Submissions for EE 298 - Deep Learning course
Documentation for the final project is written below.
An implementation of Autoencoding beyond pixels using a learned similarity metric using Keras. John Rufino Macasaet & Martin Roy Nabus (CoE 197-Z/EE 298)


The dataset used for the training was the cropped and aligned version of the Celeb-A Dataset. The dataset features 202,599 images with 10,177 unique identities and annotations for 5 landmark locations and 40 binary attributes per image.

The expected location of the dataset is at ../img/, i.e. the folder containing the code should be in the same directory as the folder containing the images.
To start the training:
python3 vae_gan.py
To resume training from a previous training instance:
python3 vae_gan.py continue
The model weights files (encoder, decoder, discriminator) must be on the same directory as their corresponding Python code for the continuation of the training to work. For example, the default names for the weights files of vae_gan.py are vae_gan_enc.h5, vae_gan_dec.h5, and vae_gan_disc.h5. Run details such as number of epochs and checkpointing are handled by editing code variables manually.
To test the model generated by the VAE-GAN:
python3 vae_gan.py test
The encoder & decoder weights files must be on the same directory as the Python code for this to work
To generate images from noise:
python3 vae_gan.py generate
For this case, only the corresponding decoder weights file is needed.
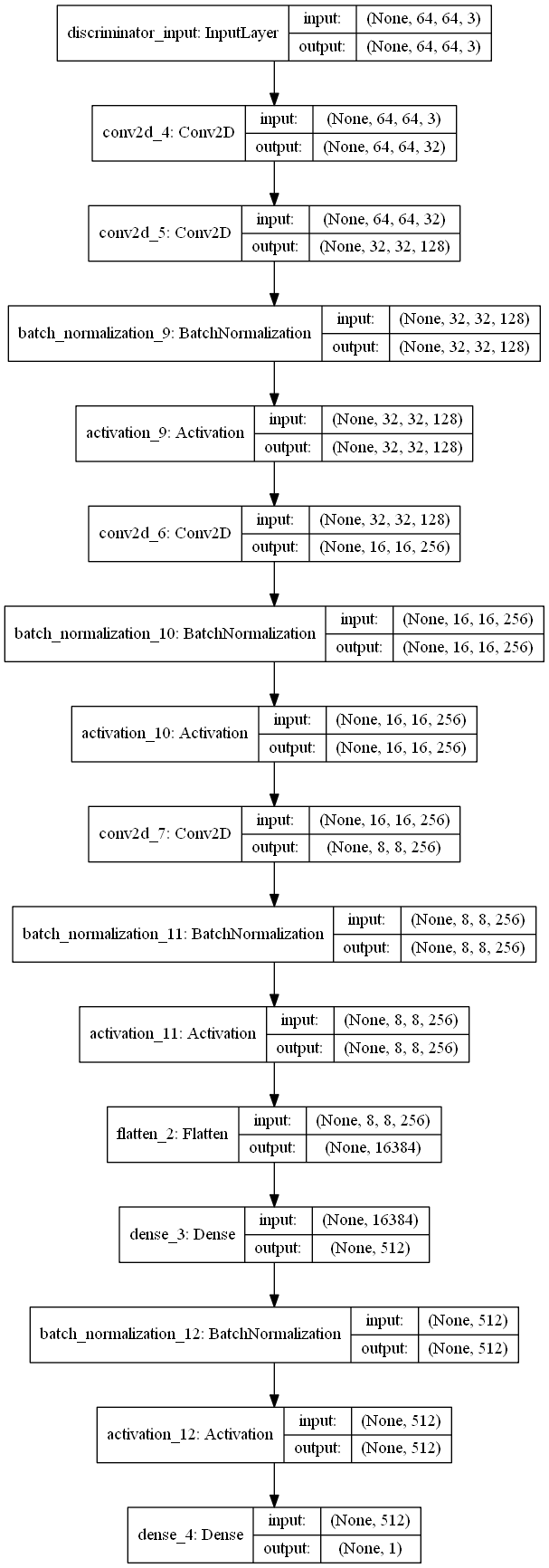
Following the recommendations of the paper regarding the architecture of the encoder, decoder/generator, and discriminator, some of the images obtained from the trained models are shown below.

