MLgrabbag - Machine Learning grab bag: includes (pedagogical) examples and implementations of Machine Learning; notes
- Notes on
theano - Installation of NVIDIA CUDA on Fedora 23 Workstation (Linux)
- Recovering from disastrous
dnf updatethat adds a new kernel and trashes video output, 2nd. time - Might as well, while we're at it, update NVidia proprietary drivers and CUDA Toolkit
- Recovering from disastrous
- Installation of
tensorflow,tensorflow-gpu - Sample, input data,
$X$ -
sampleinputdataX_sklearn- collection of sample data fromsklearn
-
-
-
theano_ML.ipynb- Coursera's Introduction to Machine Learning, taught by Ng, but with the syntax translated intotheano, and to *run on the GPU *.- Notably, Week 1 Linear Algebra Review of Coursera's Machine Learning Introduction, taught by Ng is translated into
theanoon the GPU -
./CUDNN/Example scripts, examples of using CUDNN, directly
- Notably, Week 1 Linear Algebra Review of Coursera's Machine Learning Introduction, taught by Ng is translated into
-
Create a directory for a virtual environment:
/cuBlackDream$ python3 -m venv ./venv/
Activate it:
/cuBlackDream$ source ./venv/bin/activate
You should see the prompt have a prefix (venv).
Deactivate it:
deactivate
| filename | directory | Description |
|---|---|---|
| tutorial_theano.ipynb | ./ |
jupyter notebook based on Theano's documentation tutorial |
| supervised-theano.ipynb | ./ |
Further explorations of supervised learning with theano, in a jupyter notebook |
simple_logreg.py |
./ |
Simple logistic regression, from Theano's documentation's tutorial |
theano_ML.ipynb |
./ |
jupyter notebook based on Coursera's Introduction to Machine Learning, taught by Ng |
simple_logreg.py- from Theano's documentation and its tutorial, to run this on the GPU, I used the following:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python simple_logreg.py
Installation of NVIDIA’s CUDA Toolkit on a Fedora 23 Workstation was nontrivial; part of the reason is that it appears that 7.5 is the latest version of the CUDA Toolkit (as of 20150512), and 7.5 only supports (for sure) Fedora 21. And, this 7.5 version supports (out of the box) C compiler gcc up to version 4.* and not gcc 5. But there’s no reason why the later versions, Fedora 23 as opposed to Fedora 21, gcc 5 vs. gcc 4.*, cannot be used (because I got CUDA to work on my setup, including samples). But I found that I had to make some nontrivial symbolic linking (ln).
I wanted to install CUDA for Udacity’s Intro to Parallel Programming, and in particular, in the very first lesson or video, Intro to the Class, for instructions on running CUDA locally, only the links to the official NVIDIA documentation were given, in particular for Linux,
http://docs.nvidia.com/cuda/cuda-getting-started-guide-for-linux/index.html
But one only needs to do a Google search and read some forum posts that installing CUDA, Windows, Mac, or Linux, is highly nontrivial.
I’ll point out how I did it, and refer to the links that helped me (sometimes you simply follow, to the letter, the instructions there) and other links in which you should follow the instructions, but modify to suit your (my) system, and what NOT to do (from my experience).
My install procedure assumes you are using the latest proprietary NVIDIA Accelerated Graphics Drivers for Linux. I removed and/or blacklisted any other open-source versions of nvidia drivers, and in particular blacklisted nouveau. See my blog post for details and description.
-
Download the latest CUDA Toolkit (appears to be 7.5 as of 20160512). For my setup, I clicked on the boxes Linux for Operation System, x86_64 for Architecture, Fedora for Distribution, 21 for Version (only one there), runfile (local) for Installer Type (it was the first option that appeared). Then I modified the instructions on their webpage:
- Run
sudo sh cuda_7.5.18_linux.run - Follow the command-line prompts.
- Run
Instead, I did
$ sudo sh cuda_7.5.18_linux.run --override
with the - -override flag to use gcc 5 so I did not have to downgrade to gcc 4.*.
