

Try Reynir (in Icelandic) at https://greynir.is
Reynir is an exploratory project that aims to extract processable information from Icelandic text, allow natural language querying of that information and facilitate natural language understanding.
Reynir periodically scrapes chunks of text from Icelandic news sites on the web. It employs the Tokenizer and ReynirPackage modules (by the same authors) to tokenize the text and parse the token streams according to a hand-written context-free grammar for the Icelandic language. The resulting parse forests are disambiguated using scoring heuristics to find the best parse trees. The trees are then stored in a database and processed by grammatical pattern matching modules to obtain statements of fact and relations between stated facts.
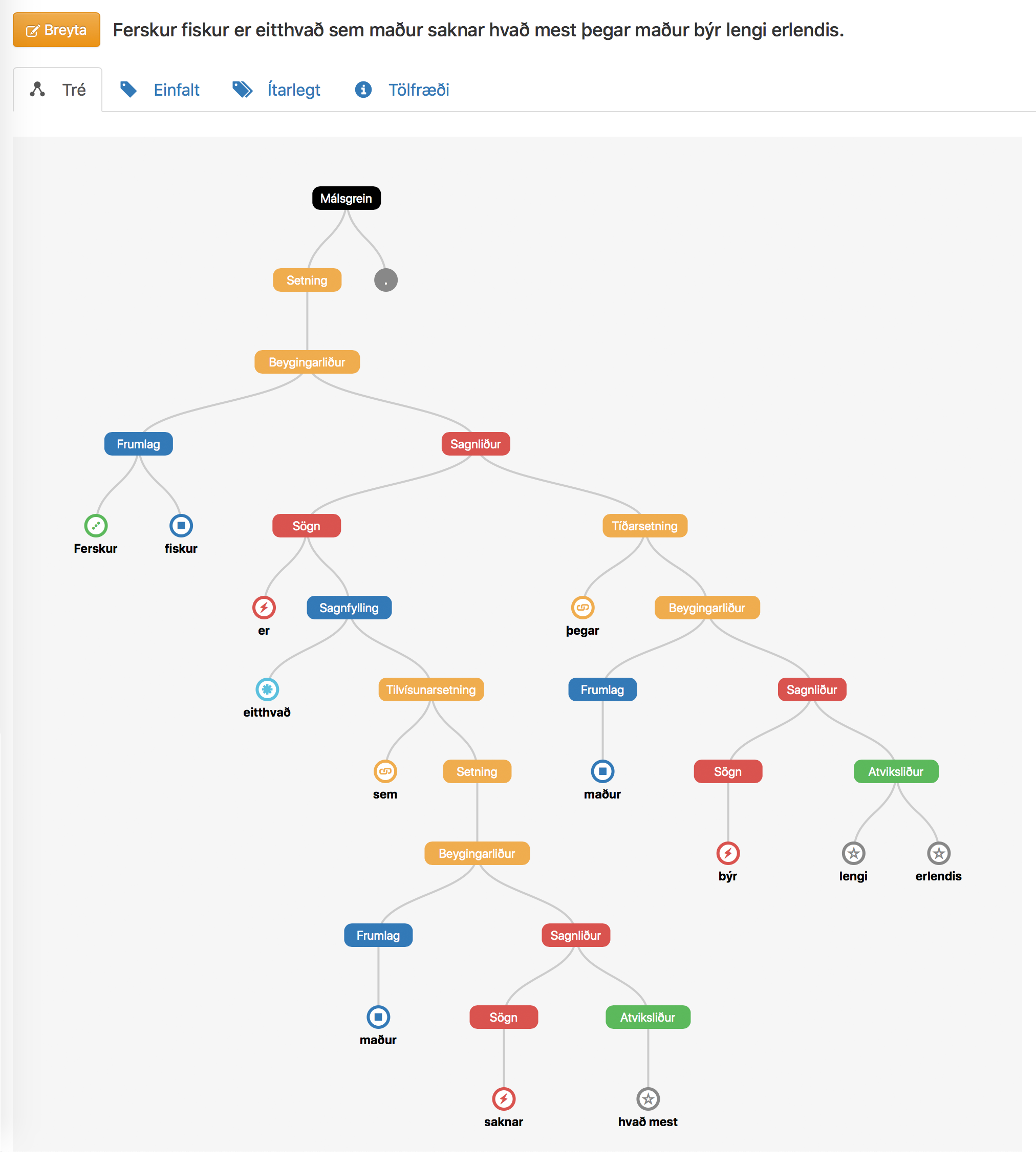
A parse tree as displayed by Reynir. Nouns and noun phrases are blue, verbs and verb phrases are red, adjectives are green, prepositional and adverbial phrases are grey, etc.
Reynir is most effective for text that is objective and factual, i.e. has a relatively high ratio of concrete concepts such as numbers, amounts, dates, person and entity names, etc.
Reynir is innovative in its ability to parse and disambiguate text written in a grammatically complex language, i.e. Icelandic, which does not lend itself easily to statistical parsing methods. Reynir uses grammatical feature agreement (cases, genders, persons, number (singular/plural), verb tenses, modes, etc.) to guide and disambiguate parses. Its highly optimized Earley-based parser, implemented in C++, is fast and compact enough to make real-time while-you-wait analysis of web pages, as well as bulk processing, feasible.
Reynir's goal is to "understand" text to a usable extent by parsing it into structured, recursive trees that directly correspond to the original grammar. These trees can then be further processed and acted upon by sets of Python functions that are linked to grammar nonterminals.
