This repository contains the "Trend Detection in Social Data" whitepaper, along with software that implements a variety of models for trend detection.
We focus on trend detection in social data times series. A time series is defined by the presence of a word, a phrase, a hashtags, a mention, or any other characteristic of a social media event that can be counted over a series of time intervals. To do trend detection, we quantify the degree to which each count in the time series is atypical. We refer to this figure of merit with the Greek letter eta, and we say that a time series and its associated topic are "trending" if the figure of merit exceeds a pre-defined threshold denoted by the Greek letter theta.
The trends whitepaper source can be found in the paper directory, which
also includes a subdirectory for figures, figs. A PDF version of the
paper is included but it is not gaurenteed to be up-to-date. A new version can
be generated from the source by running:
pdflatex paper/trends.tex
Installation of pdflatex and/or additional .sty files may be required.
The trend detection software is designed to work easily with the Gnip-Stream-Collector-Metrics package, configured to read from a Gnip PowerTrack stream. However, any time series data can be easily transformed into form useable by the scripts in this package.
- scipy
The input data can contain multiple "rules" or tags of counts, and is expected to contain data for one rule and one time interval on each line:
| end-timestamp | rule name | rule count | count for all rules | time interval duration in sec |
|---|---|---|---|---|
| 2015-01-01 00:03:25.0 | fedex | 13 | 201 | 162.0 |
| 2015-01-01 00:03:25.0 | ups | 188 | 201 | 162.0 |
| 2015-01-01 00:06:40.0 | ups | 191 | 201 | 195.0 |
| 2015-01-01 00:06:40.0 | fedex | 10 | 201 | 195.0 |
The simplest option for getting data into the correct format is to use
the Gnip-Stream-Collector-Metrics package.
With this package, you can connect to your Gnip PowerTrack stream,
and write out both the raw data and the counts of Tweets matching your rules.
This mode is configured with the following snippet in the gnip.cfg file
in Gnip-Stream-Collector-Metrics repo:
processtype=files,rules
The work is divided into three basic tasks:
- Bin choice - The original data is filtered for a specific "rule" name, and
collected into larger, even-sized bins, sized to the user's wish.
This is performed by
trends/rebin.py. - Analysis - Each data point is analyzed according to a model implemented in
the
trends/models.pyfile. Models return a figure-of-merit for each point. - Plotting - The original time series is plotted and overlaid with a plot of the eta values.
This is performed by
trends/plot.py.
All the scripts mentioned in the previous section assume the presence of a configuration
file. By default, its name is config.cfg. You can find a template at config.cfg.example.
A few parameters can be set with command-line argument. Use the scripts' -h option
for more details.
A full example has been provided in the example directory. In it, you will find
formatted time series data for mentions of the "#scotus" hashtag in August-September 2014.
This file is example/scotus.txt. In the same directory, there is a configuration file,
which specifies what the software will do, including the size of the final time buckets
and the trend detection technique and parameter values.
NOTE: be sure that your current directory is in your Python path. For example, run:
export PYTHONPATH=`pwd`
from the repository directory.
The first step to to use the "rebin" script to get appropriately and evenly sized time buckets. Let's use 2-hour buckets and put the output (which is pickled) back in the the example directory.
./trends/rebin.py -i example/scotus.txt -o example/scotus.pkl -c example/config.cfg
Use the -v option to see the raw data.
Next, we will run the analysis script, which when run alone, should return nothing. Remember, all the modeling specification is in the config file.
./trends/analyze.py -i example/scotus.pkl -c example/config.cfg
Use the -v option to see the raw data, including the results for eta.