Here is how I selected my options at the command-line prompts (and part of the result):
$ sudo sh cuda_7.5.18_linux.run --override
-------------------------------------------------------------
Do you accept the previously read EULA? (accept/decline/quit): accept
You are attempting to install on an unsupported configuration. Do you wish to continue? ((y)es/(n)o) [ default is no ]: yes
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 352.39? ((y)es/(n)o/(q)uit): n
Install the CUDA 7.5 Toolkit? ((y)es/(n)o/(q)uit): y
Enter Toolkit Location [ default is /usr/local/cuda-7.5 ]:
Do you want to install a symbolic link at /usr/local/cuda? ((y)es/(n)o/(q)uit): y
Install the CUDA 7.5 Samples? ((y)es/(n)o/(q)uit): y
Enter CUDA Samples Location [ default is /home/[yournamehere] ]: /home/[yournamehere]/Public
Installing the CUDA Toolkit in /usr/local/cuda-7.5 ...
Missing recommended library: libGLU.so
Missing recommended library: libX11.so
Missing recommended library: libXi.so
Missing recommended library: libXmu.so
Installing the CUDA Samples in /home/[yournamehere]/ ...
Copying samples to /home/propdev/Public/NVIDIA_CUDA-7.5_Samples now...
Finished copying samples.
Again, Fedora 23 was not a supported configuration, but I wished to continue. I had already installed NVIDIA Accelerated Graphics Driver for Linux (that’s how I was seeing my X graphical environment) but it was a later version *361. ** and I did not want to uninstall it and then reinstall, which was recommended by other webpages (I had already gone through the mini-nightmare of reinstalling these drivers before, which can trash your X11 environment that you depend on for a functioning GUI).
- Continuing, this was also printed out by CUDA’s installer:
Installing the CUDA Samples in /home/propdev/Public ... Copying samples to /home/propdev/Public/NVIDIA_CUDA-7.5_Samples now... Finished copying samples.
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-7.5
Samples: Installed in /home/[yournamehere]/Public, but missing recommended libraries
Please make sure that
- PATH includes /usr/local/cuda-7.5/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-7.5/lib64, or, add /usr/local/cuda-7.5/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-7.5/bin
To uninstall the NVIDIA Driver, run nvidia-uninstall
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-7.5/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 352.00 is required for CUDA 7.5 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run -silent -driver
Logfile is /tmp/cuda_install_7123.log
For “ PATH includes /usr/local/cuda-7.5 ” I do
$ export PATH=/usr/local/cuda-7.5/bin:$PATH
as suggested by Chapter 6 of CUDA_Getting_Started_Linux.pdf
Dealing with the LD_LIBRARY_PATH, I did this: I created a new text file (open up your favorite text editor) in /etc/ld.so.conf.d called cuda.conf, e.g. I used emacs:
sudo emacs cuda.conf
and I pasted in the directory
/usr/local/cuda-7.5/lib64
(since my setup is 64-bit) into this text file. I did this because my /etc/ld.so.conf file includes files from /etc/ld.so.conf.d, i.e. it says
include ld.so.conf.d/*.conf
Make sure this change for LD_LIBRARY_PATH is made by running the command
ldconfig
as root.
I check the status of this “linking” to PATH and LD_LIBRARY_PATH with the echo command, each time I reboot, or log back in, or start a new Terminal window:
echo $PATH
echo $LD_LIBRARY_PATH
- Patch the
host_config.hheader file
cf. Install NVIDIA CUDA on Fedora 22 with gcc 5.1 and CUDA incompatible with my gcc version
To use gcc 5 instead of gcc 4.*, I needed to patch the host_config.h header file because I kept receiving errors. What worked for me was doing this to the file - original version:
#if __GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ > 9)
#error -- unsupported GNU version! gcc versions later than 4.9 are not supported!
#endif /* __GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ > 9) */
Commented-out version (these 3 lines)
// #if __GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ > 9)
// #error -- unsupported GNU version! gcc versions later than 4.9 are not supported!
// #endif /* __GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ > 9) */
Afterwards, I did not have any problems with c compiler gcc incompatibility (yet).
- At this point CUDA runs without problems if no graphics capabilities are needed. For instance, as a sanity check, I ran, from the installed samples with CUDA, I made
deviceQueryand ran it:
$ cd ~/NVIDIA_CUDA-7.5_Samples/1_Utilities/deviceQuery
$ make -j12
$ ./deviceQuery
And then if your output looks something like this, then success!
