Released under Apache License v1.1. See LICENSE.txt
Netcon is an operational machine and service monitoring tool. It allows you to setup monitoring for machine paramaters such as CPU, and Disk Usage, as well as services such as HTTP, and MySQL. When any of the reported data for these services meets a set of pre-determined triggers, the people responsible for those services can be notified.
One of Netcon's primary goals is to separate the discovery of individual errors from the notification process. Instead of receiving individual notifications about service problems, which can often include tens or hundreds of notifications, with Netcon the user receives strictly time-periodic updates of the system state during an incident. For example, you might receive one notification every five minutes during an incident, each one telling you how many service failures are still pending on that incident, followed by a notification when the incident is resolved and cleared.
Another primary goal of Netcon is to configure failure conditions not only in terms of discerete failure events (such as service-down), but also in terms of the predicted time to reach a failure threshold. For example, Netcon can be configured to alert you when it's predicted that available diskspace will reach <10% in less than 12 hours. To do this prediction, it uses a simple linear regression of available disk-space over a few time periods.
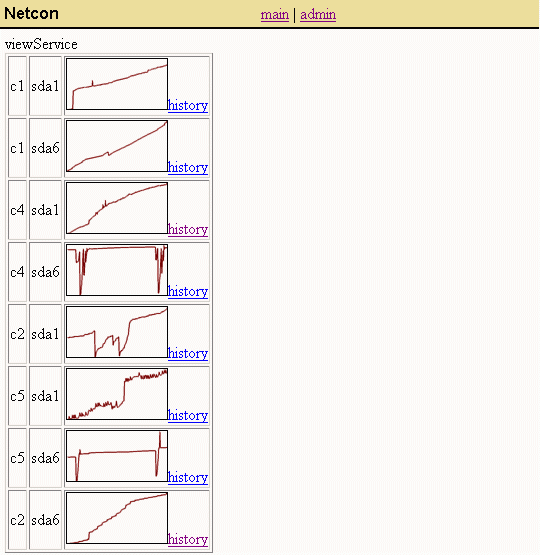
The Netcon data collection uses a uniform and extendable naming
scheme for storing service status metrics. The same history that records
the CPU usage of a machine over time is used to record the duration of a
trigger or failure -- allowing both to leverage the same display and graphing
capabilities. This makes it easy to build up many layers to the system.
For example, by setting up an agent to report to Netcon the user-impact
of an incident, Netcon can report on the user-percieved impact of failures over time.
Netcon's basic architecture borrows my favorite features from other tools. Like QOS, it has a lightweight data-collection agent which is deployed as needed to query data, and which can be easily extended with application-specific collectors. Like Netsaint/Nagios, it has an SQL backend database and a configuration and information browsing UI. Like some larger commercial counterparts, configuration is performed from the Netcon web user-interface. This means it is easy to configure, and since this configuration is stored in the database, this means it is easy to write scripts which modify configuration without fear of breaking a big configuration file.
- data is stored in a MySQL database
- monitoring is performed by a lightweight data-collection client
- configuration data about what to monitor is administered centrally
- custom data-collection clients can be written by extending the Netcon data-collection agent in Python, or by merely speaking the Netcon http protocol
- clients can (optionally) save and report data for disconnected periods
- hierarchial redundant trigger suppression
- services are specified in role-groups and applied to a set of machines
One way to understand Netcon is to consider the flow of monitored data through the system. Here is a description of the cycle of data collection through an incident notification and resolution.
- netcon server startup
- netcon client startup a. checkin with server to get configuration b. begin monitoring, periodically reporting data to server
- netcon server accepts reported data from many clients a. for each piece of data, update the 'current' state of that service b. roll previous data into 'history'
- netcon server periodically checks for errors a. load all triggers and check against 'current' state b. record any trigger state changes c. for any triggered errors, add them to the active incident, creating one if necessary
- netcon server periodically handles notifications a. iterate through active incidents, make sure currently active users are watching these incidents c. iterate over watched incidents for each user, and generate notifications (user can choose a single email, or a single email per incident) d. deactivate incidents which have been resolved and which have passed their 'watch' period without any activity.