Unfortunately, the models following the recommended GAN architecture did not yield face images. While models with a few epochs of training did show varying generated images, models with extended training (2000+ epochs) eventually ended up generating a single image over and over again. The code for training the model is in the folder gan_cnn, alongside two saved models. To test the generated models, run gan_test.py name_of_model; replace name_of_model with whichever model you wish to use to generate images.
The failure of the GAN to work on its own may have caused the combined model to fail. Regardless, a copy of the code can be found in the folder vae_gan_original for your perusal.
To address the non-functionality of the combined model, the discriminator was modified:
- LeakyReLU was used instead of ReLU, and Dropout was added
- This modified discriminator uses Conv-LeakyReLU-Dropout-BNorm instead of Conv-BNorm-ReLU
- The Lth layer was entirely removed from the model; instead of relying from the Lth layer information to train the encoder and decoder, the actual image info was used instead.
An image of the modified discriminator is shown below.
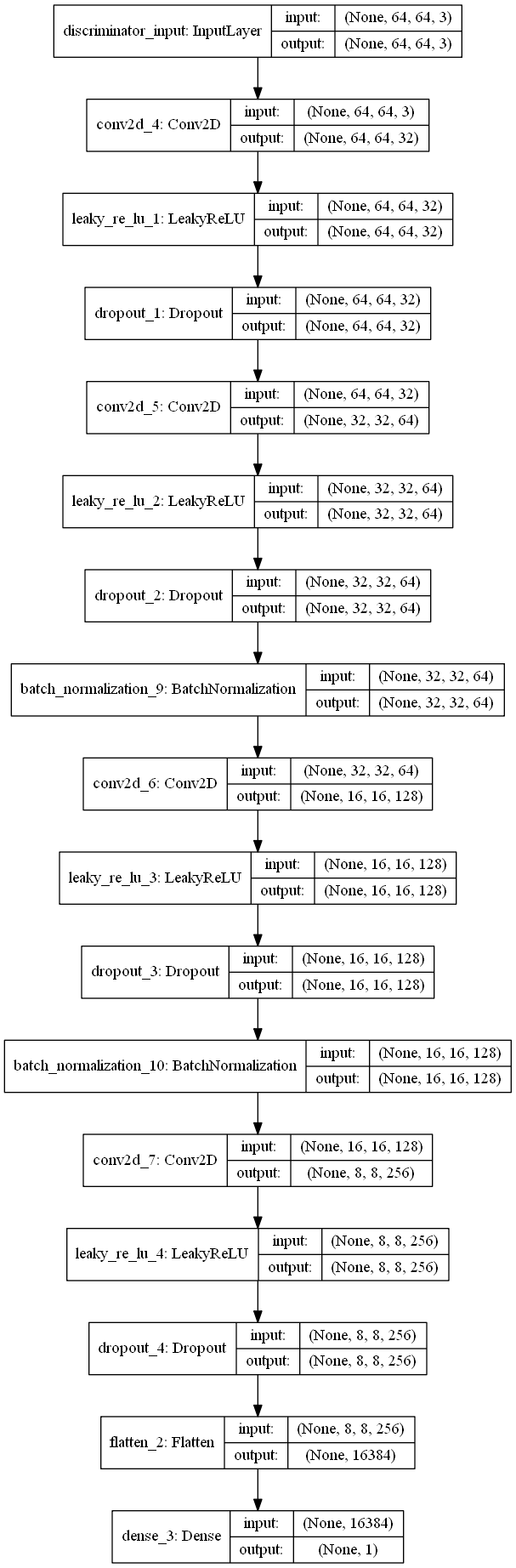
Using the modified discriminator, three models were created: a VAE-GAN, a Conditional VAE-GAN based on the attribute vectors on list_attr_celeba.txt, and a query-to-image VAE-GAN that accepts an attribute vector and outputs an image corresponding to that vector. Take note that for codes that use attribute vector data, list_attr_celeba.txt should be in the same directory as the img folder (not inside it).

The images below are results of slightly altering the images' corresponding attribute vectors; for example, under the "Bald" category, Bald is set to 1 while all other hair attributes are set to -1.


Overall, the results were not as good as hoped, but it is evident that some features still carry over the reconstructions; this can also be seen with the labels affecting the resulting images.
- While training on the deep learning machines provided, we noticed that the machines were not configured to use
tensorflow-gpu(i.e. it cannot access NVIDIA cuDNN). This hampered our capability to perform more tests. - Some configurations in the model's architecture were not mentioned on the paper; one of the most crucial examples is how the encoder's reparameterization network is defined. This may have affected our original implementation.
- Using LeakyReLU seems to be more effective than using plain ReLU, as shown by the results in our experiments and in other groups' experiments.