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 980 Ti"
CUDA Driver Version / Runtime Version 8.0 / 7.5
CUDA Capability Major/Minor version number: 5.2
Total amount of global memory: 6143 MBytes (6441730048 bytes)
(22) Multiprocessors, (128) CUDA Cores/MP: 2816 CUDA Cores
GPU Max Clock rate: 1076 MHz (1.08 GHz)
Memory Clock rate: 3505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 3 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 1, Device0 = GeForce GTX 980 Ti
Result = PASS
Getting the other samples to run, getting CUDA to have graphics capabilities, soft symbolic linking to the existing libraries.
The flow or general procedure I ended up having to do was to use locate to find the relevant *.so.* or *.h file for the missing library or missing header, respectively, and then making soft symbolic links to them with the ln -s command. I found that some of the samples have different configurations for in which directory the graphical libraries are (GL, GLU, X11, glut, etc.) than other samples in the samples included by NVIDIA.
NVIDIA CUDA Getting Started Guide for Linux - CUDA_Getting_Started_Linux.pdf
"Your LD_LIBRARY_PATH environment variable is not set up correctly. Ensure that your LD_LIBRARY_PATH includes the lib and/or lib64 directory where you installed the Toolkit, usually /usr/local/cuda-7.0/lib{,64}:" (replace 7.0 with whatever version you're on; mine is 7.5)
$ export LD_LIBRARY_PATH=/usr/local/cuda-7.0/lib:$LD_LIBRARY_P
** 20161031 update **
I was on an administrator account and I had forgotten my prior experience and learned admonition NOT to do dnf update and I accidentally ran
dnf update
I had done this before and written about this and the subsequent recovery, before, in the post Fedora 23 workstation (Linux)+NVIDIA GeForce GTX 980 Ti: my experience, log of what I do (and find out), and also up above in this README.md.
I relied upon 2 webpages for the critical, almost life-saving, terminal commands to recover video output and the previous, working "good" kernel - they were such a life-saver that they're worth repeating and I've saved a html copy of the 2 pages onto this github repository:
- if note true then false "Fedora 24/23/22 nVidia Drivers Install Guide"
- Step by step how to remove Fedora kernel - very crucial in removing the offending new kernel that
dnf updateautomatically had installed.
