{kind=link}
.png){kind=link}
cluster16.png){kind=link}
cluster16iter10.png){kind=link}
The purpose is to computationally simulate the paper below, which showed that place fields in rat hippocampus accumulate near the goal location in a maze task.
Hollup, S. A., Molden, S., Donnett, J. G., Moser, M. B., & Moser, E. I. (2001). Accumulation of hippocampal place fields at the goal location in an annular watermaze task. The Journal of Neuroscience, 21(5), 1635-1644.
0 1 2 3 4 5 6 7 8
8888888888888888888888888888888888888
8 8 G 8 8
8 88888888888888888888888888888 8
7 8 8 8 8 7
8 8 8 8 8 8 8 8 8 8
6 8 8 8 8 6
8 8 8 8 8 8 8 8 8 8
5 8 8 8 8 5
8 8 8 8 8 8 8 8 8 8
4 8 8 8 8 4
8 8 8 8 8 8 8 8 8 8
3 8 8 8 8 3
8 8 8 8 8 8 8 8 8 8
2 8 8 8 8 2
8 8 8 8 8 8 8 8 8 8
1 8 8 8 8 1
8 88888888888888888888888888888 8
0 8 8 0
8888888888888888888888888888888888888
0 1 2 3 4 5 6 7 8
The starting point is always (0, 0) and the goal is indicated as G. Once the agent reaches the available goal, the environment is reset and the agent is put back to the starting point.
The agent chooses the direction in a Q-learning-based epsilon greedy manner.
Two training procedure are independently implemented in thie repository. The main training loop is LSTM, which learns to predict the visual image following the movement.
-
A-1
LSTM is trained using dataset generated by an agent in a maze, who chooses actions in a Q learning-based epsilon greedy manner. Validation and testing for LSTM are performed in every
valid_lenepochs with dataset generated randomly and independently. -
A-2 (
get_goalfunction in environment.py needs modified)A-1 does not work well. Perhaps the resaon is that since a well-trained agent would rarely visit all regions of the arena, the training dataset for LSTM are extremely biased. Therefore, in order to solve this sampling problem, a trick that was also used in the paper is implemented: the goal is at first unavailable, but turns available once the agent has passed the entire arena. The agent gets some reward on the goal if the goal is available, while it gets no reward if the goal is unavailable.
This training procedure is implemented in order to circumvent some problems on the previous training procedure.
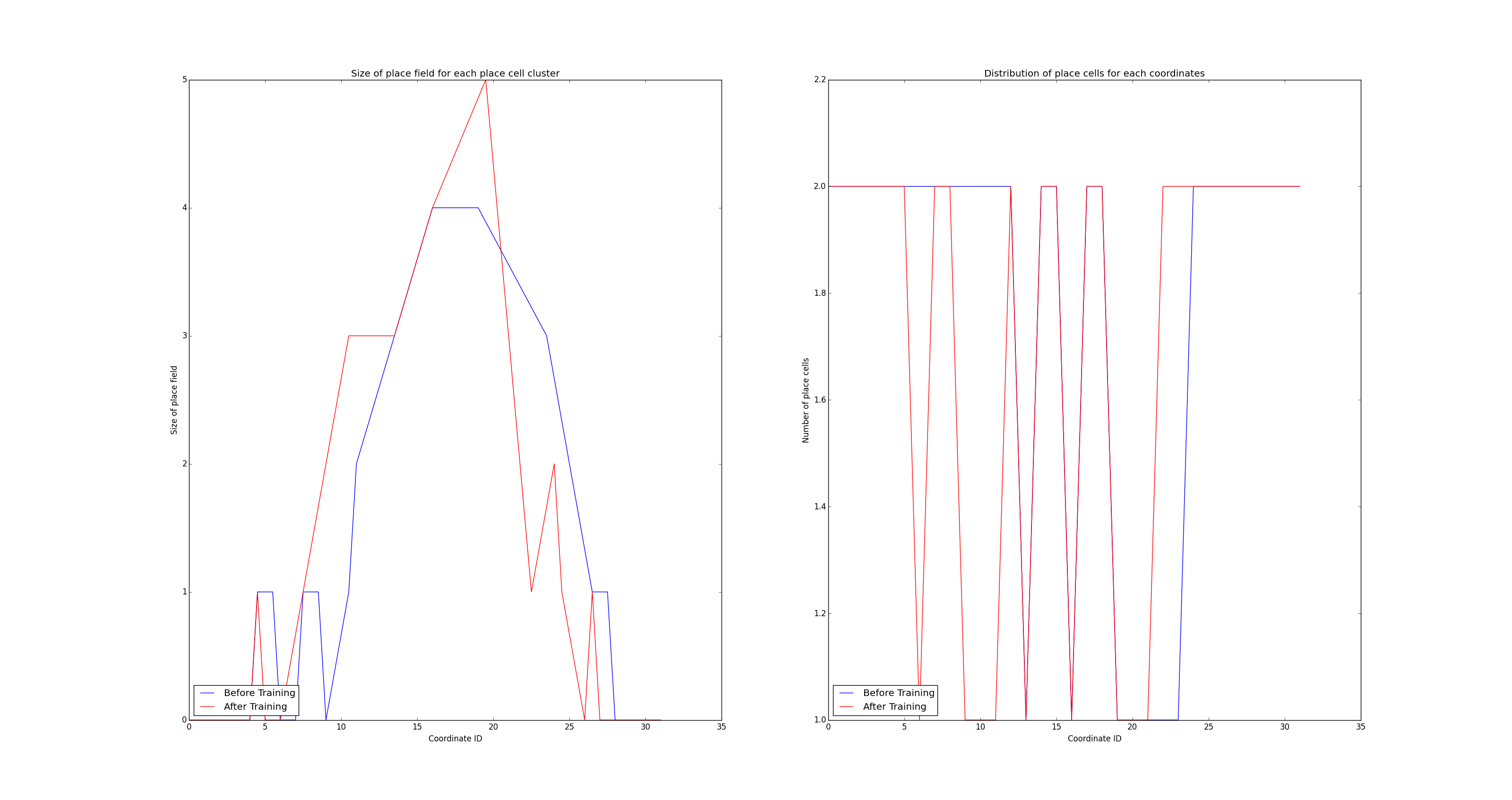
- Accumulation of place fields near the goal locations is observed in adult rodents, while LSTM training in the previous learning procedure, where weights are randomly initialized, mimics rodents in developmental stages, .
