This is the repo for paper Semantic Frame Forecasting (NAACL 2021).
https://arxiv.org/pdf/2104.05604.pdf
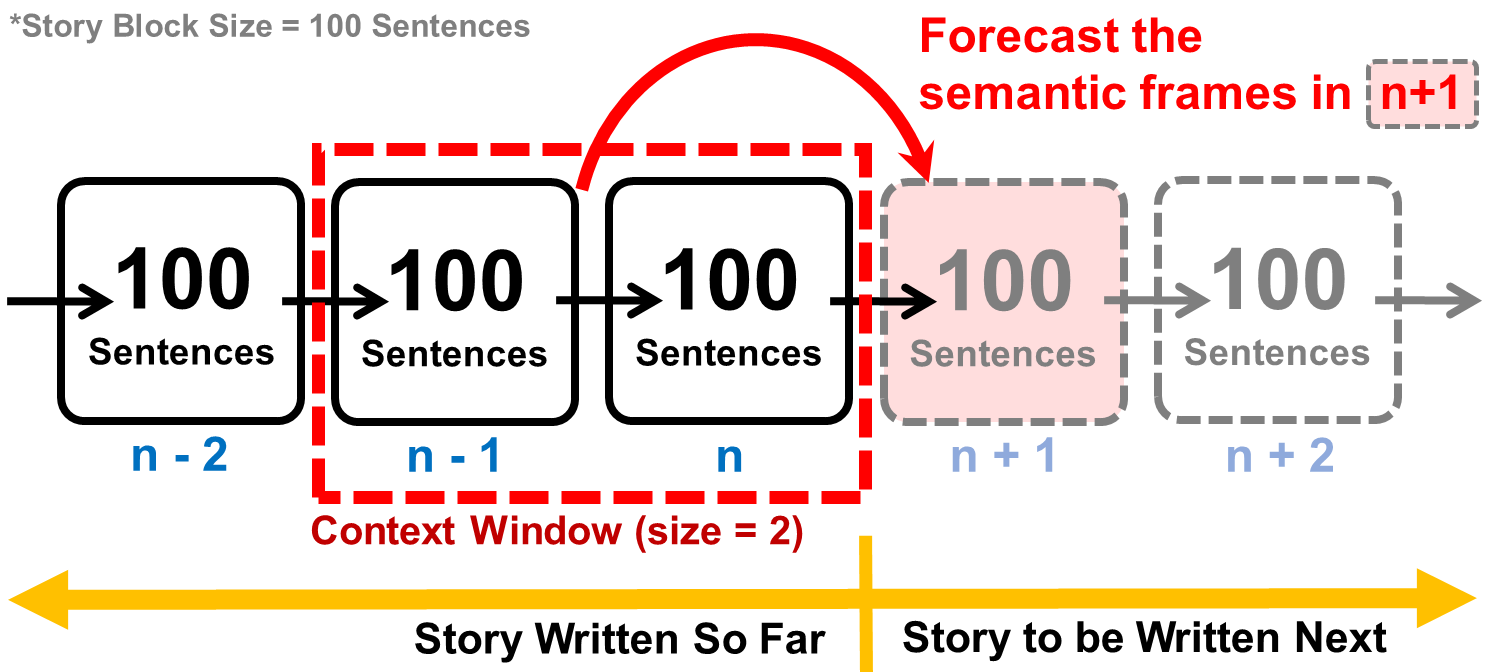
In this paper, we formulate a book as a sequence of story blocks where each story block contains a fixed number of sentences. We then present a Semantic Frame Representation to represent each story block as a TF-IDF vector over semantic frames. Semantic Frames are high-level concept of "things". Therefore, predicting a semantic frame in the follow-up story block basically means predicting what would happen next. The Semantic Frame Forecast task aims at predicting the semantic frame representation of the follow-up story block (n+1) using what we have so far (story block n, n-1, ..., and so on).
If you find our paper or code useful and you would like to use it in your work. Please consider cite the following paper.