lspci | grep VGA
lspci | grep -E "VGA|3D"
lspci | grep -i "VGA"
uname -a
Critical commands:
rpm -qa | grep ^kernel
uname -r
sudo yum remove kernel-core-4.7.9-100.fc23.x86_64 kernel-devel-4.7.9-100.fc23.x86_64 kernel-modules-4.7.9-100.fc23.x86_64 kernel-4.7.9-100.fc23.x86_64 kernel-headers-4.7.9-100.fc23.x86_64
While at the terminal prompt (in low-resolution), change to the directory where you had downloaded the NVidia drivers (hopefully it's there somewhere already on your hard drive because you wouldn't have web browser capability without video output):
sudo sh ./NVIDIA-Linux-x86_64-361.42.run
reboot
dnf install gcc
dnf install dkms acpid
dnf install kernel-headers
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf
cd /etc/sysconfig
grub2-mkconfig -o /boot/efi/EFI/fedora/grub.cfg
dnf list xorg-x11-drv-nouveau
dnf remove xorg-x11-drv-nouveau
cd /boot
## Backup old initramfs nouveau image ##
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau20161031.img
(the last command, with the output file name, the output file's name is arbitrary)
## Create new initramfs image ##
dracut /boot/initramfs-$(uname -r).img $(uname -r)
systemctl set-default multi-user.target
At this point, you'll notice that dnf update and its subsequent removal would've trashed your C++ setup. For at this point, I tried to do a make of a C++ project I had:
[topolo@localhost MacCor1d_gfx]$ make
/usr/local/cuda/bin/nvcc -std=c++11 -g -G -Xcompiler "-Wall -Wno-deprecated-declarations" -L/usr/local/cuda/samples/common/lib/linux/x86_64 -lglut -lGL -lGLU -dc main.cu -o main.o
gcc: error trying to exec 'cc1plus': execvp: No such file or directoryMakefile:21: recipe for target 'main.o' failedmake: *** [main.o] Error 1
So you'll have to do
dnf install gcc-c++
Updating the NVidia proprietary driver - similar to installing, but remember you have to go into the low-resolution, no video driver, terminal, command line, prompt
chmod +x NVIDIA-Linux-x86_64-367.57.run
systemctl set-default multi-user.target
reboot
./NVIDIA-Linux-x86_64-367.57.run
systemctl set-default graphical.target
reboot
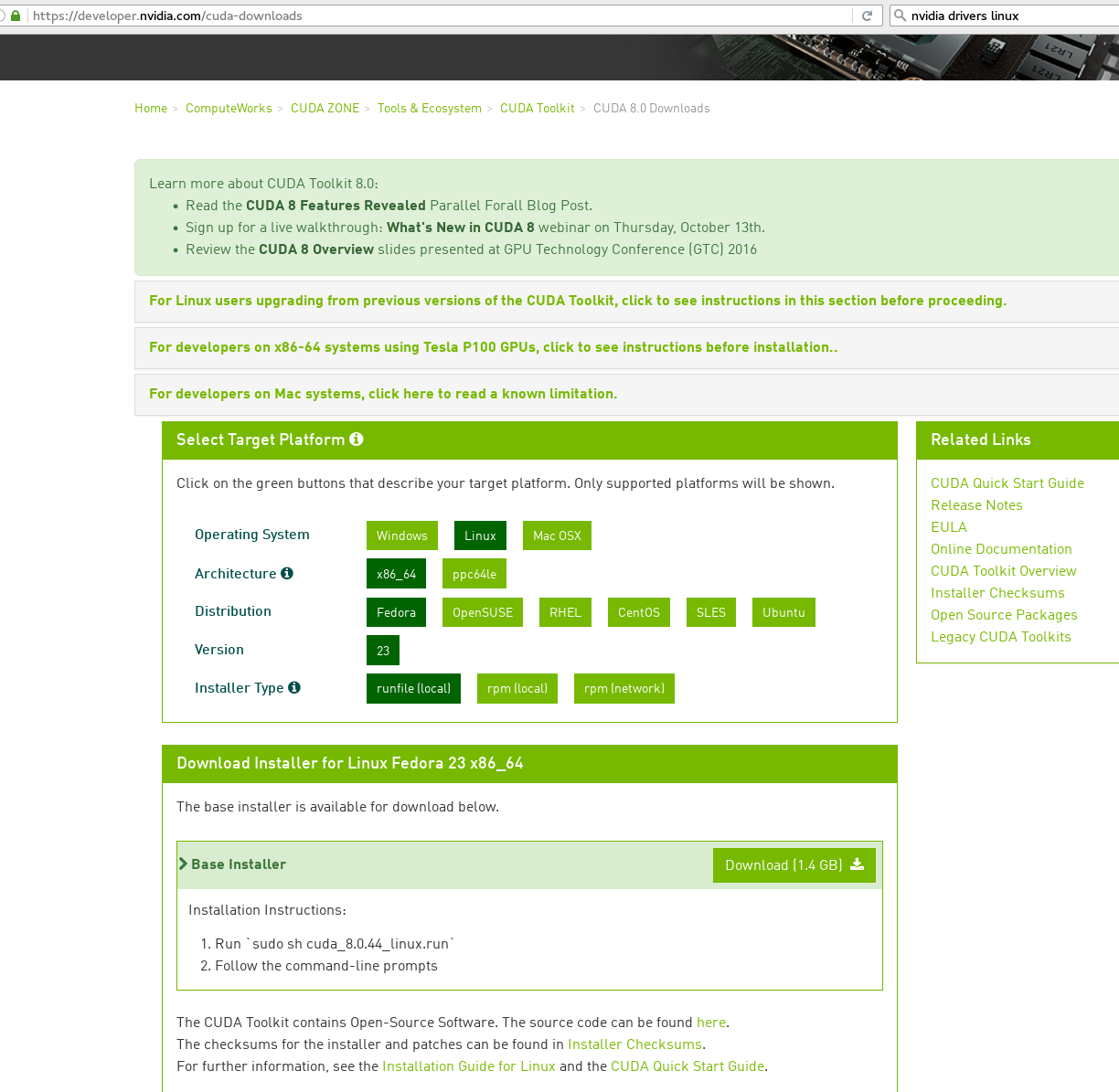
Then follow the instructions. If the driver is updated already, before using the ".run" installation, then choose no to installing drivers - otherwise, I had chosen yes and the default for all the options.