- Accumulation of place fields near the goal locations is observed in place cells in CA1 region, not in CA3.
- The previous training procedure does not work well.
Detailed training procedure is as follows:
-
Pre-training of LSTM: this mimics rodents in developmental stages.
- LSTM is trained using randomly generated training dataset.
- In every
valid_len1epochs, weights on LSTM are clumped and:- LSTM validation is preformed.
- Using randomly generated dataset, SVM training with grid search and SVM testing are performed. The targets of SVM are assumed place cells in CA3 region where robust place cells are observed.
- When LSTM and SVM are trained enough, learning loop is broken.
-
Clustering
- EM clustering is perfomed with randomly generated dataset. The targets of EM clustering are assumed place cells in CA1 region where plastic place cells are observed. This clustering shows distribution of place fields before undergoing the maze task.
-
Fine-tuning of LSTM: this mimics adult rodents undergoing annular water maze task.
- LSTM is trained using dataset generated by an agent in a maze environment.
- The agent chooses actions in a Q learning-based epsilon greedy manner.
- In every
valid_len2epochs, weights on LSTM are clumped and:- LSTM validation is performed.
- SVM testing is perfomed to make sure that fine-tuning of LSTM does not influence the classification by SVM.
- When Q learning saturates, learning loop is broken
-
Clustering
- EM clustering is perfomed with randomly generated dataset. This clustering shows distribution of place fields after the task.
-
A-1
Q learning works well after approximately 20 epochs. However, LSTM training does not work well perhaps due to extremely biased training dataset.
-
A-2
LSTM training works well since in this case the agent covers the entire arena. However, Q learning does not work well.
![results] (https://raw.githubusercontent.com/NB-DQN/q_place_cell/master/151012_1_clustering_analysis.png)
{kind=link}
bash-3.2$ python train_LSTM_with_pretrain.py
/Users/ukitajumpei/anaconda/lib/python2.7/site-packages/chainer/function_set.py:47: FutureWarning: 'collect_parameters' is deprecated. You can pass FunctionSet itself to 'optimizer.setup'
warnings.warn(msg, FutureWarning)
[LSTM pre-train]
epoch 50: train perp: 649.12 valid square-sum error: 16.84 (5.12 epochs/sec)
SVM test accuracy: 1.0
epoch 100: train perp: 61.20 valid square-sum error: 0.02 (2.02 epochs/sec)
SVM test accuracy: 1.0
epoch 150: train perp: 7.70 valid square-sum error: 0.00 (2.13 epochs/sec)
SVM test accuracy: 1.0
epoch 200: train perp: 4.10 valid square-sum error: 0.00 (2.12 epochs/sec)
SVM test accuracy: 1.0
epoch 250: train perp: 2.50 valid square-sum error: 0.00 (2.14 epochs/sec)
SVM test accuracy: 1.0
epoch 300: train perp: 2.11 valid square-sum error: 0.00 (2.14 epochs/sec)
SVM test accuracy: 1.0
epoch 350: train perp: 1.55 valid square-sum error: 0.00 (2.13 epochs/sec)
SVM test accuracy: 1.0
epoch 400: train perp: 1.48 valid square-sum error: 0.00 (2.16 epochs/sec)
SVM test accuracy: 1.0
epoch 450: train perp: 1.30 valid square-sum error: 0.00 (2.15 epochs/sec)
SVM test accuracy: 1.0
epoch 500: train perp: 1.26 valid square-sum error: 0.00 (2.14 epochs/sec)
SVM test accuracy: 1.0
