Research Scraper is an academic paper manage tool based on google scholar. It aims to add one more layer beyond google scholar, make things easier for in-school research group management.
Basically a research group is a set of authors, and each author have a lot of papers, the pain point is : as a group, it not easy to manage those papers related to your group topic, because you never know the paper (wroten by an author inside this group) is for the group, or just for fun. Google Scholar just collect all the papers either by authors or by topics, it's really hard to gather all the papers together and make sure they are all related to current group. That's where the tool comes.
-
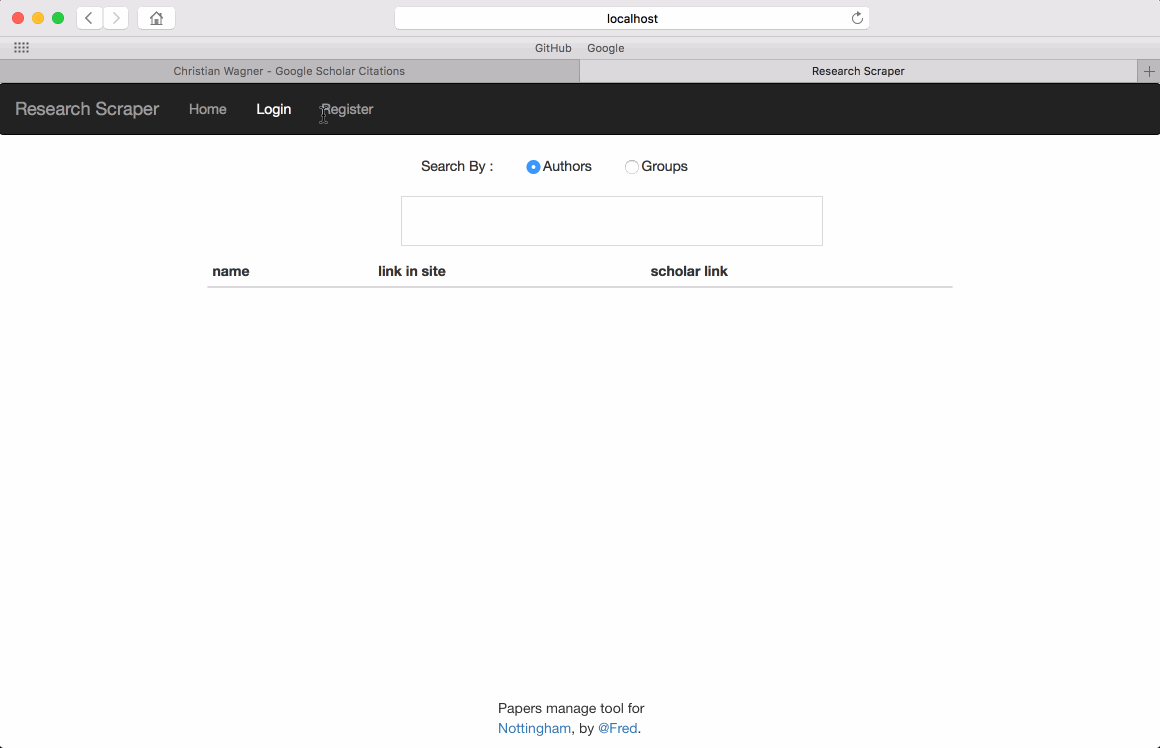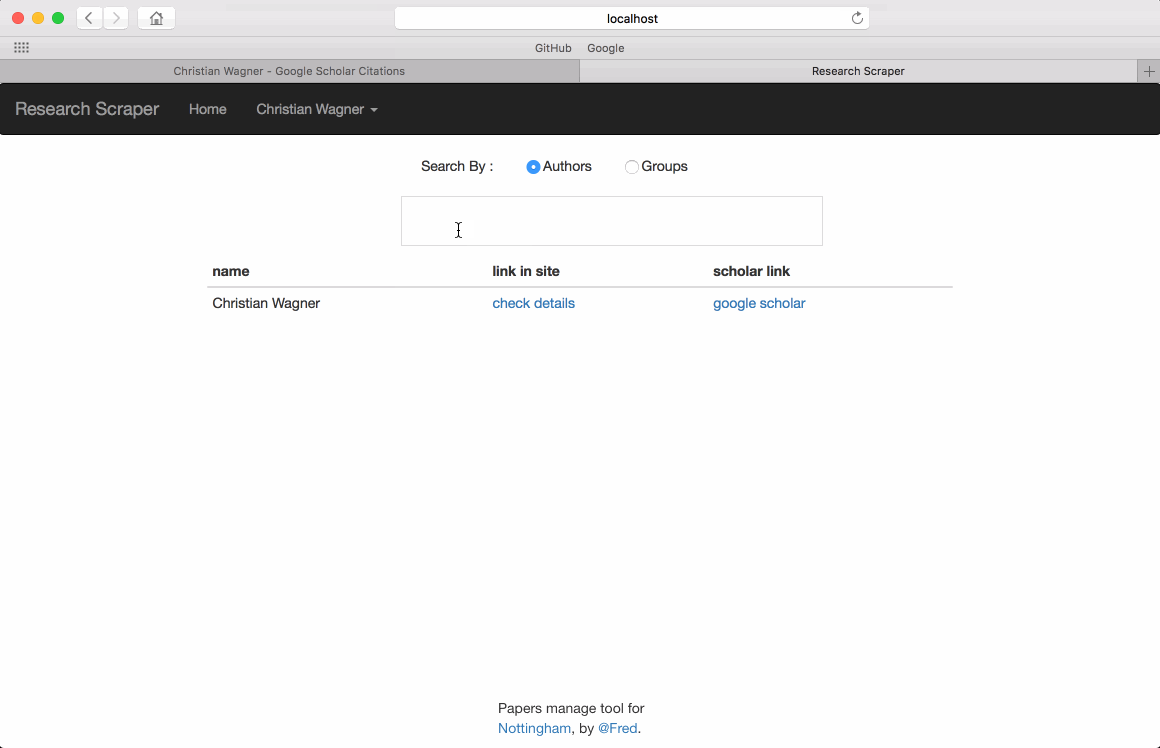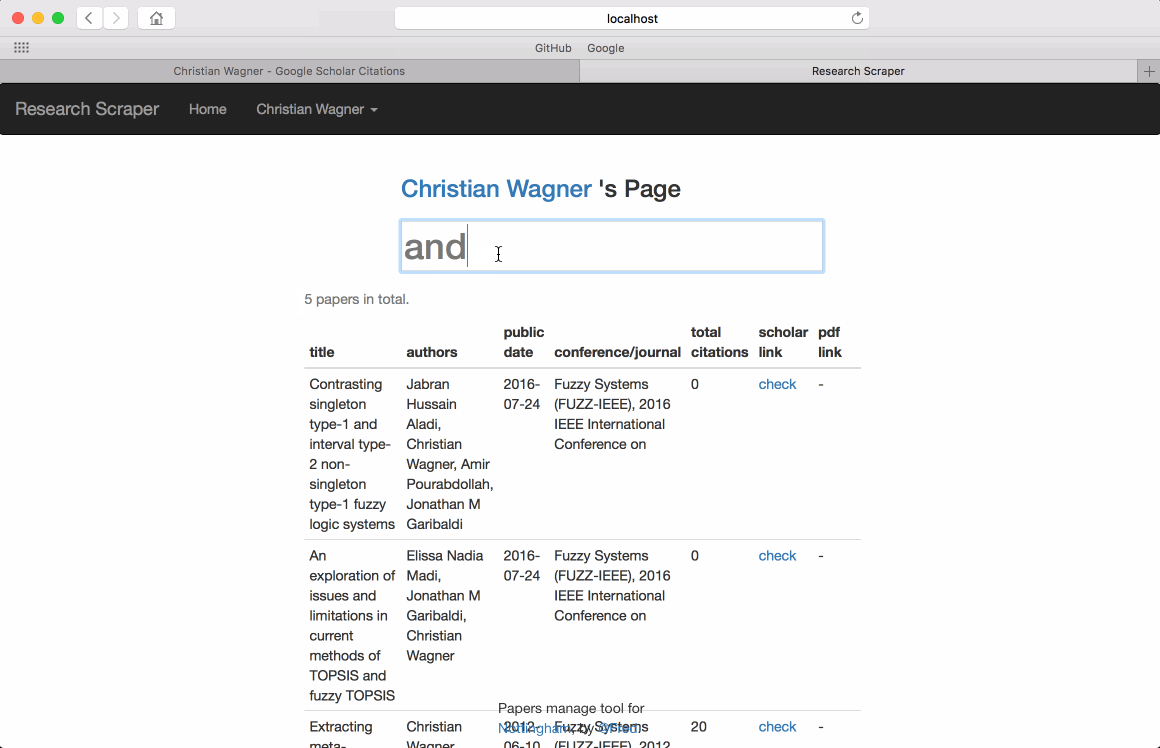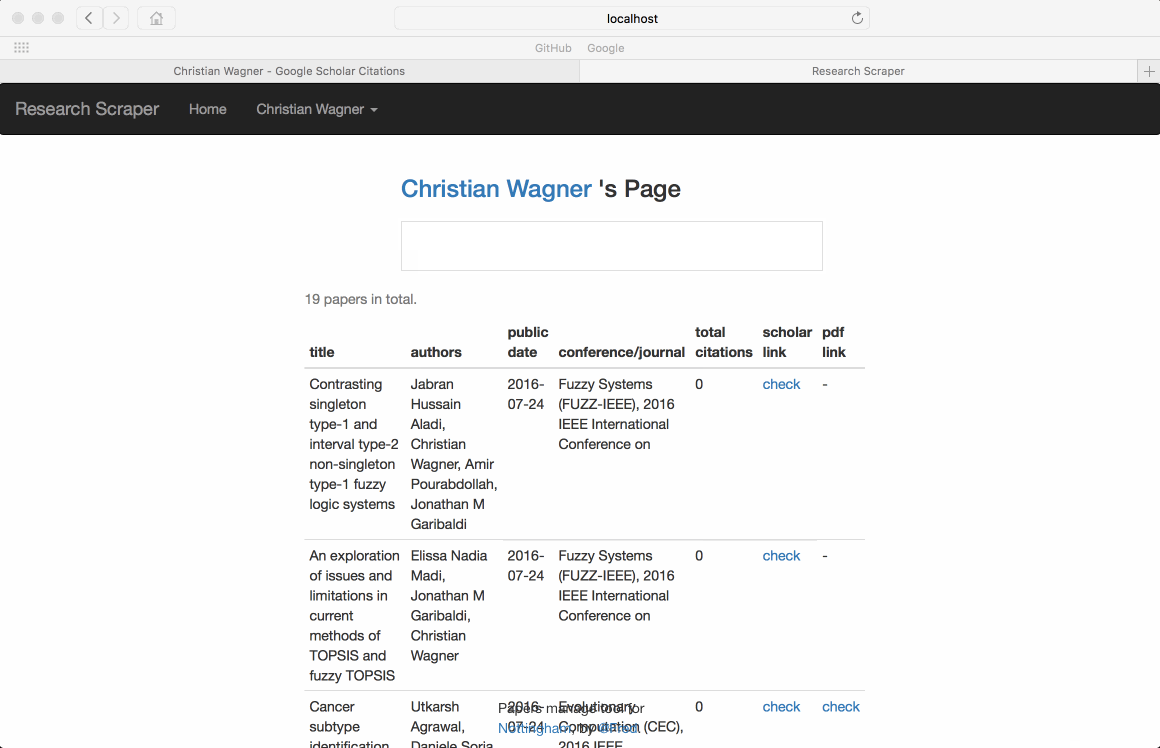
Register as an author, the most important bit is to type in the correct google scholar address since it will be used as the start point of the paper crawler. There are several point to make sure :
https://scholar.google.com/citations?user=tAQTJRIAAAAJ&hl=en: this is a correct format.https://scholar.google.com/citations?user=tAQTJRIAAAAJ&hl=en&cstart=20&pagesize=20: This one contains start page and pagesize, it will confuse the crawler.https://scholar.google.com/citations?user=tAQTJRIAAAAJ&hl=CN: the language specify in the url must be English. Herehl=CNis used, it will make the page loaded by crawler show as Chinese.