The Linux installation guide for CUDA Toolkit 8.0 is actually very thorough, comprehensive, and easy to use. Let's look at the Post-Installation Actions, the Environment Setup:
The PATH variable needs to include /usr/local/cuda-8.0/bin
To add this path to the PATH variable:
$ export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
In addition, when using the runfile installation method, the LD_LIBRARY_PATH variable needs to contain /usr/local/cuda-8.0/lib64 on a 64-bit system, or /usr/local/cuda-8.0/lib on a 32-bit system
To change the environment variables for 64-bit operating systems:
$ export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Indeed, prior to adding the PATH variable, I was getting errors when I type nvcc at the command line. After doing this:
[propdev@localhost ~]$ export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
[propdev@localhost ~]$ env | grep '^PATH'
PATH=/usr/local/cuda-8.0/bin:/home/propdev/anaconda2/bin:/home/propdev/anaconda2/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/home/propdev/.local/bin:/home/propdev/bin
[propdev@localhost ~]$ nvcc
nvcc warning : The 'compute_20', 'sm_20', and 'sm_21' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
nvcc fatal : No input files specified; use option --help for more information
[propdev@localhost ~]$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Sun_Sep__4_22:14:01_CDT_2016
Cuda compilation tools, release 8.0, V8.0.44
I obtain what I desired - I can use nvcc at the command line.
To get the samples that use OpenGL, be sure to have glut and/or freeglut installed:
dnf install freeglut freeglut-devel
Now for some bloody reason (please let me know), the command
$ export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
still didn't help me to allow my CUDA programs utilize the libraries in that lib64 subdirectory of the CUDA Toolkit. It seems like the programs, or the OS, wasn't seeing the link that should be there in /usr/lib64.
What did work was in here, libcublas.so.7.0: cannot open shared object file, with the solution at the end, from atv, with an answer originally from txbob (most likely Robert Cravello of github)
Solved. Finally I did:
sudo echo "/usr/local/cuda-7.0/lib64" > /etc/ld.so.conf.d/cuda.conf
sudo ldconfig
Thanks a lot txbob!
This is what I did:
[root@localhost ~]# sudo echo "/usr/local/cuda-8.0/lib64" > /etc/ld.so.conf.d/cuda.conf
[root@localhost ~]# sudo ldconfig
ldconfig: /usr/local/cuda-7.5/lib64/libcudnn.so.5 is not a symbolic link
and it worked; C++ programs compile with my make files.
Also, files, including in the Samples for the 8.0 Toolkit, using nvrtc compiled and worked.
Doing
nvidia-smi
at the command prompt gave me this:
[propdev@localhost ~]$ nvidia-smi
Mon Oct 31 15:28:30 2016
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.57 Driver Version: 367.57 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 980 Ti Off | 0000:03:00.0 On | N/A |
| 0% 50C P8 22W / 275W | 423MiB / 6077MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1349 G /usr/libexec/Xorg 50MiB |
| 0 19440 G /usr/libexec/Xorg 162MiB |
| 0 19645 G /usr/bin/gnome-shell 127MiB |
| 0 24621 G /usr/libexec/Xorg 6MiB |
+-----------------------------------------------------------------------------+
cf. Install GPU TensorFlow From Sources w/ Ubuntu 16.04 and Cuda 8.0
How to Install TensorFlow on Fedora with CUDA GPU acceleration
cf. https://www.tensorflow.org/get_started/os_setup
" Download cuDNN v5.1.