@inproceedings{huang-huang-2021-semantic,
title = "Semantic Frame Forecast",
author = "Huang, Chieh-Yang and
Huang, Ting-Hao",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.naacl-main.215",
pages = "2702--2713",
abstract = "This paper introduces Semantic Frame Forecast, a task that predicts the semantic frames that will occur in the next 10, 100, or even 1,000 sentences in a running story. Prior work focused on predicting the immediate future of a story, such as one to a few sentences ahead. However, when novelists write long stories, generating a few sentences is not enough to help them gain high-level insight to develop the follow-up story. In this paper, we formulate a long story as a sequence of {``}story blocks,{''} where each block contains a fixed number of sentences (e.g., 10, 100, or 200). This formulation allows us to predict the follow-up story arc beyond the scope of a few sentences. We represent a story block using the term frequencies (TF) of semantic frames in it, normalized by each frame{'}s inverse document frequency (IDF). We conduct semantic frame forecast experiments on 4,794 books from the Bookcorpus and 7,962 scientific abstracts from CODA-19, with block sizes ranging from 5 to 1,000 sentences. The results show that automated models can forecast the follow-up story blocks better than the random, prior, and replay baselines, indicating the feasibility of the task. We also learn that the models using the frame representation as features outperform all the existing approaches when the block size is over 150 sentences. The human evaluation also shows that the proposed frame representation, when visualized as word clouds, is comprehensible, representative, and specific to humans.",
}
Two of the datasets are used in our paper, Bookcorpus and CODA-19. We will describe how to obtain the dataset and preprocess the code here.
We provide the book list and their meta information in data/bookcorpus/clean_split.json.
Each of the field means:
- book: File name of the book.
- page_link: Link to the smashwords page.
- txt_link: Link to the
.txtfile on the smashwords page. - genre: Genre of the book.
- title: Book name.
- author: Author name.
- start: The first line of the meaningful content (Matched by regular expression. Might need to update when you process your own data.)
- end: The last line of the meaningful content (Matched by regular expression. Might need to update when you process your own data.)
Run the following script. This script will create a folder data/bookcorpus/raw and store all the books there.
It is getting harder and harder to crawl books from Smashwords.com. Please try it several times.
python get_books.pySegment the book using the following script. This script will create a folder data/bookcorpus/segment and store all the segemented books there.
python segment_bookcorpus.pyParse semantic frames using open-sesame (Plesase follow the open-sesame's instruction to set up all the model and data first). I put the python2 version of open-sesame in the third-party folder and implement a wrapper of both targetid and frameid modules. Notice that the following script needs python2. This script will create a folder data/bookcorpus/frame and store all the frame information there.
python2 frame_parsing.pyIf you would like to run our implementation of the event-representation. You will need to parse the dependency using stanford's stanza parser.
You can parse it using the following script. This script will create a folder data/bookcorpus/dependency and store all the information there.
python dependency_parsing.py [--gpu 0] [--start_index 0] [--end_index 100000]The newly downloaded data can be slightly different from our version. Therefore, you will need to update the boundary (start and end position in the clean_split.json file). You can run the following command to update the positions.
python update_boundary.pyYou can access the processed CODA-19 data here. Just download it and extract all the data to data/coda19 folder.
https://drive.google.com/drive/folders/1jUaXX9X_EBfCm8kRD0e9BL10VL4rowi6?usp=sharing
If you want to process it by yourself, you will need to run semanic frame parser and depedency parser.