epoch 550: train perp: 0.80 valid square-sum error: 0.00 (2.16 epochs/sec)
SVM test accuracy: 1.0
epoch 600: train perp: 0.93 valid square-sum error: 0.00 (2.16 epochs/sec)
SVM test accuracy: 1.0
epoch 650: train perp: 0.73 valid square-sum error: 0.00 (2.15 epochs/sec)
SVM test accuracy: 1.0
epoch 700: train perp: 0.67 valid square-sum error: 0.00 (2.14 epochs/sec)
SVM test accuracy: 1.0
epoch 750: train perp: 0.74 valid square-sum error: 0.00 (2.11 epochs/sec)
SVM test accuracy: 1.0
epoch 800: train perp: 0.60 valid square-sum error: 0.00 (2.13 epochs/sec)
SVM test accuracy: 1.0
epoch 850: train perp: 0.62 valid square-sum error: 0.00 (2.14 epochs/sec)
SVM test accuracy: 1.0
epoch 900: train perp: 0.47 valid square-sum error: 0.00 (2.18 epochs/sec)
SVM test accuracy: 1.0
[Clustering]
Clustering results: (y_true, y_pred)
[(0, 0), (0, 6), (1, 7), (1, 23), (2, 16), (2, 19), (3, 1), (3, 28), (4, 21), (4, 30), (5, 21), (5, 22), (6, 8), (6, 22), (7, 18), (7, 24), (8, 18), (8, 31), (9, 26), (9, 31), (10, 3), (10, 13), (11, 3), (11, 13), (12, 13), (12, 27), (13, 27), (14, 10), (14, 27), (15, 10), (15, 27), (16, 10), (17, 10), (17, 20), (18, 10), (18, 20), (19, 20), (20, 20), (21, 20), (22, 4), (23, 4), (24, 4), (24, 15), (25, 4), (25, 15), (26, 9), (26, 15), (27, 9), (27, 25), (28, 2), (28, 25), (29, 11), (29, 17), (30, 5), (30, 29), (31, 12), (31, 14)]
[LSTM fine-tuning]
0 1 2 3 4 5 6 7 8
8888888888888888888888888888888888888
8 8 G 8 8
8 88888888888888888888888888888 8
7 8 8 8 8 7
8 8 8 8 8 8 8 8 8 8
6 8 8 8 8 6
8 8 8 8 8 8 8 8 8 8
5 8 8 8 8 5
8 8 8 8 8 8 8 8 8 8
4 8 8 8 8 4
8 8 8 8 8 8 8 8 8 8
3 8 8 8 8 3
8 8 8 8 8 8 8 8 8 8
2 8 8 8 8 2
8 8 8 8 8 8 8 8 8 8
1 8 8 8 8 1
8 88888888888888888888888888888 8
0 8 8 0
8888888888888888888888888888888888888
0 1 2 3 4 5 6 7 8
Q steps: 856
Q steps: 148
Q steps: 50
Q steps: 88
Q steps: 220
Q steps: 268
Q steps: 32
Q steps: 138
Q steps: 52
Q steps: 30
epoch 10: train perp: 3.11 valid square-sum error: 0.00 (0.37 epochs/sec)
SVM test accuracy: 1.0
Q steps: 238
Q steps: 80
Q steps: 100
Q steps: 252
Q steps: 44
Q steps: 34
Q steps: 32
Q steps: 16
Q steps: 42
Q steps: 44
epoch 20: train perp: 0.29 valid square-sum error: 0.00 (2.66 epochs/sec)
SVM test accuracy: 1.0
Q steps: 78
Q steps: 78
Q steps: 16
Q steps: 18
Q steps: 18
Q steps: 16
Q steps: 16
Q steps: 16
Q steps: 16
Q steps: 16
epoch 30: train perp: 0.16 valid square-sum error: 0.00 (3.95 epochs/sec)
SVM test accuracy: 1.0
Q steps: 22
Q steps: 18
Q steps: 18
Q steps: 16
Q steps: 20
Q steps: 16
Q steps: 20
Q steps: 16
Q steps: 18
Q steps: 24
epoch 40: train perp: 0.13 valid square-sum error: 0.00 (4.30 epochs/sec)
SVM test accuracy: 1.0
[Clustering]
Clustering results: (y_true, y_pred)
[(0, 1), (0, 14), (1, 2), (1, 15), (2, 20), (2, 31), (3, 7), (3, 13), (4, 24), (4, 26), (5, 22), (5, 26), (6, 30), (7, 3), (7, 28), (8, 3), (8, 28), (9, 5), (10, 5), (11, 5), (12, 5), (12, 25), (13, 25), (14, 18), (14, 25), (15, 18), (15, 25), (16, 18), (17, 8), (17, 18), (18, 8), (18, 18), (19, 8), (20, 8), (21, 8), (22, 4), (22, 8), (23, 4), (23, 29), (24, 10), (24, 29), (25, 10), (25, 29), (26, 23), (26, 27), (27, 17), (27, 23), (28, 6), (28, 19), (29, 0), (29, 12), (30, 16), (30, 21), (31, 9), (31, 11)]
[LSTM test]
test square-sum error: 0.00