Uncompress and copy the cuDNN files into the toolkit directory. Assuming the toolkit is installed in /usr/local/cuda, run the following commands (edited to reflect the cuDNN version you downloaded):
tar xvzf cudnn-8.0-linux-x64-v5.1-ga.tgz
sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
"
for cp, -P is -P, --no-dereference never follow symbolic links in SOURCE cf. http://www.unix.com/man-page/linux/1/cp/ In the directory that I had "unzipped" (un-tarball'ed), e.g. /home/propdev/Public/Cudnn So I did:
sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include
Password is needed, so you have to be logged in as root or administrator. Next,
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
Note that for the chmod, the flags mean this:
a all all 3 of u,g,o, owner, group, others
- adds specified modes to specified classes
r read read a file or list a directory's contents
cf. https://en.wikipedia.org/wiki/Chmod
I had obtained this error when I fired up python in terminal and tried to import tensorflow as tf.
[topolo@localhost MLgrabbag]$ python
Python 2.7.11 |Anaconda 4.0.0 (64-bit)| (default, Jun 15 2016, 15:21:30)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Anaconda is brought to you by Continuum Analytics.
Please check out: http://continuum.io/thanks and https://anaconda.org
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:119] Couldn't open CUDA library libcudnn.so. LD_LIBRARY_PATH: /usr/local/lib:/usr/local/lib:
I tensorflow/stream_executor/cuda/cuda_dnn.cc:3459] Unable to load cuDNN DSO
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcurand.so locally
>>>
[topolo@localhost MLgrabbag]$ echo $LD_LIBRARY_PATH
/usr/local/lib:/usr/local/lib:
[topolo@localhost MLgrabbag]$ export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
[topolo@localhost MLgrabbag]$ echo $LD_LIBRARY_PATH
/usr/local/cuda/lib64:/usr/local/lib:/usr/local/lib:
[topolo@localhost MLgrabbag]$ import tensorflow as tf
[topolo@localhost MLgrabbag]$
[topolo@localhost MLgrabbag]$ echo $LD_LIBRARY_PATH
/usr/local/cuda/lib64:/usr/local/lib:/usr/local/lib:
[topolo@localhost MLgrabbag]$ python
Python 2.7.11 |Anaconda 4.0.0 (64-bit)| (default, Jun 15 2016, 15:21:30)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Anaconda is brought to you by Continuum Analytics.
Please check out: http://continuum.io/thanks and https://anaconda.org
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcudnn.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:128] successfully opened CUDA library libcurand.so locally
>>>
In short, to effectively **add a library to the environment, env, do this:
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
- Bazel : I decided not to install bazel and so I couldn't compile or build from the github repository for bazel, but instead used pip.
cf. Find all packages installed with easy_install/pip?
pip freeze
pip show [options] <package>
https://github.com/davidadamojr/TextRank/blob/master/textrank/__init__.py
"""Python implementation of the TextRank algoritm. From this paper: https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf Based on: https://gist.github.com/voidfiles/1646117 https://github.com/davidadamojr/TextRank """ import io import itertools import networkx as nx import nltk import os
def setup_environment(): """Download required resources.""" nltk.download('punkt') nltk.download('averaged_perceptron_tagger') print('Completed resource downloads.')