To view results, let's run the plotting after the analysis, both of which are packaged in the plotting script:
./trends/plot.py -i example/scotus.pkl -c example/config.cfg
The output PNG should be in the example directory and look like:
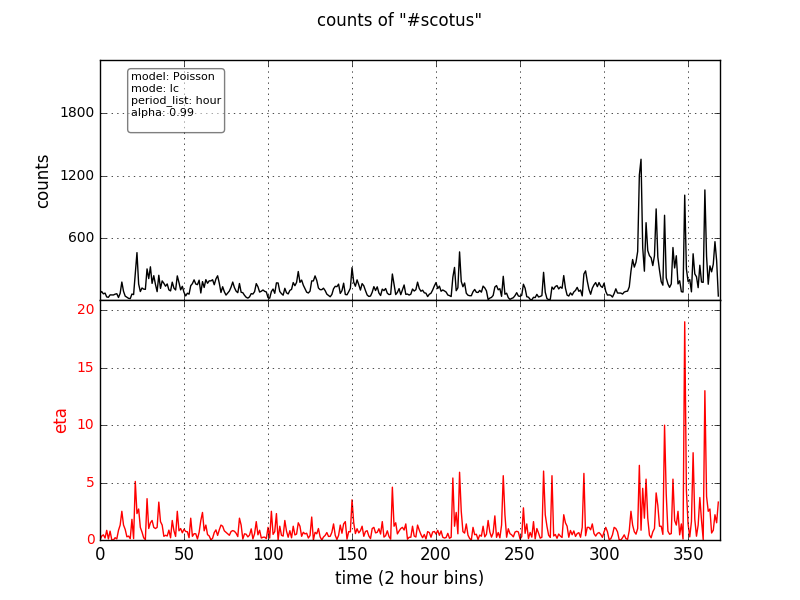
This analysis is based on the point-by-point Poisson model, with the previous point as the background expectation. You must still choose the cutoff value of eta (called theta) that defines the presence of a trend. It is clear that any choice for theta will lead to lots of false positive signals.
A more robust background model can be used by changing the mode parameter in the Poisson_model
section of the example/config.cfg from lc (last count) to a (average). The period_list
parameter determines the time interval over which the average is taken.
The output PNG should for this model should look like:
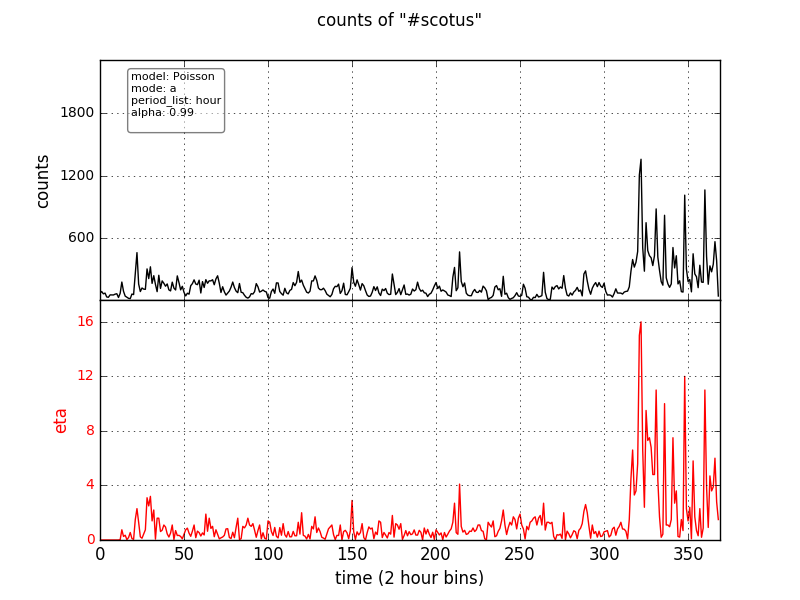
There is much less noise in this results, but we can do better. Choose the data-derived template method
in example/config.cfg by uncommenting model_name=WeightedDataTemplates. In this model, eta quantifies the
extent to which the test series looks more like a set of known trending time series or like a set of
time series known not to be trending.
