This is a project using live data from Twitter API, based on Kafka, Spark, Airflow and AWS. Frequency of triggering is 5mins/day.
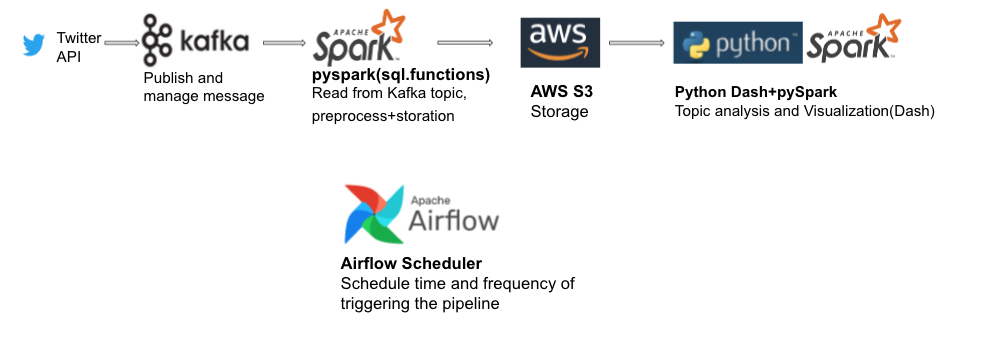


See ETL.py for code.
Because of the high frequency of access and uploading in streaming, use Delta Table storation in AWS S3.

See lda-pyspark.py for code.

Firstly find out the hyperparameter with cross validation, then pass it to full dataset with Xcom. Use sparknlp session and mlib to do LDA analysis. Result is as followed:

Visulization examples:
With pyLDAvis:
You can see the rankings of topics in all documents, and click the topic number in the left to see words in topic.

Deploy with Airflow(see dags/main.py for code)