We implement several baselines.
usage: naive_baseline.py [-h] [--device DEVICE] [--block BLOCK] [--data DATA]
[--model MODEL] [--downsample DOWNSAMPLE]
[--skip SKIP]
Naive Baseline.
optional arguments:
-h, --help show this help message and exit
--device DEVICE device used for computing tfidf [cpu/cuda:0/cuda:1]
--block BLOCK story block size
--data DATA Corpus used for training and testing [bookcorpus/coda19]
--model MODEL Model type [replay/prior]
--downsample DOWNSAMPLE Downsampling size
--skip SKIP Skipping distance for replay baselineTo run the replay baseline, use the following command. You can adjust the value of skip to run the replay baseline with a longer distance.
python naive_baseline.py --block 20 --data bookcorpus --model replay --device cuda:0 [--skip 0]To run the prior baseline, use the following command.
python naive_baseline.py --block 20 --data bookcorpus --model prior --device cuda:0 [--downsample 88720]usage: ir_baseline.py [-h] [--device DEVICE] [--block BLOCK] [--data DATA]
[--downsample DOWNSAMPLE]
IR Baseline.
optional arguments:
-h, --help show this help message and exit
--device DEVICE device used for computing tfidf [cpu/cuda:0/cuda:1]
--block BLOCK story block size
--data DATA Corpus used for training and testing [bookcorpus/coda19]
--downsample DOWNSAMPLE Downsampling sizeTo run the ir baseline, use the following command. Since the data is huge, it will require gpu to accerlate. Please specify the gpu resource using the device flag.
python ir_baseline.py --block 20 --data bookcorpus --device cuda:0 [--downsample 88720]usage: ml_baseline.py [-h] [--device DEVICE] [--block BLOCK] [--data DATA]
[--downsample DOWNSAMPLE] [--history HISTORY]
[--n_jobs N_JOBS] [--model MODEL]
ML Baseline (LGBM / RandomForest).
optional arguments:
-h, --help show this help message and exit
--device DEVICE device used for computing tfidf [cpu/cuda:0/cuda:1]
--block BLOCK story block size
--data DATA Corpus used for training and testing [bookcorpus/coda19]
--downsample DOWNSAMPLE Downsampling size
--history HISTORY Number of story blocks used for input
--n_jobs N_JOBS Processes used for computing
--model MODEL ML model. (LGBM / RandomForest)To run the ml baseline, use the following command. The default history flag is None which will only use one previous story block as the input feature. You can specify it to a number n to use n story blocks. The hyper-parameters are hard-coded in the script but feel free to change if needed.
python ml_baseline.py --block 20 --data bookcorpus --device cuda:0 --model LGBM [--history 2] [--n_jobs 10] [--downsample 88720]We also have an ablation study script that is based on ml_baseline.py. You can use the following command to run the ablation study.
The removed_dim is the dimension that you want to remove for the ablation study.
python ablation_exp.py --block 20 --data bookcorpus --device cuda:0 --model LGBM --removed_dim 10 [--n_jobs 10]To run the same experiment using the same setting in our paper, use the following command.
python ablation_exp.pywhere each argument mean:
usage: ablation_exp.py [-h] [--device DEVICE] [--block BLOCK] [--data DATA]
[--n_jobs N_JOBS] [--model MODEL]
[--removed_dim REMOVED_DIM]
Ablation Study for ML Baseline.
optional arguments:
-h, --help show this help message and exit
--device DEVICE device used for computing tfidf [cpu/cuda:0/cuda:1]
--block BLOCK story block size
--data DATA Corpus used for training and testing [bookcorpus/coda19]
--n_jobs N_JOBS Processes used for computing
--model MODEL ML model. [LGBM / RandomForest]
--removed_dim REMOVED_DIM Dimention you want to remove.usage: dae_baseline.py [-h] [--device DEVICE] [--block BLOCK] [--data DATA]
[--downsample DOWNSAMPLE] [--history HISTORY]
[--hidden_size HIDDEN_SIZE] [--layer_num LAYER_NUM]
[--dropout_rate DROPOUT_RATE] [--epoch_num EPOCH_NUM]
[--batch_size BATCH_SIZE]
[--learning_rate LEARNING_RATE]
[--early_stop EARLY_STOP]
DAE Baseline.
