Horovod is a distributed training framework for TensorFlow. The goal of Horovod is to make distributed Deep Learning fast and easy to use.
To install Horovod:
-
Install Open MPI.
-
Install the
horovodpip package.
$ pip install horovodThis basic installation is good for laptops and for getting to know Horovod. If you're installing Horovod on a server with GPUs, read the Horovod on GPU section.
Horovod core principles are based on MPI concepts such as size, rank, local rank, allreduce, allgather and broadcast. These are best explained by example. Say we launched a training script on 4 servers, each having 4 GPUs. If we launched one copy of the script per GPU:
-
Size would be the number of processes, in this case 16.
-
Rank would be the unique process ID from 0 to 15 (size - 1).
-
Local rank would be the unique process ID within the server from 0 to 3.
-
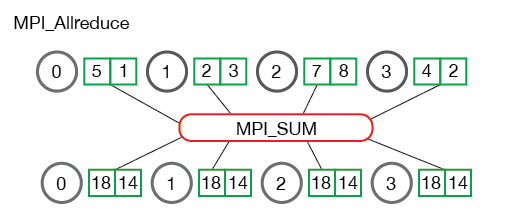
Allreduce is an operation that aggregates data among multiple processes and distributes results back to them. Allreduce is used to average dense tensors. Here's an illustration from the MPI Tutorial:
-
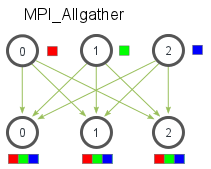
Allgather is an operation that gathers data from all processes on every process. Allgather is used to collect values of sparse tensors. Here's an illustration from the MPI Tutorial:
-
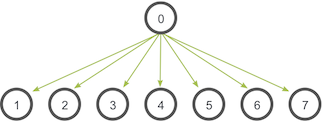
Broadcast is an operation that broadcasts data from one process, identified by root rank, onto every other process. Here's an illustration from the MPI Tutorial:
To use Horovod, make the following additions to your program:
-
Run
hvd.init(). -
Pin a server GPU to be used by this process using
config.gpu_options.visible_device_list. With the typical setup of one GPU per process, this can be set to local rank. -
Wrap optimizer in
hvd.DistributedOptimizer. The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies those averaged gradients. -
Add
hvd.BroadcastGlobalVariablesHook(0)to broadcast initial variable states from rank 0 to all other processes. Alternatively, if you're not usingMonitoredTrainingSession, you can simply execute thehvd.broadcast_global_variablesop after global variables have been initialized.
Example (full MNIST training example is available here):
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01)
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir="/tmp/train_logs",
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)To run on a machine with 4 GPUs:
$ mpirun -np 4 python train.pyTo use Horovod on GPU, read the options below and see which one applies to you best.
In most situations, using NCCL 2 will significantly improve performance over the CPU version. NCCL 2 provides the allreduce operation optimized for NVIDIA GPUs and a variety of networking devices, such as InfiniBand or RoCE.
$ HOROVOD_GPU_ALLREDUCE=NCCL pip install horovodNote: Some networks with a high computation to communication ratio benefit from doing allreduce on CPU, even if a
GPU version is available. Inception V3 is an example of such network. To force allreduce to happen on CPU, pass
device_dense='/cpu:0' to hvd.DistributedOptimizer:
opt = hvd.DistributedOptimizer(opt, device_dense='/cpu:0')GPUDirect allows GPUs to transfer memory among each other without CPU involvement, which significantly reduces latency and load on CPU. NCCL 2 is able to use GPUDirect automatically for allreduce operation if it detects it.
Additionally, Horovod uses allgather and broadcast operations from MPI. They are used for averaging sparse tensors
that are typically used for embeddings, and for broadcasting initial state. To speed these operations up with GPUDirect,
make sure your MPI implementation supports CUDA and add HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI to the pip
command.
$ HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install horovodNote: Allgather allocates an output tensor which is proportionate to the number of processes participating in the
training. If you find yourself running out of GPU memory, you can force allreduce to happen on CPU by passing
device_sparse='/cpu:0' to hvd.DistributedOptimizer:
opt = hvd.DistributedOptimizer(opt, device_sparse='/cpu:0')If you happen to have network hardware not supported by NCCL 2 or your MPI vendor's implementation on GPU is faster, you can also use the pure MPI version of allreduce, allgather and broadcast on GPU.
-
Make sure your MPI implementation is installed.
-
Install the
horovodpip package.
$ HOROVOD_GPU_ALLREDUCE=MPI HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install horovodWhat about inference? Inference may be done outside of the Python script that was used to train the model. If you do this, it will not have references to the Horovod library.
To run inference on a checkpoint generated by the Horovod-enabled training script you should optimize the graph and only keep operations necessary for a forward pass through network. The Optimize for Inference script from the TensorFlow repository will do that for you.
If you want to convert your checkpoint to Frozen Graph, you should do so after doing the optimization described above, otherwise the Freeze Graph script will fail to load Horovod op:
ValueError: No op named HorovodAllreduce in defined operations.
- Is TensorFlow installed?
If you see the error message below, it means that TensorFlow is not installed. Please install TensorFlow before installing Horovod.
error: import tensorflow failed, is it installed?
Traceback (most recent call last):
File "/tmp/pip-OfE_YX-build/setup.py", line 29, in fully_define_extension
import tensorflow as tf
ImportError: No module named tensorflow
- Are the CUDA libraries available?
If you see the error message below, it means that TensorFlow cannot be loaded. If you're installing Horovod into a container on a machine without GPUs, you may use CUDA stub drivers to work around the issue.
error: import tensorflow failed, is it installed?
Traceback (most recent call last):
File "/tmp/pip-41aCq9-build/setup.py", line 29, in fully_define_extension
import tensorflow as tf
File "/usr/local/lib/python2.7/dist-packages/tensorflow/__init__.py", line 24, in <module>
from tensorflow.python import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/__init__.py", line 49, in <module>
from tensorflow.python import pywrap_tensorflow
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 52, in <module>
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 41, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in <module>
_pywrap_tensorflow_internal = swig_import_helper()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
To use CUDA stub drivers:
# temporary add stub drivers to ld.so.cache
$ ldconfig /usr/local/cuda/lib64/stubs
# install Horovod, add other HOROVOD_* environment variables as necessary
$ pip install horovod
# revert to standard libraries
$ ldconfigIf you notice that your program is running out of GPU memory and multiple processes
are being placed on the same GPU, it's likely that your program (or its dependencies)
create a tf.Session that does not use the config that pins specific GPU.
If possible, track down the part of program that uses these additional tf.Sessions and pass
the same configuration.
Alternatively, you can place following snippet in the beginning of your program to ask TensorFlow to minimize the amount of memory it will pre-allocate on each GPU:
small_cfg = tf.ConfigProto()
small_cfg.gpu_options.allow_growth = True
with tf.Session(config=small_cfg):
passAs a last resort, you can replace setting config.gpu_options.visible_device_list
with different code:
# Pin GPU to be used
import os
os.environ['CUDA_VISIBLE_DEVICES'] = str(hvd.local_rank())Note: Setting CUDA_VISIBLE_DEVICES is incompatible with config.gpu_options.visible_device_list.
Setting CUDA_VISIBLE_DEVICES has additional disadvantage for GPU version - CUDA will not be able to use IPC, which
will likely cause NCCL and MPI and to fail. In order to disable IPC in NCCL and MPI and allow it to fallback to shared
memory, use:
export NCCL_P2P_DISABLE=1for NCCL.--mca btl_smcuda_use_cuda_ipc 0flag for OpenMPI and similar flags for other vendors.
- Gibiansky, A. (2017). Bringing HPC Techniques to Deep Learning. Retrieved from http://research.baidu.com/bringing-hpc-techniques-deep-learning/