that in advance.
I'd appreciate if you could write your experiment result to thread "Experiment Results" in Issues.
I'm writing blog on this program. See following (in Japanese):
http://itsukara.hateblo.jp/ (Itsukara's Blog)
I'd appreciate if you woud refer my code in your blog or paper as following:
https://github.com/Itsukara/async_deep_reinforce (On-Highscore-Learning code based on A3C+ and Pseudo-count developed by Itsukara)
- @miosuda for providing very fast A3C program.