optional arguments:
-h, --help show this help message and exit
--device DEVICE device used for computing tfidf and training [cpu/cuda:0/cuda:1]
--block BLOCK story block size
--data DATA Corpus used for training and testing [bookcorpus/coda19]
--downsample DOWNSAMPLE Downsampling size
--history HISTORY Number of story blocks used for input
--hidden_size HIDDEN_SIZE Hidden size of the DAE model
--layer_num LAYER_NUM Number of layers of the DAE model
--dropout_rate DROPOUT_RATE Dropout rate for the DAE model
--epoch_num EPOCH_NUM Number of training epoch
--batch_size BATCH_SIZE Batch size for training
--learning_rate LEARNING_RATE Learning rate for training
--early_stop EARLY_STOP Number of epoch for early stopUse the following command to run the model. Default hyper-parameters are all set up in the argparser but feel free to change it if needed.
python dae_baseline.py --block 20 --device cuda:0 --data bookcorpus --downsample 1000 --epoch_num 10usage: bert_baseline.py [-h] [--device DEVICE] [--version VERSION]
[--epoch_num EPOCH_NUM] [--block BLOCK]
[--batch_size BATCH_SIZE]
[--eval_batch_size EVAL_BATCH_SIZE]
[--learning_rate LEARNING_RATE]
[--early_stop_epoch EARLY_STOP_EPOCH]
[--valid_sample_num VALID_SAMPLE_NUM]
[--train_sample_num TRAIN_SAMPLE_NUM]
[--max_len MAX_LEN] [--data_name DATA_NAME]
[--model_type MODEL_TYPE] [--downsample DOWNSAMPLE]
[--possible_batch_size POSSIBLE_BATCH_SIZE]
[--history HISTORY]
Bert Baseline.
optional arguments:
-h, --help show this help message and exit
--device DEVICE Device used for training
--version VERSION Naming for version control
--epoch_num EPOCH_NUM Numbers of training epochs
--block BLOCK Size of the story block
--max_len MAX_LEN The maximum length of tokens
--data_name DATA_NAME Corpus used for training and testing
--model_type MODEL_TYPE Pretrained model [bert / scibert]
--downsample DOWNSAMPLE Downsampling size
--possible_batch_size POSSIBLE_BATCH_SIZE
--history HISTORY Number of past story blocks used for input
--batch_size BATCH_SIZE Training batch size
--eval_batch_size EVAL_BATCH_SIZE Evaluating batch size
--learning_rate LEARNING_RATE Learning rate used for the adam optimizer
--early_stop_epoch EARLY_STOP_EPOCH Number of epochs for early stopping if there is no improvement
--valid_sample_num VALID_SAMPLE_NUM Number of instances used for validation
--train_sample_num TRAIN_SAMPLE_NUM Number of instances used for training in each epochUse the following command to run the bert baseline. You can change possible_batch_size to match the GPU resource you have.
The script will process in possible_batch_size but will only update the parameters once it meets the batch_size.
Change model_type to scibert if needed.
python bert_baseline.py --data_name bookcorpus --block 20 --device cuda:0 --epoch_num 200 --early_stop_epoch 5 --model_type bert --batch_size 32 --history 1 [--possible_batch_size 2] [--downsample 88720]The script is borrowed from huggingface's sample script. We follow all the default parameters in their implementation. Added arguments are described as follow.
usage: generation_baseline.py [-h] --model_type MODEL_TYPE
--model_name_or_path MODEL_NAME_OR_PATH
[--prompt PROMPT] [--length LENGTH]
[--stop_token STOP_TOKEN]
[--temperature TEMPERATURE]
[--repetition_penalty REPETITION_PENALTY]
[--k K] [--p P] [--prefix PREFIX]
[--padding_text PADDING_TEXT]
[--xlm_language XLM_LANGUAGE] [--seed SEED]
[--no_cuda]
[--num_return_sequences NUM_RETURN_SEQUENCES]
[--fp16] [--block BLOCK]
[--sample_num SAMPLE_NUM]
optional arguments:
--block BLOCK Story block size
--sample_num SAMPLE_NUM Number of instancesYou can run the following command to generate the stories. We use length 70, 150, 300, and 700 for block sizes 5, 10, 20, and 50, respectively.
