{kind=link}
This is a Speaker Recognition system with GUI.
- Windows: Anaconda with Python 2.7
- scikit-learn (included in Anaconda2)
- scikits.talkbox (on windows, it needs a VC++ compiler, download "VCForPython27.msi"!)
- pyssp (command: pip install pyssp)
- PyQt4 (not needed on windows, as included in Anaconda2)
- PyAudio (prerequisite on Linux: sudo apt-get install portaudio19-dev)
- (Optional)Python bindings for bob:
- install blitz, openblas, boost
pip install --user bob.extension bob.blitz bob.core bob.sp bob.ap
Note: We have a MFCC implementation on our own which will be used as a fallback when bob is unavailable. But it's not so efficient as the C implementation in bob.
Run make -C src/gmm to compile our fast gmm implementation. Require gcc >= 4.7.
It will be used as default, if successfully compiled.
For more details of this project, please see:
- Our presentation slides
- Our complete report
Voice Activity Detection(VAD):
Feature:
Model:
- Gaussian Mixture Model (GMM)
- Universal Background Model (UBM)
- Continuous Restricted Boltzman Machine (CRBM)
- Joint Factor Analysis (JFA)
usage: speaker-recognition.py [-h] -t TASK -i INPUT -m MODEL
Speaker Recognition Command Line Tool
optional arguments:
-h, --help show this help message and exit
-t TASK, --task TASK Task to do. Either "enroll" or "predict"
-i INPUT, --input INPUT
Input Files(to predict) or Directories(to enroll)
-m MODEL, --model MODEL
Model file to save(in enroll) or use(in predict)
Wav files in each input directory will be labeled as the basename of the directory.
Note that wildcard inputs should be *quoted*, and they will be sent to glob module.
Examples:
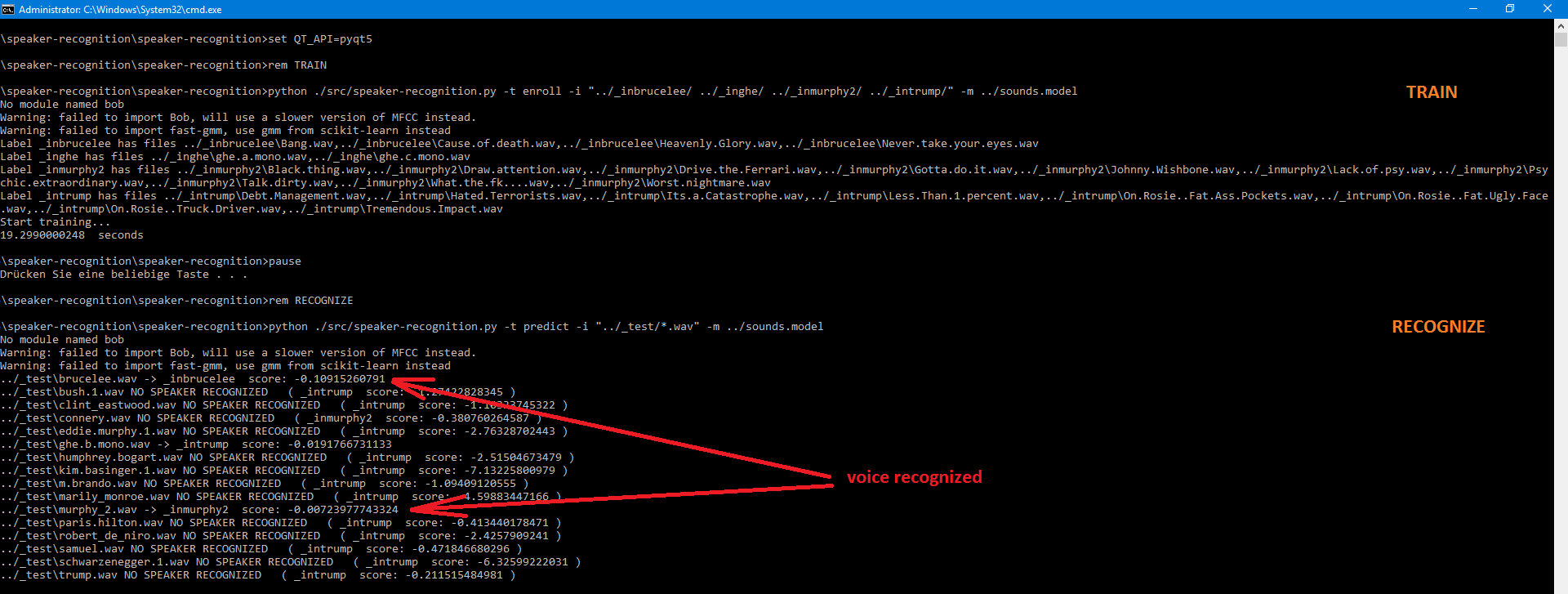
Train:
./speaker-recognition.py -t enroll -i "./bob/ ./mary/ ./person*" -m model.out
Predict:
./speaker-recognition.py -t predict -i "./*.wav" -m model.outSee 'run.bat'
Our GUI not only has basic functionality for recording, enrollment, training and testing, but also has a visualization of real-time speaker recognition:

You can See our demo video (in Chinese). Note that real-time speaker recognition is extremely hard, because we only use corpus of about 1 second length to identify the speaker. Therefore the real-time system doesn't work very perfect. Also the GUI part is quite hacky for demo purpose and may not work as smoothly as expected.