def filter_for_tags(tagged, tags=['NN', 'JJ', 'NNP']): """Apply syntactic filters based on POS tags.""" return [item for item in tagged if item[1] in tags]
def normalize(tagged): """Return a list of tuples with the first item's periods removed.""" return [(item[0].replace('.', ''), item[1]) for item in tagged]
def unique_everseen(iterable, key=None): """List unique elements in order of appearance. Examples: unique_everseen('AAAABBBCCDAABBB') --> A B C D unique_everseen('ABBCcAD', str.lower) --> A B C D """ seen = set() seen_add = seen.add if key is None: for element in [x for x in iterable if x not in seen]: seen_add(element) yield element else: for element in iterable: k = key(element) if k not in seen: seen_add(k) yield element
def levenshtein_distance(first, second): """Return the Levenshtein distance between two strings. Based on: http://rosettacode.org/wiki/Levenshtein_distance#Python """ if len(first) > len(second): first, second = second, first distances = range(len(first) + 1) for index2, char2 in enumerate(second): new_distances = [index2 + 1] for index1, char1 in enumerate(first): if char1 == char2: new_distances.append(distances[index1]) else: new_distances.append(1 + min((distances[index1], distances[index1 + 1], new_distances[-1]))) distances = new_distances return distances[-1]
def build_graph(nodes): """Return a networkx graph instance. :param nodes: List of hashables that represent the nodes of a graph. """ gr = nx.Graph() # initialize an undirected graph gr.add_nodes_from(nodes) nodePairs = list(itertools.combinations(nodes, 2))
# add edges to the graph (weighted by Levenshtein distance)
for pair in nodePairs:
firstString = pair[0]
secondString = pair[1]
levDistance = levenshtein_distance(firstString, secondString)
gr.add_edge(firstString, secondString, weight=levDistance)
return gr
def extract_key_phrases(text): """Return a set of key phrases. :param text: A string. """ # tokenize the text using nltk word_tokens = nltk.word_tokenize(text)
# assign POS tags to the words in the text
tagged = nltk.pos_tag(word_tokens)
textlist = [x[0] for x in tagged]
tagged = filter_for_tags(tagged)
tagged = normalize(tagged)
unique_word_set = unique_everseen([x[0] for x in tagged])
word_set_list = list(unique_word_set)
# this will be used to determine adjacent words in order to construct
# keyphrases with two words
graph = build_graph(word_set_list)
# pageRank - initial value of 1.0, error tolerance of 0,0001,
calculated_page_rank = nx.pagerank(graph, weight='weight')
# most important words in ascending order of importance
keyphrases = sorted(calculated_page_rank, key=calculated_page_rank.get,
reverse=True)
# the number of keyphrases returned will be relative to the size of the
# text (a third of the number of vertices)
one_third = len(word_set_list) // 3
keyphrases = keyphrases[0:one_third + 1]
# take keyphrases with multiple words into consideration as done in the
# paper - if two words are adjacent in the text and are selected as
# keywords, join them together
modified_key_phrases = set([])
# keeps track of individual keywords that have been joined to form a
# keyphrase
dealt_with = set([])
i = 0
j = 1
while j < len(textlist):
first = textlist[i]
second = textlist[j]
if first in keyphrases and second in keyphrases:
keyphrase = first + ' ' + second
modified_key_phrases.add(keyphrase)
dealt_with.add(first)
dealt_with.add(second)
else:
if first in keyphrases and first not in dealt_with:
modified_key_phrases.add(first)
# if this is the last word in the text, and it is a keyword, it
# definitely has no chance of being a keyphrase at this point
if j == len(textlist) - 1 and second in keyphrases and \
second not in dealt_with:
modified_key_phrases.add(second)
i = i + 1
j = j + 1
return modified_key_phrases
def extract_sentences(text): """Return a paragraph formatted summary of the source text. :param text: A string. """ sent_detector = nltk.data.load('tokenizers/punkt/english.pickle') sentence_tokens = sent_detector.tokenize(text.strip()) graph = build_graph(sentence_tokens)
calculated_page_rank = nx.pagerank(graph, weight='weight')
# most important sentences in ascending order of importance
sentences = sorted(calculated_page_rank, key=calculated_page_rank.get,
reverse=True)
# return a 100 word summary
summary = ' '.join(sentences)
summary_words = summary.split()
summary_words = summary_words[0:101]
summary = ' '.join(summary_words)
return summary
def write_files(summary, key_phrases, filename): """Write key phrases and summaries to a file.""" print("Generating output to " + 'keywords/' + filename) key_phrase_file = io.open('keywords/' + filename, 'w') for key_phrase in key_phrases: key_phrase_file.write(key_phrase + '\n') key_phrase_file.close()
print("Generating output to " + 'summaries/' + filename)
summary_file = io.open('summaries/' + filename, 'w')
summary_file.write(summary)
summary_file.close()
print("-")
def summarize_all(): # retrieve each of the articles articles = os.listdir("articles") for article in articles: print('Reading articles/' + article) article_file = io.open('articles/' + article, 'r') text = article_file.read() keyphrases = extract_key_phrases(text) summary = extract_sentences(text) write_files(summary, keyphrases, article)
https://github.com/davidadamojr/TextRank/blob/master/main.py
import click import textrank
@click.group() def cli(): pass
@cli.command() def initialize(): """Download required nltk libraries.""" textrank.setup_environment()
@cli.command() @click.argument('filename') def extract_summary(filename): """Print summary text to stdout.""" with open(filename) as f: summary = textrank.extract_sentences(f.read()) print(summary)
@cli.command() @click.argument('filename') def extract_phrases(filename): """Print key-phrases to stdout.""" with open(filename) as f: phrases = textrank.extract_key_phrases(f.read()) print(phrases)
https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
I first convert a pdf into plain text (I print it out and everything is fine) and then I get a UnicodeDecodeError when I try to run word_tokenize() from NLTK.