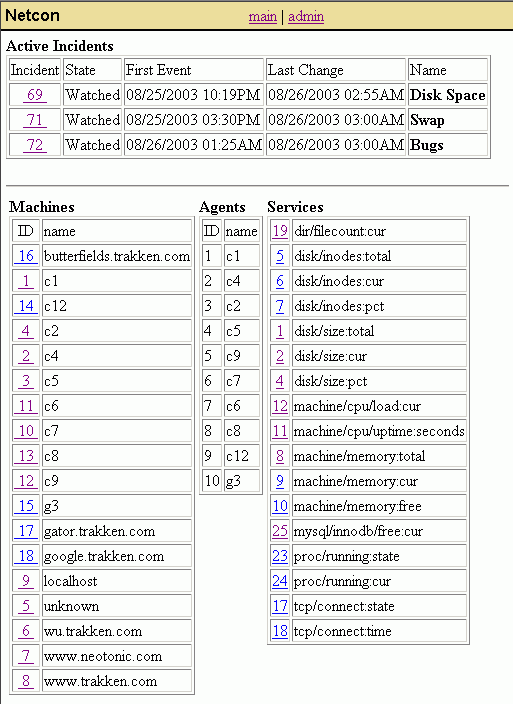
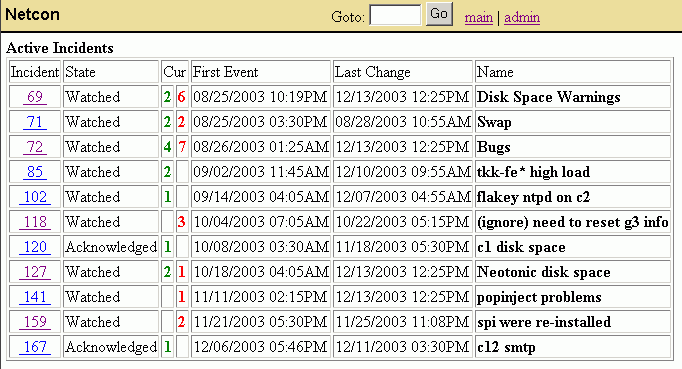
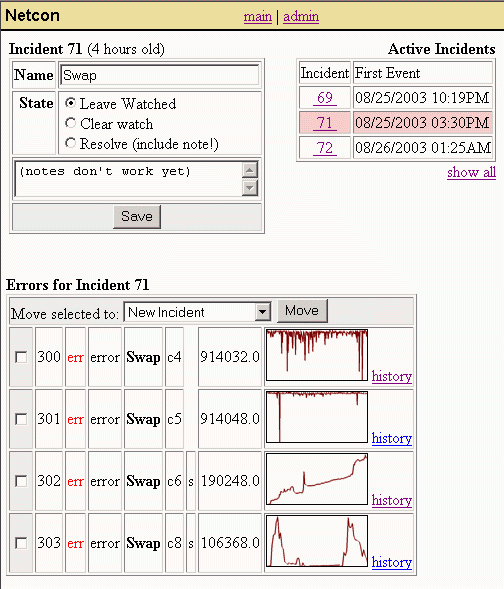
When the user receives a notification, that notification will indicate the severity of the incident, and the number of failures present on that incident. By visiting the web-interface, the user can check the detailed information reported on the incident, as well as add notes to the incident.
When the problem is resolved, the user must acknowledge and resolve the incident before it will be cleared. When acknowledging, the user can indicate the user-percieved result of the failure (degraded-performance, degraded-functionality, inaccessability), as well as the length of time this incident should be watched for. After the watch timeout has expired, Netcon will clear the incident and make it part of the incident history.
Check out the TODO.txt file!
-
QOS : a client/server data collection and error notification system. Uses raw files for data, and python for configuration. Simple web-interface for viewing current failures. No graphing.
-
NMIS : a centralized SNMP data collection server with notification and graphing based on RRDTool
-
remstats : uses client collectors and a central server with rrdtool
-
other tools based on RRDTool
http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/rrdworld/index.html