The output PNG should for this model should look like:
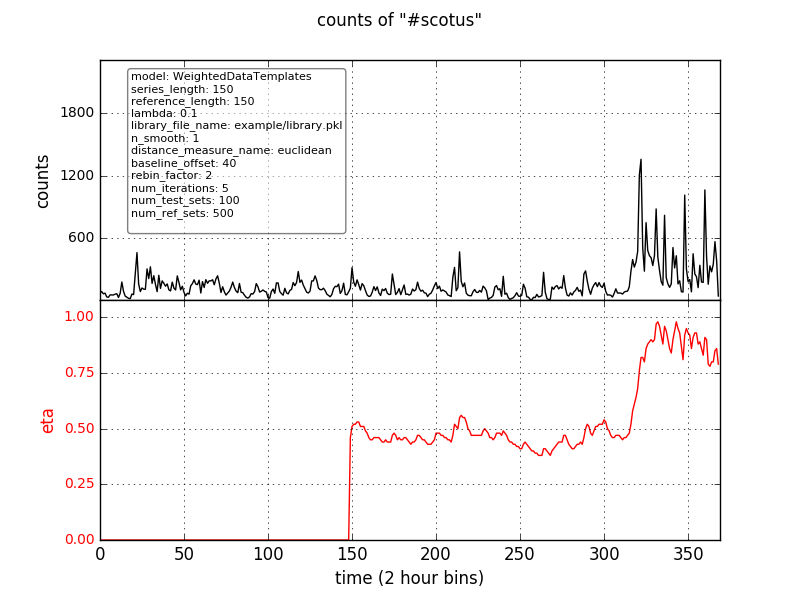
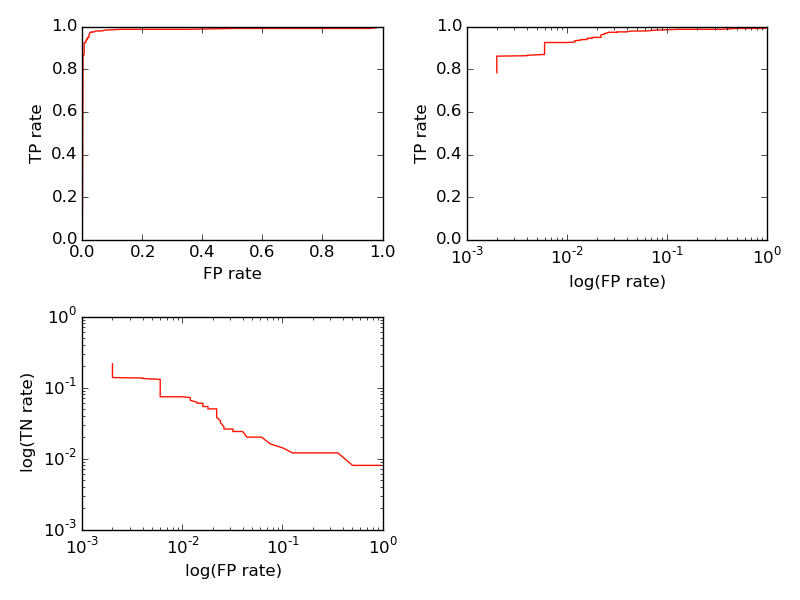
In this result, there is virtually no noise, but the eta curve lags the data because of the data smoothing procedure. Nevertheless, this model provides the most robust performance, at the cost of additional complexity and CPU time. The ROC curve for this model looks like:
The various trend detection techniques are implemented as classes in trends/models.py.
The idea is for each model to get updated point-by-point with the time series data,
and to store internally whichever data is need to calculate the figure of merit for
the latest point.
Each class must define:
- a constructor that accepts one argument, which is a dictionary containing configuration name/value pairs.
- an
updatemethod that accepts at least a keyword argument "counts", representing the latest data point to be analyzed. No return value. - a
get_resultsmethod, which takes no arguments and returns the figure of merit for the most recent update.