def test_assign_arrays_raise_error():
foo = Embedding("foo", [0.1, 0.3, 0.10])
bar = Embedding("bar", [0.7, 0.2, 0.11])
emb = EmbeddingSet(foo, bar)
with pytest.raises(ValueError):
emb_with_property = emb.assign(prop_a=["a", "b"],
prop_b=np.array([1, 2, 3]))
def test_assign_literal_values():
foo = Embedding("foo", [0.1, 0.3, 0.10])
bar = Embedding("bar", [0.7, 0.2, 0.11])
emb = EmbeddingSet(foo, bar)
emb_with_property = emb.assign(prop_a="prop-one", prop_b=1)
assert all([e.prop_a == "prop-one" for e in emb_with_property])
assert all([e.prop_b == 1 for e in emb_with_property])
def test_assign():
foo = Embedding("foo", [0.1, 0.3, 0.10])
bar = Embedding("bar", [0.7, 0.2, 0.11])
emb = EmbeddingSet(foo, bar)
emb_with_property = emb.assign(prop_a=lambda d: "prop-one",
prop_b=lambda d: "prop-two")
assert all([e.prop_a == "prop-one" for e in emb_with_property])
assert all([e.prop_b == "prop-two" for e in emb_with_property])
def test_assign_arrays():
foo = Embedding("foo", [0.1, 0.3, 0.10])
bar = Embedding("bar", [0.7, 0.2, 0.11])
emb = EmbeddingSet(foo, bar)
emb_with_property = emb.assign(prop_a=["a", "b"], prop_b=np.array([1, 2]))
assert emb_with_property["foo"].prop_a == "a"
assert emb_with_property["bar"].prop_a == "b"
assert emb_with_property["foo"].prop_b == 1
assert emb_with_property["bar"].prop_b == 2
def test_to_x_y():
foo = Embedding("foo", [0.1, 0.3])
bar = Embedding("bar", [0.7, 0.2])
buz = Embedding("buz", [0.1, 0.9])
bla = Embedding("bla", [0.2, 0.8])
emb1 = EmbeddingSet(foo, bar).add_property("label", lambda d: 'group-one')
emb2 = EmbeddingSet(buz, bla).add_property("label", lambda d: 'group-two')
emb = emb1.merge(emb2)
X, y = emb.to_X_y(y_label='label')
assert X.shape == emb.to_X().shape == (4, 2)
assert list(y) == ['group-one', 'group-one', 'group-two', 'group-two']
def test_embeddingset_creation():
foo = Embedding("foo", [0, 1])
bar = Embedding("bar", [1, 1])
emb = EmbeddingSet(foo)
assert len(emb) == 1
assert "foo" in emb
emb = EmbeddingSet(foo, bar)
assert len(emb) == 2
assert "foo" in emb
assert "bar" in emb
emb = EmbeddingSet({"foo": foo})
assert len(emb) == 1
assert "foo" in emb
def embset():
names = ["red", "blue", "green", "yellow", "white"]
vectors = np.random.rand(5, 4) * 10 - 5
embeddings = [
Embedding(name, vector) for name, vector in zip(names, vectors)
]
return EmbeddingSet(*embeddings)
def transform(self, embset):
names, X = embset.to_names_X()
np.random.seed(self.seed)
orig_dict = embset.embeddings.copy()
new_dict = {
f"rand_{k}": Embedding(f"rand_{k}",
np.random.normal(0, self.sigma, X.shape[1]))
for k in range(self.n)
}
return EmbeddingSet({**orig_dict, **new_dict})
def new_embedding_dict(names_new, vectors_new, old_embset):
new_embeddings = {}
for k, v in zip(names_new, vectors_new):
new_emb = (deepcopy(old_embset[k])
if k in old_embset.embeddings.keys() else Embedding(
k, v, orig=k))
new_emb.name = k
new_emb.vector = v
new_embeddings[k] = new_emb
return new_embeddings
def reverse_strings(embset):
"""
This helper will reverse the strings in the embeddingset. This can be useful
for making matplotlib plots with Arabic texts.
This helper is meant to be used via `EmbeddingSet.pipe()`.
Arguments:
embset: EmbeddingSet to adapt
Usage:
```python
from whatlies.helpers import reverse_strings
from whatlies.language import BytePairLanguage
translation = {
"man":"رجل",
"woman":"امرأة",
"king":"ملك",
"queen":"ملكة",
"brother":"أخ",
"sister":"أخت",
"cat":"قطة",
"dog":"كلب",
"lion":"أسد",
"puppy":"جرو",
"male student":"طالب",
"female student":"طالبة",
"university":"جامعة",
"school":"مدرسة",
"kitten":" قطة صغيرة",
"apple" : "تفاحة",
"orange" : "برتقال",
"cabbage" : "كرنب",
"carrot" : "جزرة"
}
lang_cv = BytePairLanguage("ar")
arabic_words = list(words.values())
# before
lang_cv[translation].plot_similarity()
# after
lang_cv[translation].pipe(reverse_strings).plot_similarity()
```
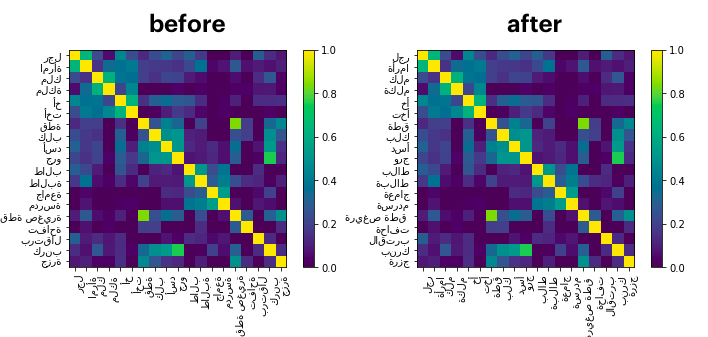
"""
return EmbeddingSet(
*[Embedding(name=e.name[::-1], vector=e.vector) for e in embset])
def __getitem__(self, item):
"""
Retreive a single embedding or a set of embeddings. If an embedding contains multiple
sub-tokens then we'll average them before retreival.