Reynir is currently able to parse about 90% of sentences in a typical news article from the web, and many well-written articles can be parsed completely. It presently has over 300,000 parsed articles in its database, containing 6 million parsed sentences.
Reynir supports natural language querying of its databases. Users can ask about person names, titles and entity definitions and get appropriate replies. The HTML5 Web Speech API is supported to allow queries to be recognized from speech in enabled browsers, such as recent versions of Chrome. Similarity queries are also supported, yielding articles that are similar in content to a given search phrase or sentence.
Reynir may in due course be expanded, for instance:
- to make logical inferences from statements in its database;
- to find statements supporting or refuting a thesis; and/or
- to discover contradictions between statements.
Reynir is written in Python 3 except for its core Earley-based parser module which is written in C++ and called via CFFI. Reynir runs on CPython and PyPy with the latter being recommended.
Reynir works in stages, roughly as follows:
- Web scraper, built on BeautifulSoup and SQLAlchemy storing data in PostgreSQL.
- Tokenizer (this one), extended to use the BÍN database of Icelandic word forms for lemmatization and initial part-of-speech tagging.
- Parser (from this module), using an improved version of the Earley algorithm to parse text according to an unconstrained hand-written context-free grammar for Icelandic that may yield multiple parse trees (a parse forest) in case of ambiguity.
- Parse forest reducer with heuristics to find the best parse tree.
- Information extractor that maps a parse tree via its grammar constituents to plug-in Python functions.
- Article indexer that transforms articles from bags-of-words to fixed-dimensional topic vectors using Tf-Idf and Latent Semantic Analysis.
- Query processor that allows natural language queries for entites in Reynir's database.
Reynir has an embedded web server that displays news articles recently scraped into its database, as well as names of people extracted from those articles along with their titles. The web UI enables the user to type in any URL and have Reynir scrape it, tokenize it and display the result as a web page. Queries can also be entered via the keyboard or using voice input. The server runs on the Flask framework, implements WSGI and can for instance be plugged into Gunicorn and nginx.
Reynir uses the official BÍN (Beygingarlýsing íslensks nútímamáls) lexicon and database of Icelandic word forms to identify word forms, and find their potential meanings and lemmas. The database is included in ReynirPackage in compressed form, under license from and by permission of the BÍN copyright holder.
The tokenizer divides text chunks into sentences and recognizes entities such as dates, numbers, amounts and person names, as well as common abbreviations and punctuation.
Grammar rules are laid out in a separate text file, Reynir.grammar, which is a part
of ReynirPackage. The standard
Backus-Naur form has been
augmented with repeat specifiers for right-hand-side tokens (* for 0..n instances,
+ for 1..n instances, or ? for 0..1 instances). Also, the grammar allows for
compact specification of rules with variants, for instance due to cases, numbers and genders.
Thus, a single rule (e.g. NounPhrase/case/gender → Adjective/case noun/case/gender)
is automatically expanded into multiple rules (12 in this case, 4 cases x 3 genders) with
appropriate substitutions for right-hand-side tokens depending on their local variants.
The parser is an optimized C++ implementation of an Earley parser as enhanced by Scott and Johnstone, referencing Tomita. It parses ambiguous grammars without restriction and returns a compact Shared Packed Parse Forest (SPPF) of parse trees. If a parse fails, it identifies the token at which no parse was available.
The Reynir scraper is typically run in a cron job every 30 minutes to extract
articles automatically from the web, parse them and store the resulting trees
in a PostgreSQL database for further processing.
Scraper modules for new websites are plugged in by adding Python code to the
scrapers/ directory. Currently, the scrapers/default.py module supports
popular Icelandic news sites as well as the site of the Constitutional Council.
Processor modules can be plugged in to Reynir by adding Python code to the
processors/ directory. The demo in processors/default.py extracts person
names and titles from parse trees for storage in a database table.
main.py: WSGI web server application and main module for command-line invocationsettings.py: Management of global settings and configuration data, obtained fromconfig/Reynir.confscraper.py: Web scraper, collecting articles from a set of pre-selected websites (roots)scraperdb.py: Wrapper for the scraper database via SQLAlchemynertokenizer.py: A layer on top of the tokenizer for named entity recognitionprocessor.py: Information extraction from parse treesarticle.py: Representation of an article through its life cycletree.py: Representation of parse trees for processingquery.py: Natural language query processorvectors/builder.py: Article indexer and LSA topic vector builderconfig/Reynir.conf: Editable configuration file for the tokenizer and parserconfig/Main.conf: Various configuration data and preferences, included inReynir.confconfig/Names.conf: Words that should be recognized as person names at the start of sentences, included inReynir.conffetcher.py: Utility classes for fetching articles given their URLsutils/*.py: Various utility programs
Once you have followed the setup and installation instructions above, change to the Reynir repository and activate the virtual environment:
cd Reynir
venv/bin/activate
You should now be able to run Greynir.
python main.py
Defaults to running on localhost:5000 but this can be
changed in config/Reynir.conf.
python scraper.py
If you are running the scraper on macOS, you may run into problems with Python's fork().
This can be fixed by setting the following environment variable in your shell:
export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES
./shell.sh
Starts an IPython shell with a database session (s), the Reynir
parser (r) and all SQLAlchemy database models preloaded. For more info,
see Using the Greynir Shell.
Reynir/Greynir is copyright (C) 2018 by Miðeind ehf. The original author of this software is Vilhjálmur Þorsteinsson.

This set of programs is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This set of programs is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
The full text of the GNU General Public License v3 is included here and also available here: https://www.gnu.org/licenses/gpl-3.0.html.
If you wish to use this set of programs in ways that are not covered under the GPL v3 license, please contact the author.