CudaTree is an implementation of Leo Breiman's Random Forests adapted to run on the GPU. A random forest is an ensemble of randomized decision trees which vote together to predict new labels. CudaTree parallelizes the construction of each individual tree in the ensemble and thus is able to train faster than the latest version of scikits-learn.
And we've implemented a hybrid version of random forest which uses both GPU and multicore CPU. For the multicore version, we use scikits-learn random forest as default, you can also supply other multicore implementations such as WiseRF.
import numpy as np
from cudatree import load_data, RandomForestClassifier
x_train, y_train = load_data("digits")
forest = RandomForestClassifier(n_estimators=50, verbose=True, bootstrap=False)
forest.fit(x_train, y_train, bfs_threshold=1024)
forest.predict(x_train)For hybrid version:
import numpy as np
from cudatree import load_data
from hybridforest import RandomForestClassifier
from PyWiseRF import WiseRF
x_train, y_train = load_data("digits")
#Cuda tree uses one core and WiseRF will use other 5 cores.
forest = RandomForestClassifier(n_estimators=50, n_jobs = 6, bootstrap=False, cpu_classifier = WiseRF)
forest.fit(x_train, y_train, bfs_threshold=1024)
forest.predict(x_train)You should be able to install CudaTree from its PyPI package by running:
pip install cudatree
CudaTree is writen for Python 2.7 and depends on:
It's important to remember that a dataset which fits into your computer's main memory may not necessarily fit on a GPU's smaller memory. Furthermore, CudaTree uses several temporary arrays during tree construction which will limit how much space is available. A formula for the total number of bytes required to fit a decision tree for a given dataset is given below. If less than this quantity is available on your GPU, then CudaTree will fail.
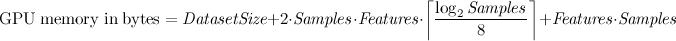{kind=link}
For example, let's assume you have a training dataset which takes up 200MB, and the number of samples = 10000 and
the number of features is 3000, then the total GPU memory required will be:
In addition to memory requirement, there are several other limitations hard-coded into CudaTree:
- The maximum number of features allowed is 65,536.
- The maximum number of categories allowed is 5000(CudaTree performs best when the number of categories is <=100).
- Your NVIDIA GPU must have compute capability >= 1.3.
- Currently, the only splitting criterion is GINI impurity, which means CudaTree can't yet do regression (splitting by variance for continuous outputs is planned)
The performance gain over scikits-learn is typically about 1.5X ~ 5X, though the exact number depends on how powerful your GPU is and what your training data looks like.
Trees are first constructed in depth-first order, with a separate kernel launch for each node's subset of the data. Eventually the data gets split into very small subsets and at that point CudaTree switches to breadth-first grouping of multiple subsets for each kernel launch.