python generation_baseline.py --model_type gpt2 --model_name_or_path gpt2 --block 20 --sample_num 10 --length 300Then parse them using the following command. Change block size if needed. Note that the parsing script will need to be run in python2.
python2 parse_gpt2_story.py --block 20Then compute the scores. Change block size if needed.
python eval_generation_baseline.py --block 20To process the data, you will need to use Stanford's stanza parser to get all the dependency and parsing tree first. Check out the Parsing Dependency section above.
After getting all the data ready, you can run event_data.py script to generate event tuples alone with the semantic frame representation.
python event_data.py --block 20 --data bookcorpus [--history 1]Here are the information of the arguments.
usage: event_data.py [-h] [--block BLOCK] [--data DATA] [--history HISTORY]
Data Pre-processing for Event-Representation Baseline.
optional arguments:
-h, --help show this help message and exit
--block BLOCK story block size
--data DATA Corpus used for training and testing [bookcorpus/coda19]
--history HISTORY Number of story blocks used for inputWhen all the data is ready, run the following command to train the event-representation model. All the hyper-parameters used in our paper are set as the default values for their coresponding arguments. But feel free to change the parameters.
python event_baseline.py --data_name bookcorpusHere are the information of the arguments.
usage: event_baseline.py [-h] [--device DEVICE] [--epoch_num EPOCH_NUM]
[--early_stop_epoch EARLY_STOP_EPOCH]
[--learning_rate LEARNING_RATE]
[--batch_size BATCH_SIZE]
[--evaluation_batch_size EVALUATION_BATCH_SIZE]
[--possible_batch_size POSSIBLE_BATCH_SIZE]
[--save_model_freq SAVE_MODEL_FREQ]
[--hidden_size HIDDEN_SIZE] [--layer_num LAYER_NUM]
[--dropout_rate DROPOUT_RATE]
[--block_size BLOCK_SIZE] [--max_len MAX_LEN]
[--data_name DATA_NAME] [--downsample DOWNSAMPLE]
[--exp_name EXP_NAME] [--history HISTORY]
Event-Representation Baseline Training Script.
optional arguments:
-h, --help show this help message and exit
--device DEVICE Device used for training and evaluation
--epoch_num EPOCH_NUM Number of training epochs
--early_stop_epoch EARLY_STOP_EPOCH Number of epochs for early stop when there is no improvement
--learning_rate LEARNING_RATE Learning rate for optimizer
--batch_size BATCH_SIZE Batch size of the training process
--evaluation_batch_size EVALUATION_BATCH_SIZE Evaluation batch size
--possible_batch_size POSSIBLE_BATCH_SIZE Maximum possible match size on your device
--save_model_freq SAVE_MODEL_FREQ Number of epochs for saving the model periodically
--hidden_size HIDDEN_SIZE Hidden size of the LSTM
--layer_num LAYER_NUM Number of layers of the LSTM
--dropout_rate DROPOUT_RATE Dropout rate of the model
--block_size BLOCK_SIZE Story block size
--data_name DATA_NAME Corpus used for training
--downsample DOWNSAMPLE Downsample size
--exp_name EXP_NAME Experiment name for version control
--history HISTORY Number of story blocks used for inputWe release the LGBM models. If you want to use the existing models for prediction. Please go to the following link to download the models! Notice that you will need to follow the above data processing steps to prepare the data first. https://drive.google.com/drive/folders/15WxGuj6BJXI3L5FOg0grjq6aTZiqXqD6?usp=sharing
Here is the main result table on Bookcorpus and LGBM work relatively better when story blocks are larger. As a result, we choose to release LGBM models first. We will release the BERT model soon to help people get better prediction when story blocks are smaller. (But you can still train the model on your own!)

If you have any question, please contact me at chiehyang@psu.edu. I will be happy to answer your questions :").