-
Once you finish register, the server will fork a subprocess to crawl all the papers from google, the time to finish crawl depends on the number of your paper. Usually won't longer than 15 minutes. So what we currently get is like a complete copy of your papers from google.
-
Once you login successful, you will find your name is shown at the navigation bar. And your name is also a drop-down button, then clikc 'Group' to manage your group. There are no maigic in group creating process, just choose the author and type in group description etc. After create the group, the creator will automatically be the manager inside the group. Then you are done, and now you can check the group paper list. The basic process of the system to find papers is :
- find all authors in the group
- for each author, find the papers
- remove the duplicate (imagine a paper wroten by two authors, both are in the group)
-
There is another problem, only part of the authors papers should be related to a specific group. For example, author A joined group G after 2010, but google just collect all the papers about A, but people may not want to check those unrelated papers wroten by A before 2010. So we came up with a new idea, filter. Filter is group level which make sure you can customize different filter for different group. Currently we only implement date filter, which means you can set
before dateandafter dateto speicify the papers you want to show in the group. All the papers outside this period will be hidden. To make it accurate, you can manually hide/unhide a paper to do minor change after the date filter.
- Mysql >= 5.5.3 : the encoding utf8mb4 is supported after 5.5.3 .
- Python 3.x : we also need some necessary modules
- Scrapy : the python crawler framework.
- Flask : the python web framework.
- PyMySQL : the mysql client library for python 3.x
- git clone source code
- cd Research-Scraper && python3 run.py
The project is basically a web application with some web crawlers involved. To make it as extensiable as possible, I split the actual data interface and the web view. All the data (include authors, groups and papers) are sent from the RESTful API interface, check the nottingham/blueprints. So the basic data flow of the project is :
- request from browser
- server send dynamic html back (no data)
- js run in browser and send ajax back request data
- data as json format is returned
So you will find it's possible to plugin the function into your own webside since those API are all public, what you need to do is send the request used required format, then you will get the data back. How to display the data is completely on your own. The concrete API useage is inside the source file nottingham/blueprints/*.