I get that error despite I try to decode('utf-8').encode('utf-8') on the plain text, beforehand. In the traceback I noticed that the line of code from word_tokenize() that raises the error first is plaintext.split('\n'). This is why I tried to reproduce the error by running split('\n') on the plain text but still, that doesn't rise any error either.
So, I understand neither what is causing the error nor how to avoid it.
Any help would be greatly appreciate it! :) maybe I could avoid it by changing something in the pdf_to_txt file?
Here's the code to tokenize:
from cStringIO import StringIO from nltk.corpus import stopwords from nltk.tokenize import word_tokenize import os import string from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfpage import PDFPage
stopset = stopwords.words('english') path = 'my_folder' listing = os.listdir(path) for infile in listing: text = self.convert_pdf_to_txt(path+infile) text = text.decode('utf-8').encode('utf-8').lower() print text splitted = text.split('\n') filtered_tokens = [i for i in word_tokenize(text) if i not in stopset and i not in string.punctuation]
Here's the method I call in order to convert from pdf to txt:
def convert_pdf_to_txt(self, path): rsrcmgr = PDFResourceManager() retstr = StringIO() codec = 'utf-8' laparams = LAParams() device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams) fp = file(path, 'rb') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True): interpreter.process_page(page) fp.close() device.close() ret = retstr.getvalue() retstr.close() return ret
Here's the traceback of the error I get:
Traceback (most recent call last):
File "/home/iammyr/opt/workspace/task-logger/task_logger/nlp/pre_processing.py", line 65, in obj.tokenizeStopWords() File "/home/iammyr/opt/workspace/task-logger/task_logger/nlp/pre_processing.py", line 29, in tokenizeStopWords filtered_tokens = [i for i in word_tokenize(text) if i not in stopset and i not in string.punctuation] File "/usr/local/lib/python2.7/dist-packages/nltk/tokenize/init.py", line 93, in word_tokenize return [token for sent in sent_tokenize(text) [...] File "/usr/local/lib/python2.7/dist-packages/nltk/tokenize/punkt.py", line 586, in _tokenize_words for line in plaintext.split('\n'): UnicodeDecodeError: 'ascii' codec can't decode byte 0xc2 in position 9: ordinal not in range(128)
Thanks a million and loads of good karma to you! ;) python-2.7 encoding utf-8 nltk pdfminer shareeditflag
What do you mean by "plain text"? What encoding do you have in the file? – tripleee Aug 14 '14 at 19:30 1
Also what's the point of decoding and then immediately encoding? I'm guessing removing the .encode('utf-8') would fix your problem. – tripleee Aug 14 '14 at 19:31
Hi, tripleee, thank you so much for your help! Indeed removing the encoding worked, thanks a lot :) The reason I was decoding and encoding again was because I had read this stackoverflow.com/questions/9644099/… and the codec of the "plain text" was already utf-8 as you can see in convert_pdf_to_txt(). that's part of why i was puzzled as even the decoding shouldn't have been necessary, but still it was. thanks a lot! ;) – iammyr Aug 15 '14 at 9:00
You are turning a piece of perfectly good Unicode string (back) into a bunch of untyped bytes, which Python has no idea how to handle, but desperately tries to apply the ASCII codec on. Remove the .encode('utf-8') and you should be fine.
See also http://nedbatchelder.com/text/unipain.html
https://arxiv.org/pdf/1602.03606.pdf
https://www.quora.com/Natural-Language-Processing-What-are-algorithms-for-auto-summarize-text