Arguments:
item: single string or list of strings
**Usage**
```python
> lang = BytePairLang(lang="en")
> lang['python']
> lang[['python', 'snake']]
> lang[['nobody expects', 'the spanish inquisition']]
```
"""
if isinstance(item, str):
return Embedding(item, self.module.embed(item).mean(axis=0))
if isinstance(item, list):
return EmbeddingSet(*[self[i] for i in item])
raise ValueError(f"Item must be list of string got {item}.")
def test_reverse_strings():
embset = EmbeddingSet(Embedding(name="helloworld",
vector=[1, 2])).pipe(reverse_strings)
emb = [e for e in embset][0]
assert emb.name == "dlrowolleh"
def test_negation():
foo = Embedding("foo", [0.1, 0.3])
assert np.allclose((-foo).vector, -np.array([0.1, 0.3]))
def test_emb_plot_no_err_3d():
x = Embedding("x", [0.0, 1.0, 1.0])
y = Embedding("y", [1.0, 0.0, 1.0])
z = Embedding("z", [0.5, 0.5, 1.0])
for item in [x, y, z]:
item.plot("scatter", x_axis=x, y_axis=y)
def emb():
x = Embedding("x", [0.0, 1.0])
y = Embedding("y", [1.0, 0.0])
z = Embedding("z", [0.5, 0.5])
return EmbeddingSet(x, y, z)
st.markdown("# Simple Text Clustering")
st.markdown(
"Let's say you've gotten a lot of feedback from clients on different channels. You might like to be able to distill main topics and get an overview. It might even inspire some intents that will be used in a virtual assistant!"
)
st.markdown(
"This tool will help you discover them. This app will attempt to cluster whatever text you give it. The chart will try to clump text together and you can explore underlying patterns."
)
if method == "CountVector SVD":
lang = CountVectorLanguage(n_svd, ngram_range=(min_ngram, max_ngram))
embset = lang[texts]
if method == "Lite Sentence Encoding":
embset = EmbeddingSet(
*[
Embedding(t, v)
for t, v in zip(texts, calculate_embeddings(texts, encodings=encodings))
]
)
p = (
embset.transform(reduction)
.plot_interactive(annot=False)
.properties(width=500, height=500, title="")
)
st.write(p)
st.markdown(
"While the tool helps you in discovering clusters, it doesn't do labelling (yet). We do offer a [jupyter notebook](https://github.com/RasaHQ/rasalit/tree/master/notebooks/bulk-labelling) that might help out though."
)
def test_emb_ndim():
foo = Embedding("foo", [0, 1, 0.2])
assert foo.ndim == 3
)
reduction = Umap(2, n_neighbors=n_neighbors, min_dist=min_dist)
else:
reduction = Pca(2)
st.markdown("# Simple Text Clustering")
st.markdown(
"Let's say you've gotten a lot of feedback from clients on different channels. You might like to be able to distill main topics and get an overview. It might even inspire some intents that will be used in a virtual assistant!"
)
st.markdown(
"This tool will help you discover them. This app will attempt to cluster whatever text you give it. The chart will try to clump text together and you can explore underlying patterns."
)
if method == "CountVector SVD":
lang = CountVectorLanguage(n_svd, ngram_range=(min_ngram, max_ngram))
embset = lang[texts]
if method == "Lite Sentence Encoding":
embset = EmbeddingSet(*[
Embedding(t, v) for t, v in zip(
texts, calculate_embeddings(texts, encodings=encodings))
])
p = (embset.transform(reduction).plot_interactive(annot=False).properties(
width=500, height=500, title=""))
st.write(p)
st.markdown(
"While the tool helps you in discovering clusters, it doesn't do labelling (yet). We do offer a [jupyter notebook](https://github.com/RasaHQ/rasalit/tree/master/notebooks/bulk-labelling) that might help out though."
)
def test_embset_creation_warning():
foo = Embedding("foo", [0, 1])
# This vector has the same name dimension. Dangerzone.
bar = Embedding("foo", [1, 2])
with pytest.raises(Warning):
EmbeddingSet(foo, bar)
def test_embset_creation_error():
foo = Embedding("foo", [0, 1])
# This vector has a different dimension. No bueno.
bar = Embedding("bar", [1, 1, 2])
with pytest.raises(ValueError):
EmbeddingSet(foo, bar)
def __getitem__(self, query):
if isinstance(query, str):
return Embedding(query, vector=self.model.encode(query))
else:
return EmbeddingSet(*[self[tok] for tok in query])
def test_add_property():
foo = Embedding("foo", [0.1, 0.3, 0.10])
bar = Embedding("bar", [0.7, 0.2, 0.11])
emb = EmbeddingSet(foo, bar)
emb_with_property = emb.add_property("prop_a", lambda d: "prop-one")
assert all([e.prop_a == "prop-one" for e in emb_with_property])
